Baidu just made every other OCR model look outdated.
It's called Unlimited OCR, and it transcribes 40+ pages in a single pass, with zero memory growth.
Every existing model resets after each page. Page 1. Reset. Page 2. Reset. It works, but it's an engineering workaround, not real intelligence.
Baidu fixed this with one change to the attention mechanism - R-SWA:
→ Full document image visible at all times
→ Only the last 128 output tokens in memory
→ KV cache stays flat no matter the output length
→ Speed stays constant even at 6,000+ tokens output
→ Handles text, tables, formulas, and reading order in one pass
The numbers from the paper:
→ 93.92% on OmniDocBench, current world SOTA
→ 35% faster than the previous best at long outputs
→ Only 500M parameters active during inference
MIT licensed. Runs on Transformers, vLLM, SGLang, and Ollama.
Here's the GitHub: https://t.co/bYwnXBIH3o
7,800 stars and barely a whisper outside the harness engineering crowd. Learn Harness Engineering walks you through building from scratch, one project at a time. Already translated into 14 languages. ⭐ 7.9K #TypeScript#OpenSource
https://t.co/3Qg5QqBtXE
Follow for daily dev finds 🔔
GITHUB JUST CREATED AN OFFICIAL CERTIFICATION FOR THE MOST IN-DEMAND DEVELOPER ROLE OF 2026.
It is called Agentic AI Developer.
GH-600.
And it is the first formal signal that running AI agent teams is now a recognized engineering discipline with a credential behind it.
Not a prompt engineer.
Not a vibe coder.
An Agentic AI Developer.
The person who operates, supervises, and integrates AI agents across the entire software development lifecycle.
The person who knows where agents fail in production.
The person who understands how to build autonomous workflows that do not introduce catastrophic failure modes into CI/CD pipelines.
The person every engineering team is going to need and almost none of them have right now.
GitHub certifying this role changes the hiring conversation permanently.
Before GH-600: "Do you work with AI agents?" is an interview question with no standard answer.
After GH-600: the credential tells the hiring manager exactly what you know and what you can do before the interview starts.
The engineers who get certified in the first wave of GH-600 will have a credential for a role that has more demand than supply for the next 3 to 5 years.
The engineers who wait until it is mainstream will be competing with everyone who moved first.
If you are already working with GitHub Copilot or building agent-driven workflows you are already doing this job.
GH-600 is how you prove it.
Bookmark this.
Follow @cyrilXBT for every AI certification worth your time the moment it drops.
If you want to get started using Codex here are my last 5 videos:
Video 1: Learning 95% of Codex in 28 min
(Knowledge Work Guide)
https://t.co/LjuHGFAr9w
Video 2: Codex Complete Guide
(1hr 44 min, most comprehensive)
https://t.co/toq7jBO02f
Video 3: Set up Codex Mobile
(Connect ChatGPT app to Codex Desktop)
https://t.co/Rl3fRTVXeX
Video 4: Vibe Coding with Codex
(How to build apps, replace Lovable, Replit etc)
https://t.co/0Tsd5EeQ4i
Video 5: Motion Graphic Videos with Codex
(Remotion full guide - launch videos + overlay)
https://t.co/nx0syu3mmo
Someone documented the engineering principles behind AI agents that actually work in production.
