So there is this thing, it is called the theory of planned behavior. You start to predict an individual's intentions to engage in a behavior at a specific time and place. I don't know if you've been looking at your phones or looking at your screens but be careful with your info.
Someone hid a self-replicating worm inside 37 npm packages.
Written in Rust.
Hidden behind an eBPF kernel rootkit.
Talking to its operator over Tor.
It steals 86 environment variables.
AWS keys. GCP keys. Vault secrets. Kubernetes tokens.
Your Anthropic API key. Your OpenAI key.
Your Exodus wallet seed phrase.
Then it uses your own npm credentials to republish itself into your packages.
So your code infects the next developer.
Who infects the next one.
The commits were backdated up to 13 years.
The commit author name was “claude.”
The malware named itself after the AI to hide in plain sight.
The attacker also left their own wallet recovery phrase in the debug data.
Nobody is having a good day.
Check your preinstall hooks.
Howdy folks! Taking a break from my twitter break to let yall know that we released a new @GreyNoiseIO product yesterday. It's called Project Swarm. We've been quietly not-so-quietly working on it for a few years. You can buy it now. It costs $1.
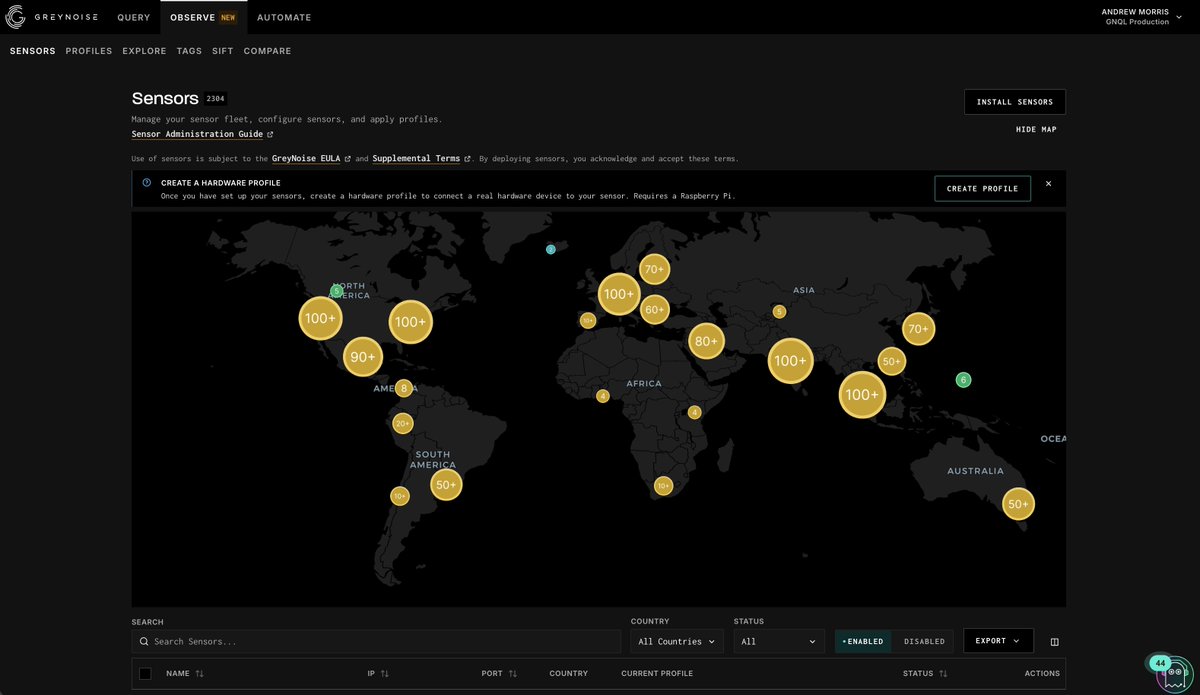
There are lots of vulnerabilities on edge-facing apps. To catch in-the-wild exploitation of them, we @ GreyNoise run sensors on the internet. New AI models means more vulnerabilities being identified and exploited, and FASTER. Long term, software and hardware will probably get better, but in the meantime we're gonna have to deal with A LOT of vulnerabilities.
