I am thrilled to formally introduce Mindbeam as we emerge from stealth.
We have built the fastest AI training framework to date, achieving groundbreaking performance benchmarks and an 86% reduction in energy
consumption.
This milestone reflects our core mission to accelerate the future of AI while significantly reducing the environmental impact of large-scale model training.
We are proud to be working closely with the amazing team at @awscloud to deploy this amazing product to thousands of customers across AI research labs and Fortune 100 Enterprises.
Our flagship product, Litespark, is now available on the AWS Marketplace. Visit https://t.co/1hmIeJsQr7 to learn more.
🚀 BREAKING: We just revolutionized AI pre-training
We are excited to come out of stealth and launch our revolutionary product: Litespark, a language model framework which utilizes advanced algorithms to speed up training and inference workloads for generative AI applications.
Litespark reduces training time from months to days.
With just 16 H100s, you can train your own billion-parameter foundation model from scratch in 26 hours. Fortune 100 companies are already transforming their AI workflows with our breakthrough framework on AWS.
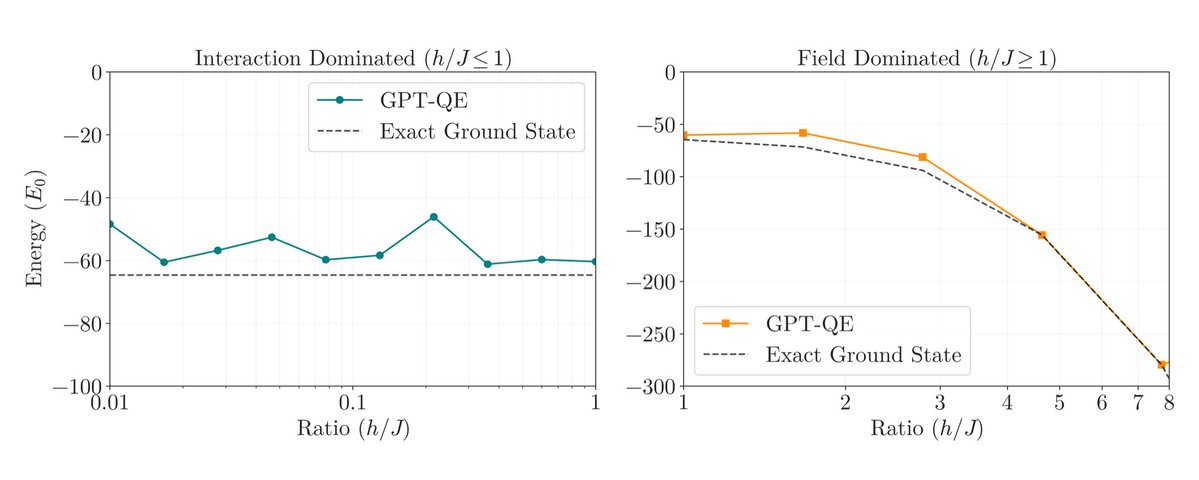
Stress test across different physics regimes: from highly entangled, frustrated quantum states (left) to simple aligned spins (right). Our method nails the ground state energy across the board—no manual tuning for different problems. That's the power of learned circuit design.
We are thrilled to share our latest innovation, SpinGQE, a generative quantum eingensolver for spin hamiltonians.
Ground state search is fundamental to quantum computing but VQE suffers from barren plateaus and limited expressivity.
In our solution, we reframe circuit design as generative modelling where a transformer learns distributions over quantum circuits by matching logits to energies at each gate subsequence.
Paper: https://t.co/c1YzkzDTMn
Code: https://t.co/RX6L2rc4IX
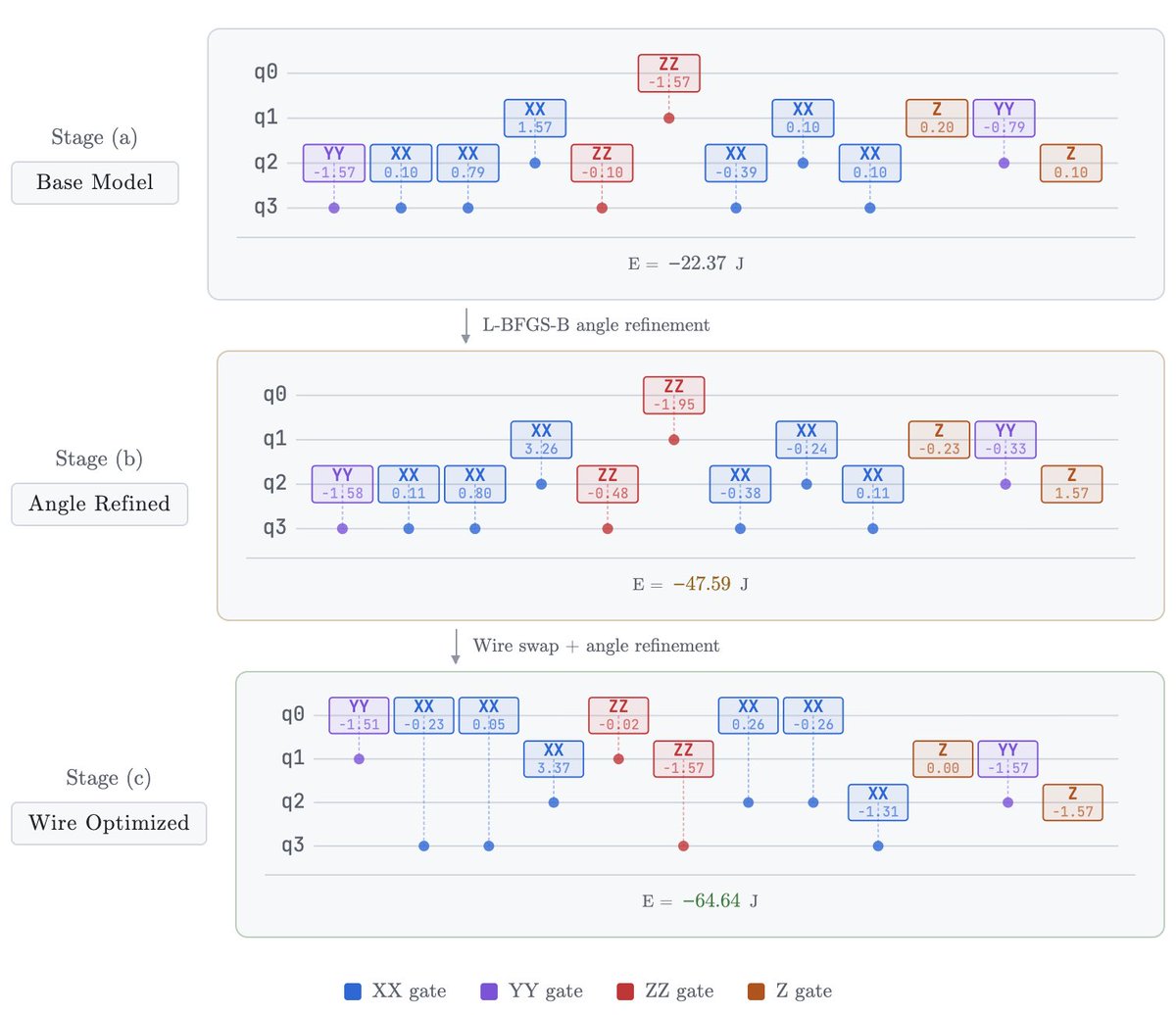
Watch a quantum circuit evolve from rough sketch to precision instrument. The AI generates an initial circuit (left), continuous optimization tunes the angles (middle), then smart rewiring unlocks the right connections (right)—dropping energy from -22 to -64 (near-perfect!).
Announcing our Litespark Technical Report! 🚀
Mindbeam Litespark boosts LLM training up to 6x faster & cuts energy use by 83%.
Works with any transformer architecture. Smarter, greener AI is here.
Dive into the details: https://t.co/2ex262J89s
🚀 Proud moment alert! AWS Startups just spotlighted our founder, Nii Osae, sharing how enterprise teams can turbocharge pre-training models by 6x, reducing training time from months to days.
Check out how Mindbeam Litespark transforms AI development—now available on the AWS Marketplace. Get started: https://t.co/OasdCx5vkb
💡 @MindbeamAI helps Fortune 500 companies pre-train LLMs on #AWS. We caught up with Nii Osae, the company’s Founder & CEO, at the AWS NYC Summit to learn more about the future of #AI infrastructure.
Find us at AWS Summit LA to connect. 🚀 https://t.co/DKRj4Tc0nd
Super excited to share @MindbeamAI Litespark record-breaking benchmarks!