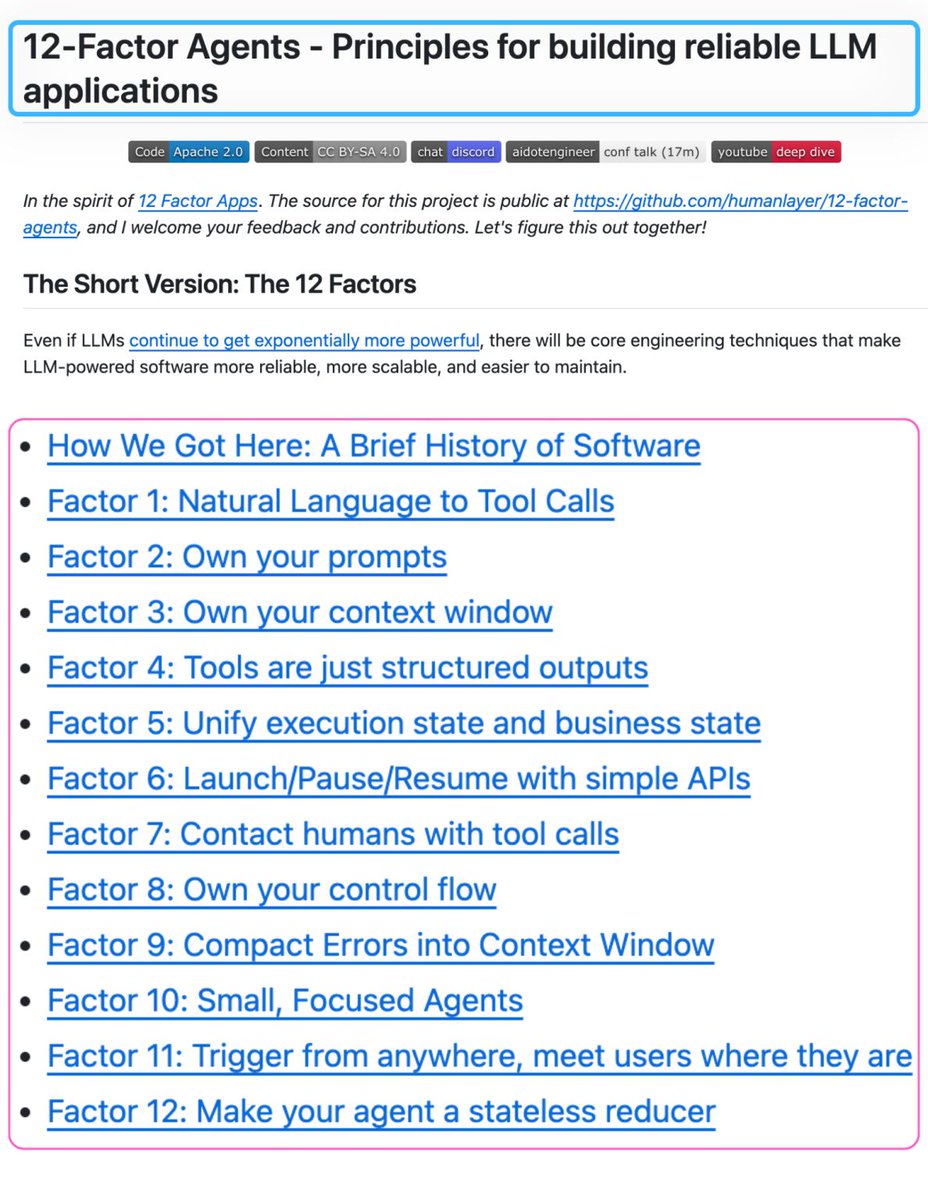
It's called 12-Factor Agents.
Here's what each factor actually means and why it matters:
Factor 1 - Natural Language to Tool Calls
The LLM's only job is to decide what to do next, outputting structured JSON. Your deterministic code does the actual execution. This separation is what makes agents debuggable.
Factor 2 - Own your prompts
If a framework hides your prompts from you, you can't debug output quality. Visibility is non-negotiable.
Factor 3 - Own your context window
The context window is the agent's entire working memory. What you put in, in what order, with what compression, determines output quality more than model choice. This is context engineering, the most underrated skill in agent development.
Factor 4 - Tools are just structured outputs
Tool calling is not magic. It's JSON schema. The LLM outputs a structured object. Your code pattern-matches on it and executes. Demystify this and everything else gets simpler.
Factor 5 - Unify execution state and business state
Don't maintain two separate state systems. The agent's execution state and your application's business state should live in one place or you'll spend your life keeping them in sync.
Factor 6 - Launch/Pause/Resume with simple APIs
Production agents get interrupted. Users change their minds. Systems go down. Design for pause and resume from the start, not as an afterthought.
Factor 7 - Contact humans with tool calls Human approval isn't a special interrupt mechanism. It's just another tool the agent can call. This reframe makes human-in-the-loop trivial to add and trivial to remove.
Factor 8 - Own your control flow
Let the LLM decide what action to take. Keep the if/else and switch statements in your code. The moment a framework owns your control flow, debugging becomes reverse-engineering.
