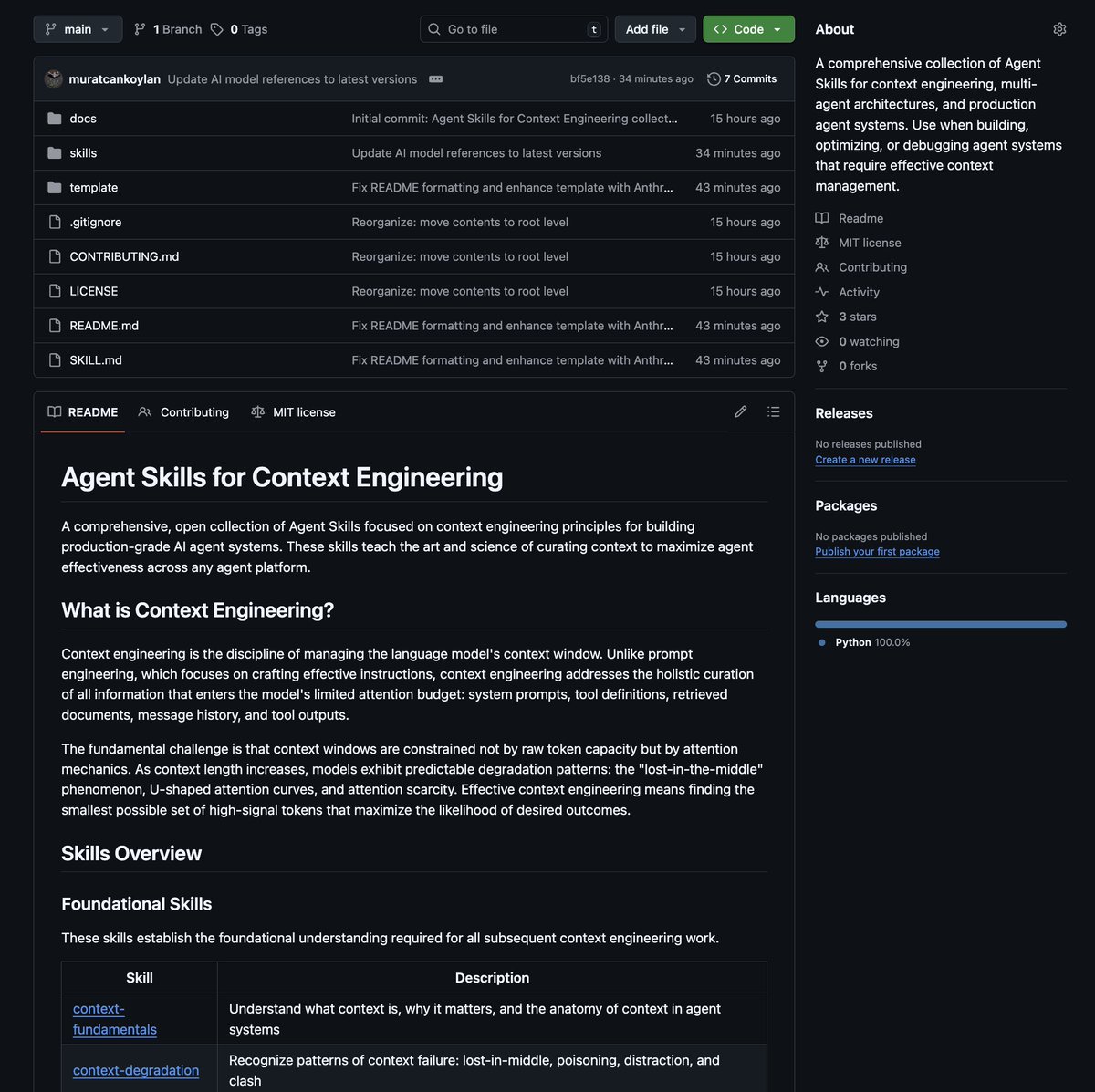
I’m excited to share a new repo: Agent Skills for Context Engineering
Instead of just offering a library of black-box tools, it acts as a "Meta-Agent" knowledge base. It provides a standard set of skills, written in markdown and code, that you can feed to an agent so it understands how to manage its own cognitive resources.
https://t.co/vWwrYPAd8k
Most agent failures are not model failures; they are context failures. This is still an experimental project. The goal is to establish a platform-agnostic standard for context engineering that can be used in Cursor, Claude Code, Copilot or Codex.
skills/
context-fundamentals: What context is, why it matters
context-degradation: How context fails (lost-in-middle, poisoning)
context-optimization: Compaction, masking, caching
multi-agent-patterns: Orchestrator, swarm, hierarchical
memory-systems: Vector RAG, knowledge graphs, Zep
tool-design: Building tools agents can use
evaluation: Testing and measuring agent systems
I believe this is a good start, showing developers how to approach context engineering rather than relying on ready-made tools.