At GreyNoise, the sensors we run are basically honeypots- we bait attackers to scan and exploit them which enables us to learn where the attackers are, which vulnerabilities they are exploiting, what it drops, and what it looks like on the wire. From ~2020-now it took us years to build up our fleet. Now anyone can use our new product to deploy their own sensors on their own networks, or an entire fleet of any size, in a day. You can rip back the data and do whatever you want with it. You can resell it, put it into your product, or just stare at it- whatever you want! On our side, we aggregate the data and pour it into a community dataset that everyone shares. As more people join, the data gets bigger and better.
Couple neat features:
- Sensor deployment is a single bash command on any modern linux distro that supports iptables and wireguard.
- Sensors and vulnerable software (profiles) are abstracted into different logical concepts, which means the "what" and "where" are different things, and the sensor is not constrained by the compute required to run the vulnerable software. Also, no matter how hacked the profile (honeypot) gets, it can't touch your host sensor or the rest of your network.
- Sensors can run fake honeypots, real software, or even real hardware (bridged with a raspberry pi) like old crappy routers and modems (or expensive firewalls and VPN gateways 👀)
- You can create dynamic blocklists that block IPs sourced from your own sensors in real time, so if a remote IP address *looks at your network* the wrong way, you block them instantly.
- All the PCAP data is available to you in a gorgeous and intuitive interface at near real time and fully enriched against all of our (thousands of) rules. We're working on the host metadata (malware, syscalls, host behaviors) as well, but this will come later.
- If we don't tag a CVE that's interesting to you, you can write a Suricata rule to tag it yourself once and your data gets tagged with it in real time forever.
- You can instantly download PCAPs of any exploits that hit your sensors.
- If you don't want your data shared with the community dataset, you can talk to our team and we'll work out rights to make it private.
Check it out! There's a lot of moving pieces to make this work and we expect bugs, but it's available right now. Join the fight!
https://t.co/erAWtX1l7B
I've added 6 more internal APIs and enhanced existing ones, especially Defender and Purview
Thanks to @SkipToEndpoint, I mapped out M365 Apps (config.office.com) and Intune Autopatch
Over 400K lines of code over 3 days, imma 10x garry tan 🤣
LMK if you want anything added
#ClaudeForBlueTeam - Day 18!
Keeping with the Sysmon config theme - you can prompt Claude to build you a heatmap of your Sysmon config. Looking at raw XML isn't ideal. This way, you can easily visualize what your Sysmon config covers and does not cover.
I'm a huge fan of using role assignable groups and restricted management admin units - this article is great at explaining why we should :)
One thing is missing though:
Tier 0 assets in Arc should always be locked down to prevent this type of attack
https://t.co/jugs3OTpaH
Technically brand impersonation, but the important thing is how to prevent it
dnstwist is a free tool to monitor for lookalike domains, and you really should run it against your domains and your partner domains: https://t.co/5L7RlswD0I
Online version: https://t.co/AolV8QhQWH
Your Conditional Access policies probably have gaps you don't know about
I talked to @emiliensocchi about how he built an engine that tests 250 MILLION sign-in combos in <20 minutes.
Runs Offline. No Throttling. No Limits.
Watch at https://t.co/iW85ihRNtX
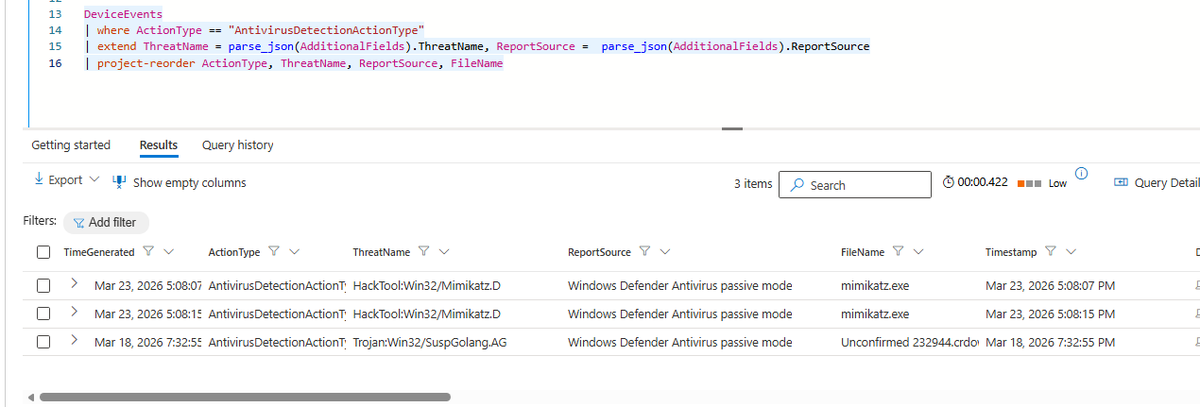
We got another event from the Timeline into Advanced Hunting: AntivirusDetectionActionType.