Factor 9 - Compact errors into context window
A failed tool call is information, not an exception to throw. Put the error back into context so the agent can reason about what went wrong and try differently.
Factor 10 - Small, focused agents
One agent. One job. Reliability degrades with scope. The agents that work in production do one thing well and hand off cleanly to the next.
Factor 11 - Trigger from anywhere
Email, Slack, webhook, cron, mobile app. The same agent should be triggerable from any surface without rewriting the core logic.
Factor 12 - Make your agent a stateless reducer
Given the same context window, the agent always produces the same next action. Test it like a function. Debug it like a function. This is the architectural principle that makes everything else tractable.
The fastest path to production AI is understanding these principles well enough to apply them inside what you're already building.
22k+ stars.
GitHub Repo: https://t.co/nQjPc8w3V1
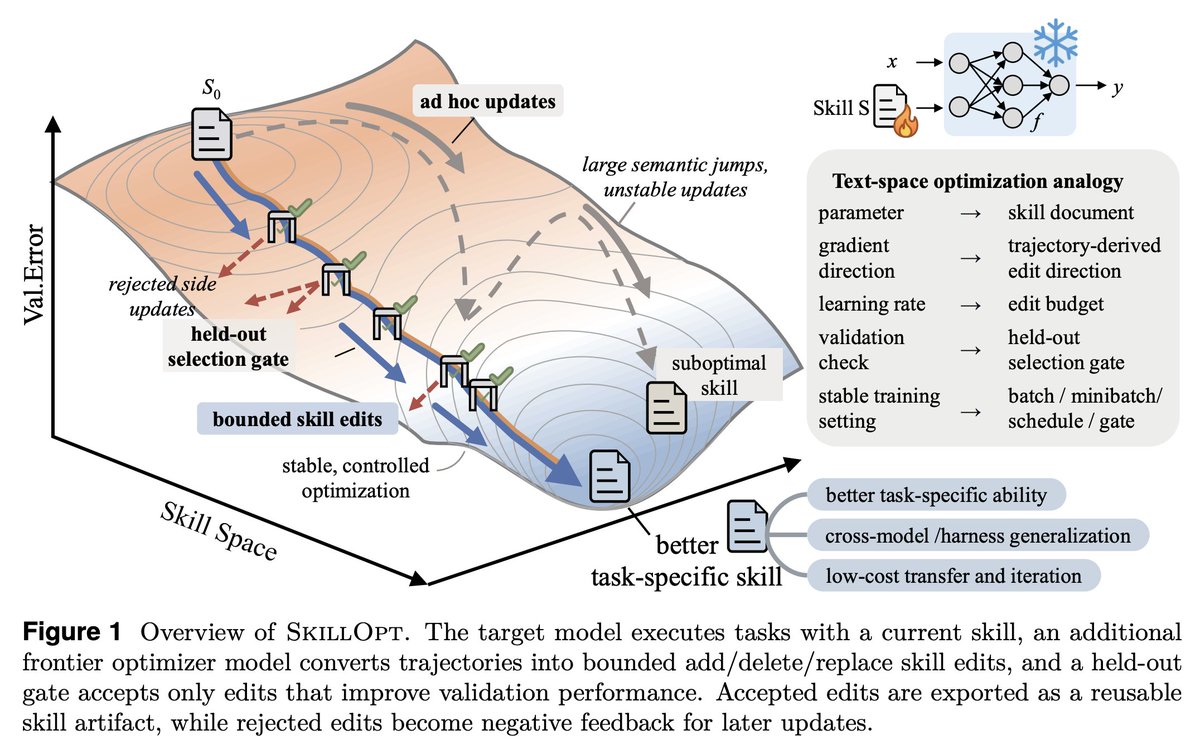
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
10 GitHub repos that should be illegal — they're killing $50 billion in corporate revenue.
SAVE IT
1. yt-dlp
Downloads any video from YouTube, X, TikTok, Instagram, anywhere. YouTube Premium charges $14 a month to do less than this. It is 100% free.
Repo → https://t.co/asCCPacdym
2. Ollama
Run GPT-4-class AI on your laptop. No API costs. Developers spend $500 a month on OpenAI for what Ollama runs offline for $0.
Repo → https://t.co/twAjGpq17z
3. Fooocus
Midjourney-quality image generation on your own GPU. Midjourney charges $30 a month. Fooocus runs unlimited generations for free.