You will also find the aggregated research documents I used to build these skills in the repo. The skills are synthesized from technical blogs on context and prompt engineering that I bookmarked, AI Labs' documentations, and Anthropic Skills examples.
Try the 7 Skills, created using Antrhopic's Skills template format. Experiment with the provided scripts and references, and feel free to contribute to the repo.
It’s actually a good question; the difference is subtle but structural.
I usually frame it like this:
AGENTS[.]md acts as the declarative context. You write this for every repo (and nested directories) to define the project structure, persona, and coding rules.
Skills are the functional protocols. They provide the agent with modular capabilities like advanced tool-use and multi-step chaining that are dynamically discovered only when needed.
If AGENTS[.]md defines the identity and environment (the body), Skills provide the specialized toolset (the capabilities) used to execute tasks autonomously.
My prompting has changed dramatically over the past five to six months.
I used to write detailed, PRD-like prompts.
Now, it’s just long, messy voice dictations.
They’re really messy (the task details and some background, what i'm feeling, why we are doing this etc like a diary), but current models and harnesses are doing a great job when you provide as much context as possible.
changing your mind in the middle of voice prompting gives the model so much more context
like 70% of my prompts i say "actually ignore everything before this" but it gives so much information when i imagined one thing but then decided on something else
aim for MAX tokens
Pretty great to hear the thinking behind DeepMind's Virtual Agent Economies paper.
The LLM is just a component. The harness is what's eating the world, and everything is turning into harnesses and sandbox economies.
Why autonomous agents haven't taken off the way we all expected? We have MCPs, CLIs, browser-using agents, and models that are cheap and can do almost anything. Yet humans still do all the real work. Except coding.
The reason is verification.
Software loops are cheap to close: you write a test, run it, and errors roll back. That's why coding is where agents actually work today.
But someting like "plan my wedding," "negotiate this contract," "manage my inbox autonomously" verification cost is roughly equal to doing it yourself, and errors are expensive and irreversible.
When verification ≈ doing it yourself, autonomy delivers zero leverage. It doesn't save you work. That's why "models keep getting better" hasn't unlocked it.
Frankly, my hypothesis on slow agent adoption was slow human behavior change. But that's downstream; we adopted ChatGPT in a weekend. Behavior change is slow here because the value proposition, net of verification cost, is unproven for autonomous tasks.
So we're overestimating that intelligence is the bottleneck. Autonomy only pays when verification is cheap, errors are reversible, and someone can be held accountable. Almost no valuable real-world task has all three yet.
One last thing I find interesting is this: cognitive monoculture → correlated failure → systemic risk.
A handful of base models means thousands of "independent" agents make correlated decisions, so failures stop being independent and start stacking. That's why I think not just evals, but persona embodiment is becoming a crucial part of adoption, something like a risk-decorrelation tool for multi-agent fleets.
One model won't be doing everything; a society of certified specialists with a generalist connective layer.
Paper: https://t.co/s1wOOr8uap
What happens when millions of AI agents start negotiating, transacting, and delegating to one another?
@weballergy joined our podcast with @fryrsquared to explore the rise of agentic economies – and how we can diversify agent decision-making to avoid AI groupthink.
Timecodes:
00:00 Intro
1:07 Defining AI agents
4:44 Agentic exploration in science and research
15:46 Delegation between agents
22:46 Agentic security and traps
29:31 Building an agentic economy
33:22 Cognitive monoculture
36:29 Distributed intelligence
Memento-Skills is a self-evolving skill harness. It's a great paper to understand loop-engineered agent systems.
The editable surface is the skill library.
The feedback signal is judge-scored task success.
Learning happens through external artifact mutation.
Observe -> Read Skill -> Execute -> Judge/Feedback -> Write Skill Update
The router selects a skill for the current task. A query about “extracting patient medication history” and a query about “summarizing patient history” may look semantically close, but the correct execution behavior is different.
Their proposed router is trained for behavioral similarity which I find very useful:
- generate synthetic user goals for each skill
- generate hard negatives that share terminology but should not use that skill
- train with multi-positive InfoNCE (contrastive training objective for retrieval)
interpret the embedding score as a soft Q-value
- route to the skill most likely to produce successful execution
So the router is asking: “Which skill historically leads to the right outcome for this kind of task?”
The repo also has a gateway layer between the agent and skill execution. The execution engine is a ReAct-style loop: build messages, expose allowed tools, let the LLM act, process tool results, update state, and stop on success/failure/loop conditions.
That makes execution observable. The system can tell whether a skill produced artifacts, repeated itself, got blocked by policy, timed out, or claimed success without evidence.
They also have Reflector / Judge. In benchmark mode, the judge knows the gold answer. In production, this could be an eval rubric, human review, unit test, or downstream signal.
The Skill Evolution Engine then has three update modes:
- Utility update: track empirical success rate per skill.
- Optimize existing skill: patch prompts, code, or guardrails for a specific failure mode.