With Litespark, you can train a 3 billion-parameter model with 16 H200 GPUs in less than 2 days, reducing training costs from millions of dollars to under $20K.
Bigger models experience improved performance up to 6x in training speed!
This marks an inflection point in AI model training and we are happy to share this with the world. 🚀🚀🚀
Litespark is bringing unprecedented training speed and performance to Generative AI.
These benchmarks are redefining the status quo and unlocking new potentials for AI infrastructure.🚀
The first AGI system will be much worse than previous AI systems at pretty much everything -- except for tests that focus on measuring general intelligence (e.g. ARC).
Like a baby, it will be generally intelligent -- able to learn efficiently and adapt -- but will lack any specialized competence.
However, it will be able to learn using much less data, and the capabilities it picks up will generalize much more strongly to the variability and unpredictability of the real world. As a result, after a few years, it will beat previous AI systems at absolutely everything -- including many problems that were completely out of reach before.
Comprehensive and deeply insightful, "A History of Bodies, Brains, and Minds" provides a brief history of life, the brain, and cognition, from the earliest living beings to our own species. #SfN24#OpenAccess https://t.co/b55ZUISVpv
In quantum mechanics, the observer effect boils down to the idea that the world state is lazily evaluated (i.e. you only compute something when the result is causally needed to evaluate something else). This makes the many-world interpretation very icky: MWI requires "compute" and "storage" in the below-world substrate to be free and in infinite supply. But the entire point of lazy evaluation is to save compute and storage!
Basically: if the universe has made the design choice of lazy evaluation, it implies that whatever resources it runs on must cost something, which in turn rules out the infinitely resource-hungry many-world design choice.
Interesting work on reviving RNNs. https://t.co/kTOze8qINv -- in general the fact that there are many recent architectures coming from different directions that roughly match Transformers is proof that architectures aren't fundamentally important in the curve-fitting paradigm (aka deep learning)
Curve-fitting is about embedding a dataset on a curve. The critical factor is the dataset, not the specific hard-coded bells and whistles that constrain the curve's shape. As long as your curve is sufficiently expressive all architectures will converge to the same performance in the large-data regime.
This paper reports a CRISPR-based method to wipe data stored in DNA.
Single-stranded DNA that should *not* be erased is converted into double-stranded DNA. Everything else gets chewed up.
"It is possible to wipe 10^11.7 files of up to 10^7 GB with 100% file sanitization."
Hippocampus is phenomena-rich, all confusing! What if they arise from the wrong space-centric view?
We offer a different story of how space is represented in the brain
* there are no place cells! cognitive map is not spatial!
* Kant is wrong, Leibniz is right!
* place field methodology is usefully wrong 🧵 1/
https://t.co/t48CtJDAq4