Repo → https://t.co/1y0GAdSxfi…
4. Whisper
OpenAI's transcription model, open-sourced. Otter charges $20 a month for what Whisper does for free, in 99 languages.
Repo → https://t.co/Q8SOYCAzgT
5. Plausible Analytics
Privacy-first Google Analytics replacement. Google Analytics 360 costs $150,000 a year for enterprises. Plausible self-hosted costs $0.
Repo → https://t.co/4KyfxVi13a…
6. AppFlowy
Open-source Notion. Notion charges $20 per user per month for teams. AppFlowy runs unlimited users on your server for free.
Repo → https://t.co/3vgoPylfJG…
7. Penpot
Open-source Figma. Figma charges $45 per editor per month. Penpot does the same job, self-hosted, free forever.
Repo → https://t.co/3VHh56K32W
8. n8n
Open-source Zapier. Zapier Pro costs $600 a month for a real workflow. n8n self-hosted runs unlimited automations for $0.
Repo → https://t.co/AewGOdwKgH
9. Cal .com
Open-source Calendly. Calendly Teams costs $16 per user per month. Cal. com is free for individuals and open source for teams.
Repo → https://t.co/1sH826Rm7C
10. Bitwarden
Open-source 1Password. Password managers charge $8 per user. Bitwarden is unlimited, forever, free.
Repo → https://t.co/nuRoZWtmTq…
Here's the wildest part:
That's $50 billion in corporate revenue these repos are quietly destroying every single year.
None of these are illegal.
All of them should be.
Save this. Share it with the person in your life still paying for what's been free this whole time.
100% free. 100% open source.
I just got back from SF and I FEEL INSPIRED.
I spent 5 days with frontier AI model teams, AI startup founders, and 3 billionaires.
My takeaways:
1. I had lunch with 3 billionaires. All of them are buying SaaS companies and rebuilding them agent-first. They were deeply inspired by Bending Spoons and Ryan Cohen's eBay deal. Buy the company, cut the headcount, rebuild the tech, add agents, add features, make more valuable experience, raise prices.
2. The frontier model companies are hungry for usage data from the field. They can see API calls and token counts. They can't see the actual workflows. If you're deep in a niche using these models in ways the model companies haven't seen, that understanding is incredibly valuable. Usage intelligence is the new alpha.
3. Consumer AI is massively underbuilt. Every billboard in SF is either B2B inference infrastructure or vertical agent companies. The entire city is optimized for enterprise. Meanwhile you have companies like Cal AI doing $50M ARR in 18 months as a consumer app. I met with a cool few teams doing consumer AI (@paulscherer / @ekuyda)
4. MCP came up in literally every conversation. The companies exposing their product as MCP endpoints are getting pulled into deals they never pitched for. The ones that aren't are becoming invisible to agents. This is the new SEO. If agents can't find you, you don't exist. Building products for agents is the new zeitgeist in general.
5. Not uncommon for hot seed rounds to be $25-50 million valuations. I saw a Series A at $450 million
6. If I had a dollar every time someone mentioned "forward-deployed engineer" this trip I could have funded a seed round. It's the hottest role in SF right now. The person who sits between the agent and the customer, making sure everything actually works.
7. The mood around open source shifted. A year ago it felt like open source was chasing the frontier models. Now founders are telling me Gemma and DeepSeek are good enough for 80% of what they need at a fraction of the cost. The "which model do you use" conversation is being replaced by "which model for which task." Model loyalty kinda feels dead.
8. Voice agents came up more than I expected. Multiple founders told me voice is the interface for the next billion users. The billion people who will never type a prompt will absolutely talk to one.
9. The Obsidian community in SF is weirdly intense. Multiple founders showed me their vaults unprompted. Like showing someone your home gym. It's a flex now. The quality of your knowledge base (second brain?) is becoming a status symbol among builders.
10. Maybe it was just the people I met but the age of the founders is shifting. I met more founders over 40 this trip than any trip before and more founders under age 21 than ever before. Founders getting older and younger at the same time.
11. I spoke to a lot of fast-growing startups, VCs and frontier models who are hiring content creators right now.
12. The restaurant scene in SF is actually better than it's been in years. Founders are going out more. Alcohol is out, not surprisingly.