- Discover new skill: create a new skill when repeated failures show the current abstraction is wrong.
The skill is effectively policy. So the model stays fixed, but the action distribution changes because the retrieved skill changes.
Turning skills from static context files into versioned, evaluated, self-improving policy artifacts is still hard. But I expect coding platforms to integrate this into user-facing systems soon.
As frontier model access gets constrained by pricing, policy, rate limits, and availability shocks, more performance will have to come from the substrate around the model.
They are playing a very technical game; it’s difficult for teams that use park-the-bus tactics like Paraguay or Australia, but their first real tests will be against teams that play positive football with talented players after the group stage. The next Turkiye match will be also very fun to watch.
I’m actually struggling with this the past few days. Without writing documentation, you have to spend a lot of time and tokens onboarding agents to projects. The same goes for new hires.
However, documentation becomes outdated so quickly, and keeping it up to date isn’t as easy as it sounds.
Oh boy, the amount of AI-generated job applications is crazy.
As someone who became an MTS without an academic background, here are a few things I would do if I were looking for a job in AI right now.
I’m writing this post because after sharing a few AI job openings, I’ve been receiving a lot of very low-quality applications from people at genuinely reputable universities. I’m honestly shocked.
First: stop using AI terms just to use them.
No one cares about your “RAG application” that you built 3 years ago. No one is impressed because your resume says “GenAI.” These terms do not mean anything unless there is actual work behind them.
Applying to 1 job a day with a customized application is way better than spamming 100 companies.
For example, we have open research, papers, product details, and public writing about what we are building. Go read them. Learn what the company is actually researching. Try to understand the system, not just the job title.
The competition is incredibly high.
Your CV, unless you have a logo like DeepMind, or your university, is not that important by itself. You need to grind and build stuff.
When I look at a candidate, new grad or experienced, I expect to see a GitHub and Hugging Face with a bunch of projects, blog, demos, or some public proof that they are actually working on AI right now.
If you want to be an AI engineer but you have not experimented with auto-research, RL environments, meta-harnesses, eval loops, small model training, dataset generation, or similar systems, your chances are very low.
These might sound like buzzwords, but they are not. They are real components of where AI is evolving. Building projects in these areas shows that you are paying attention.
We rewrite large parts of our AI codebase every 6 months because models are changing fast, but more importantly, harnesses are changing fast.
The only legit way to keep up is not just reading research papers, but also following companies and teams that generously share what they are learning: OpenAI, Cohere, Ramp Labs, Dropbox, Thinking Machines, and others.
As a candidate, you should have at least 4–5 recent projects from the last few months.
Reproduce a paper. Train a unique small model. Build an eval harness. Do some RL work. Build an agent loop. Create a synthetic data pipeline. Ship something weird but useful.
It does not need to be perfect. It needs to show that you are alive in the field.
Also, ask questions. Challenge us.
If you are interviewing with an AI startup, you should be thinking about the same things we think about internally.
For example: what happens if a company like Anthropic decides to become a competitor and releases a model that destroys our current advantage? What should we do? How do we become not just defensive, but untouchable?
If you want to join an AI startup, you should be thinking about these questions and coming up with creative answers. Not generic answers.
The only reason I found my first AI role was because I was a marketer who became obsessed with LLMs embodying different personas.
So I read papers and started building open-source persona AI projects. The ex-CMO of Google Canada saw them, brought me into his startup as the first AI hire, and we built 99Ravens.
The reason I left and joined Sully is similar. @omar_or_ahmed saw my context engineering projects and small model training examples, and wanted to meet.
That is the game.
Not “I applied to 400 jobs.”
Build things. Make them public. Make them useful. Make them weird enough that someone remembers them.
Join hackathons. Reproduce papers. Build tools around startups you like. If a company is hiring, analyze what they are building and create something related to it.
@benln from Cursor shares growing and hiring startups. Go analyze those companies, learn about their projects and research.
Also, @silviasapora has an amazing writeup on ML interviews with great insights. Read it and follow her steps: https://t.co/RfPw34V3wM
You do not need to know everything about this field. It is impossible. AI is too fast and too deep.
But you do need to show understanding, taste, and obsession.
We're hiring for a role very close to the work I care about most.
Applied AI Engineer at @sullyai
The role is evals + agent harnesses + self-improving loops:
- build eval systems for clinical AI agents
- turn clinician feedback + traces into self-improving loops
- read frontier work, then ship the useful parts fast
The job is to turn research into production systems clinicians can trust.
DM or apply:
https://t.co/lXczGhiJ2p
We're hiring for a role very close to the work I care about most.
Applied AI Engineer at @sullyai
The role is evals + agent harnesses + self-improving loops:
- build eval systems for clinical AI agents
- turn clinician feedback + traces into self-improving loops
- read frontier work, then ship the useful parts fast
The job is to turn research into production systems clinicians can trust.
DM or apply:
https://t.co/lXczGhiJ2p