The event lists the ThreatName and ReportSource of the AV detection.
In the Defender for Endpoint Timeline Internals blog from last January, it was not there yet: https://t.co/hrGFX2GKOh
🤓 I was one of the technical reviewers for the latest @veritasium video on the XZ backdoor.
It brought me back to the four days without sleep I spent analyzing this case!
They did a great job making the story accessible and keep the technical accuracy 👏
https://t.co/NDvuykRhJU
Here’s how I currently see software development.
Imagine a farmer who grows cabbage.
He has one large field and several smaller ones. For years, a group of farm workers harvested the cabbage by hand. It took them a full week to clear the big field. They worked carefully. Sometimes a cabbage was damaged, but overall the quality was good.
Then the farmer discovers a machine.
The machine harvests the entire field in one hour and delivers all the cabbage to the barn.
It’s not perfect. Out of 1,000 cabbage heads, maybe 30 or 40 are damaged. The workers point this out immediately:
“When we do it by hand, only 10 get damaged. Our work is higher quality.”
They’re right.
But the farmer replies:
“You need a week for one field. The machine needs one hour.”
Now the machine can harvest:
the big field in the morning
the next field an hour later
then another
and another
Eight, ten, maybe twenty fields per day.
The farmer doesn’t ask the workers to compete with the machine anymore. He gives them a new job:
Stand in the barn. Pick up each cabbage. Check it quickly. Throw out the damaged ones.