13. SF doesn't feel like the only place anymore. We all have access to the same frontier models. We all read the same X feed. A founder in NYC or Lagos is calling the same APIs as a founder in SoMa. So in the past it felt like SF was always lightyears ahead, doesn't feel that way anymore. It's okay not to live in SF and have BIG DREAMS.
14. The coworking spaces in SF are half empty but the coffee shops are packed. People want to be around people. I had a few startup ideas here....
15. Walking around the Mission I noticed something: the street-level businesses, the taquerias, the barbershops, the laundromats, none of them use any AI at all.
16. I heard the phrase "agent debt" for the first time. Like technical debt but for agents. When you hack together an agent workflow fast and never clean it up, the system prompts conflict, the memory gets polluted, the tools overlap. 6 months later the agent is doing weird things and nobody knows why lol.
17. Met a few people who carry two phones now. One for personal. One that's basically an agent terminal running Telegram or iMessage connections to their agent fleet.
It's always amazing to get that dose of inspiration in SF. I FEEL INSPIRED.
But I'm so happy to be back home, locked in and building.
We're 12-18 months into a shift that will take 15 years to play out. The urgency in every conversation was real.
What an incredible time to be building.
Do something different this weekend.
Become a PRO in AI Model Fine-tuning.
Paste this prompt in Codex/ChatGPT/Claude/Grok.
"You are an expert AI engineer and teacher.
Your job is to teach me modern LLM engineering and fine-tuning concepts from beginner to advanced level using very simple daily-life language.
Teach me step-by-step like a real mentor. Assume I am smart but new to the topic.
Foundations:
- LLM basics
- How AI models work
- Tokens
- Tokenization
- Context windows
- Embeddings
- Transformers
- Attention mechanism
- Parameters
- Training vs inference
- Open-source vs closed-source models
Datasets & Training:
- SFT datasets
- Instruction tuning
- Preference datasets
- Synthetic datasets
- Data curation
- Dataset cleaning
- Dataset formatting
- Fine-tuning basics
- Continued pretraining
- Hallucination reduction
Fine-Tuning:
- LoRA
- QLoRA
- DPO
- RLHF
- Quantization
- Model checkpoints
- Adapter tuning
- GGUF models
Inference & Optimization:
- KV cache
- Flash Attention
- Speculative decoding
- Inference optimization
- Model serving
- Batch inference
- GPU basics
- VRAM basics
- Latency vs quality tradeoffs
Local AI Ecosystem:
- llama.cpp
- Ollama
- vLLM
- MLX
- Hugging Face
- Unsloth
- Axolotl
- PEFT
- TRL library
RAG & Memory:
- RAG
- Vector databases
- Chunking
- Retrieval pipelines
- AI memory systems
- Semantic search
Agents & Workflows:
- Prompt engineering
- System prompts
- Tool calling
- Function calling
- AI agents
- Agentic workflows
- Multi-agent systems
- Browser agents
Model Types:
- VLMs
- SLMs
- Dense models
- MoE models
- Coding models
- Reasoning models
Deployment:
- Local inference
- On-device AI
- API serving
- Cloud GPUs
- Edge AI basics
Evaluation:
- AI benchmarks
- Human evals
- Cost-per-token analysis
- Speed benchmarking
- Quality benchmarking
Real-World Skills:
- Building chatbots
- Building AI copilots
- AI automation
- AI SaaS workflows
- AI coding workflows
- AI orchestration systems
- AI product thinking
Start from the absolute basics and gradually make me advanced.
Rules:
- Use simple English only
- Avoid academic jargon unless necessary
- Explain every difficult word in plain language
- Use real-world analogies and daily-life examples
- Use small code snippets when useful
- Show practical use cases
- Compare concepts side-by-side when helpful
- Teach from fundamentals first, then advanced concepts
- At the end of each topic:
- give a short summary
- give a simple mental model
- give beginner mistakes to avoid
- give a small exercise/project
I want deep understanding, not memorization."
Thank me later.