That’s the new bottleneck.
And maybe, soon, the farmer buys another machine that does even that inspection automatically.
The workers are still correct: hand-harvested cabbage is often better.
But it no longer matters economically.
The speed difference overwhelms the quality difference.
This is where software development is heading.
Engineers are right when they say manual coding can be higher quality in many situations.
But it is orders of magnitude slower.
That gap is so large that even imperfect AI-generated code wins.
And the quality improves every month.
If it doesn’t improve, it gets cheaper.
If it doesn’t get cheaper, it gets smaller.
And once it’s small enough, it runs on your own hardware.
There is no visible ceiling yet.
So the role changes.
From writing code
to reviewing code
to supervising systems that write and review code.
Like the farm workers in the barn.
Not because their work was bad.
But because the machine changed the economics.
Mailbox auditing has always been a pain... :(
There is a reason my scripts get ALL mailboxes and iterate through them to force enable auditing and all records instead of trusting attributes
Don't wait until IR to found out you're hosed, follow my guide:
https://t.co/NKtQGQKeRm
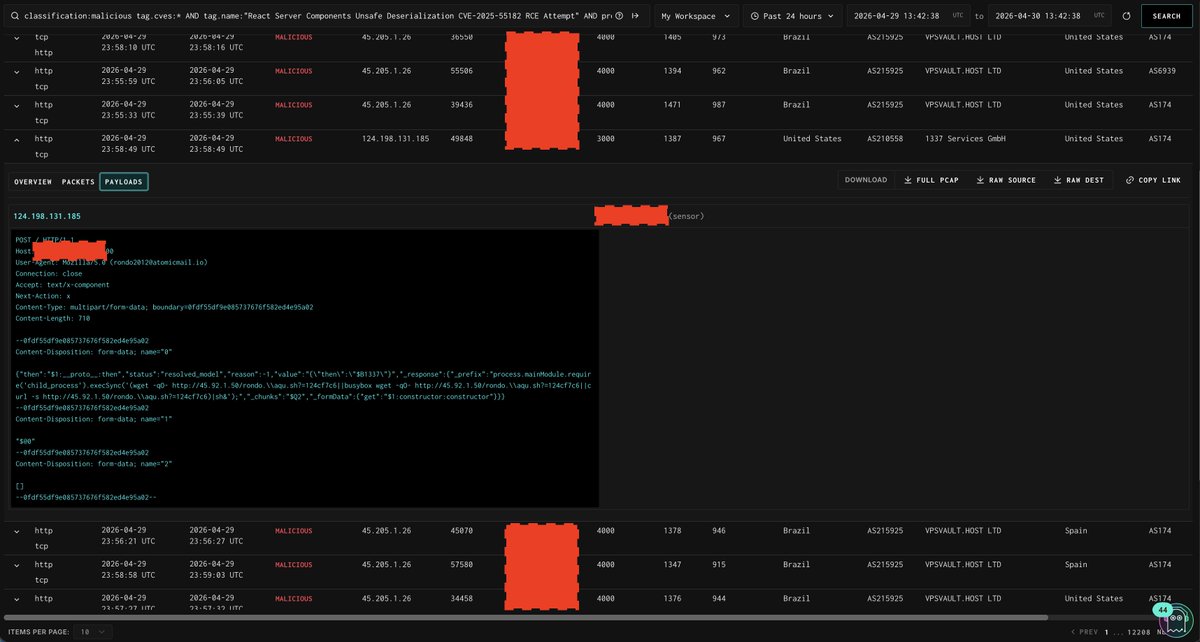
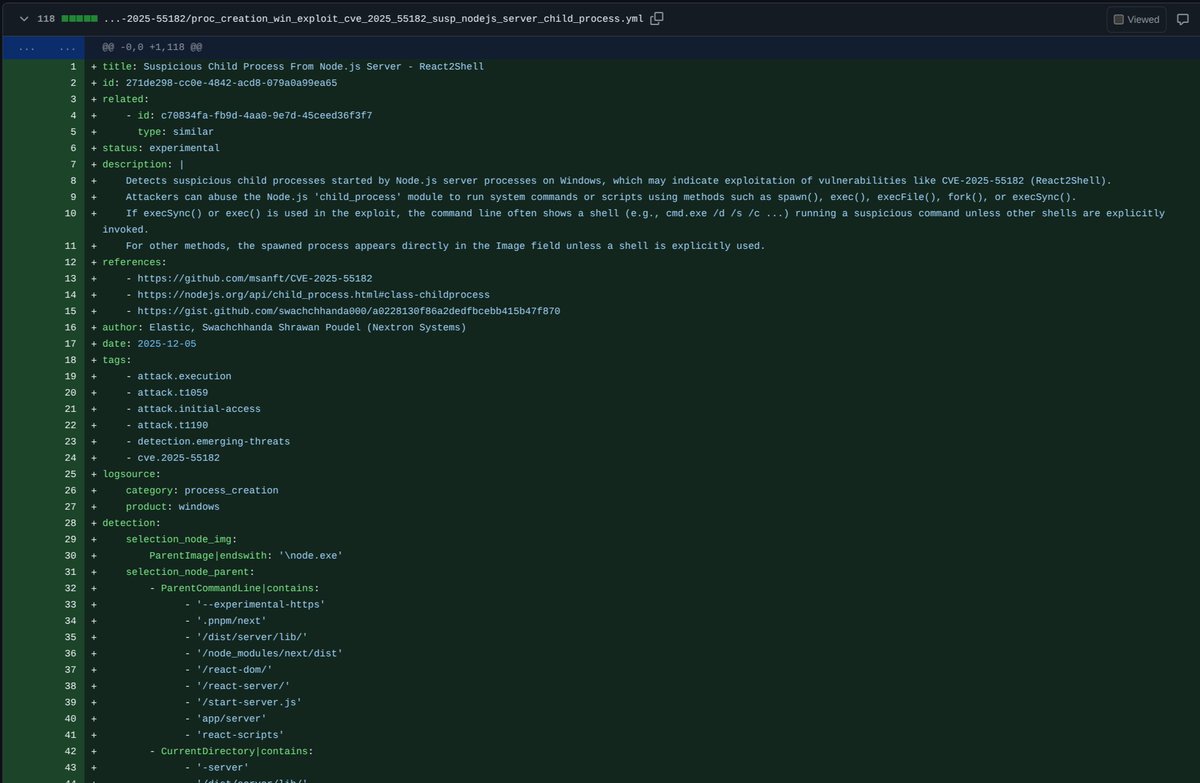
We’ve been digging through the #React RCE mess for two days now, trying to get at least some visibility into what’s going on out there. None of this is easy to detect, and most signals vanish in memory before you can even look at them.