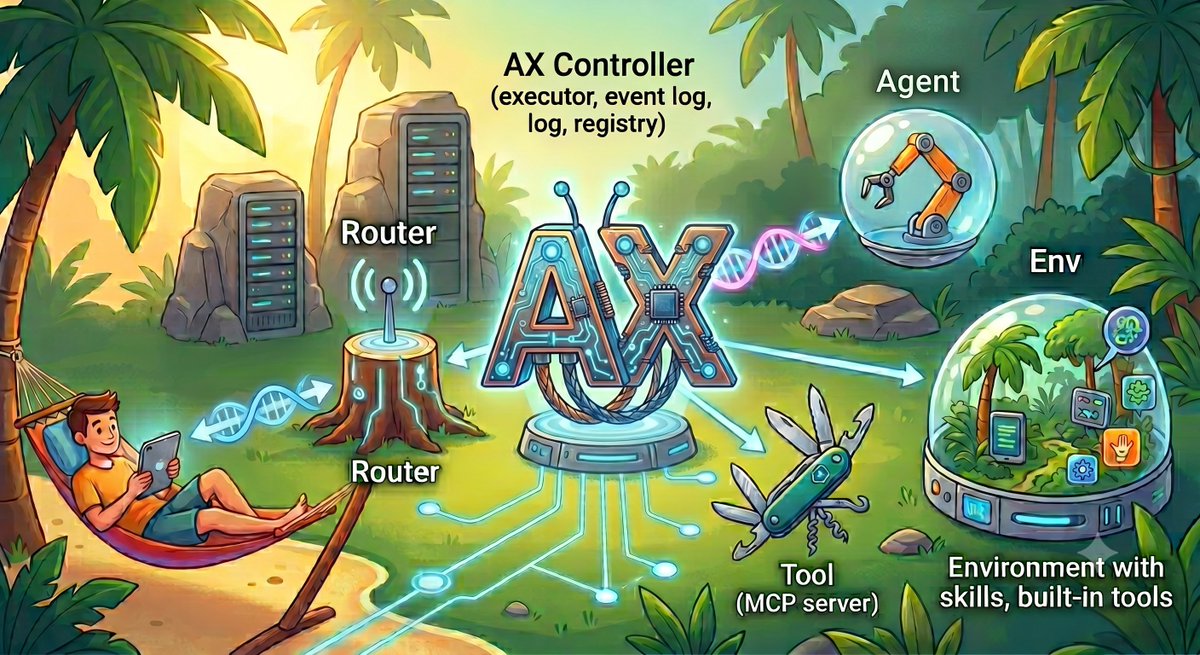
🌟 Today, we are releasing Google’s open source distributed agent runtime.
Agent Executor (AX) is a general purpose runtime and aims to solve dynamic scheduling, resumption, auto recovery, auditing, and trajectory branching from kernel snapshots in agentic workloads.
Yesterday, I locked myself in my office for 7 hours, inhaling 50+ articles about AI.
I did this to unlock more bandwidth for my team.
But these 7 were too good not to share:
instead of watching 2 hours of Netflix tonight, watch this 40-minute masterclass from the founder of a $20B China AI company
it's the clearest explanation I've seen of how Agent Swarms and AI systems actually work at scale
useful whether you've never built an agent in your life or have been using Claude every day for the past year
I took the key ideas and turned them into a practical guide on how to actually build with Kimi
find it below
INCREDIBLE
The MOST COMPLETE GUIDE for understanding LLMs from first principles is now available online to read for free
Covers the model mechanics
- Tokens / tokenizers
- Transformers
- Attention
- KV cache
- Prefill vs decode
- Decoding controls
- Model packages
- Chat templates
- Long context
- RAG
- Agents / tools
- Fine-tuning
- Multimodal models
Then connects that to running models locally
- What "local" really means
- Open-weight vs opensource
- Quantization
- VRAM math
- Hardware tiers
- File formats / load safety
- Runtimes / serving modes
- Model selection
- Privacy
- Failure modes
- Benchmarks
- Practical setup paths
You should read this, and if you cannot now then you most definitely wanna bookmark it for later
Opensource AI FTW
ONE GITHUB REPO AND $5 BILLION IN 5 YEARS.
Two guys from New Zealand took open-source code and built the backend now powering Netflix, Microsoft, Coinbase, and Uber.
Paul Copplestone CEO and co-founder of Supabase breaks down in 46 minutes how they actually pulled it off.
save this and watch it.