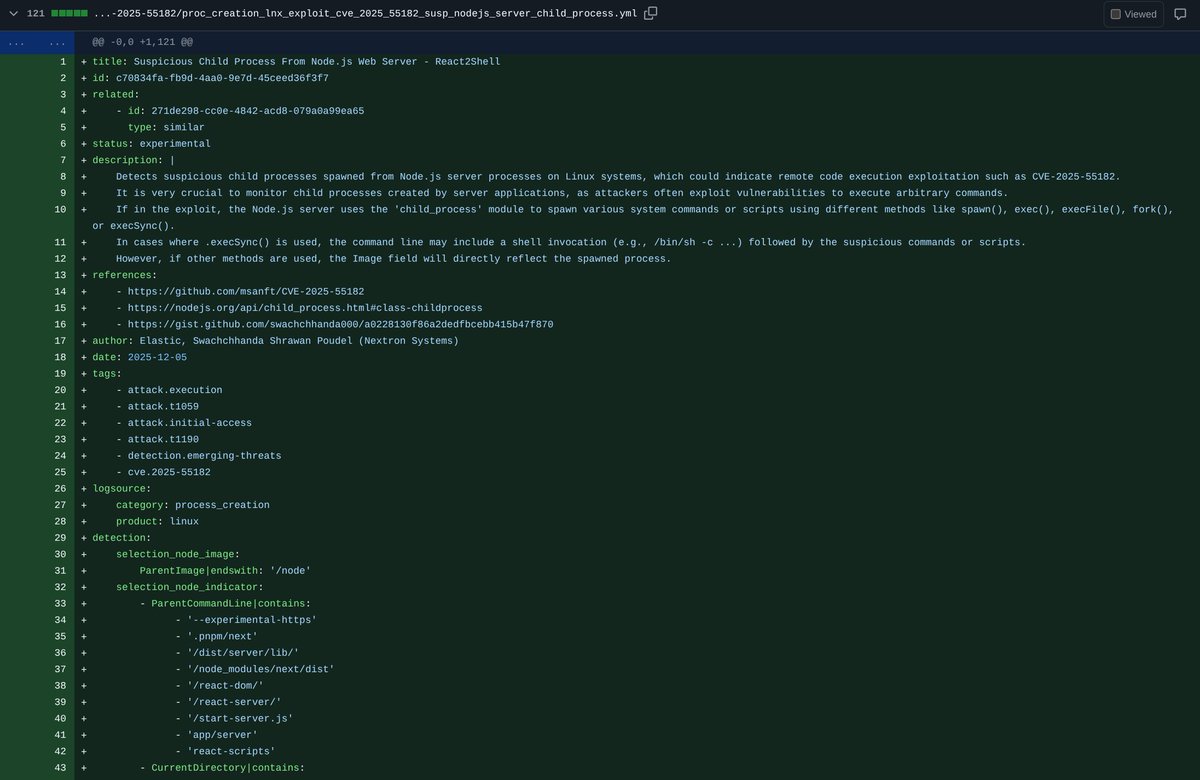
My teammate @_swachchhanda_ put together a pair of #Sigma rules that cover the one thing that reliably shows up when someone actually executes code on a Node.js server -> child processes. One rule for Linux, one for Windows. It’s not a silver bullet, just one of the few angles that makes sense right now.
We pushed all our #YARA and #Sigma signatures for the React RCE cases as well, and contributed the Sigma rules upstream:
https://t.co/37MnloL5oV
This whole situation shows how much attack surface lives in places many of us didn’t think about before. I expect we’ll see more of this class of issues now that people realize what’s possible.
It’s here — AND’s biggest (and only!) sale of the year!
For a limited time, every course is 25% off with code ALLYALL.
Level up your skills and sharpen your defenses. Visit https://t.co/JJOAtJrBBO