Excited to announce our @COLM_conf workshop "Context Beyond the Window"!
We have a stacked lineup of speakers focusing on one of the most important topics today: context management.
Venue is non-archival; We welcome all relevant 4 or 8-page submissions!
https://t.co/LWrTtE3quM
The DiLoCo team at Google DeepMind and Google Research is proud to release Decoupled DiLoCo, the next frontier for resilient AI pre-training.
Decoupled DiLoCo enables training with datacenters across the world, using heterogeneous hardware, and never halting the system despite hardware failures.
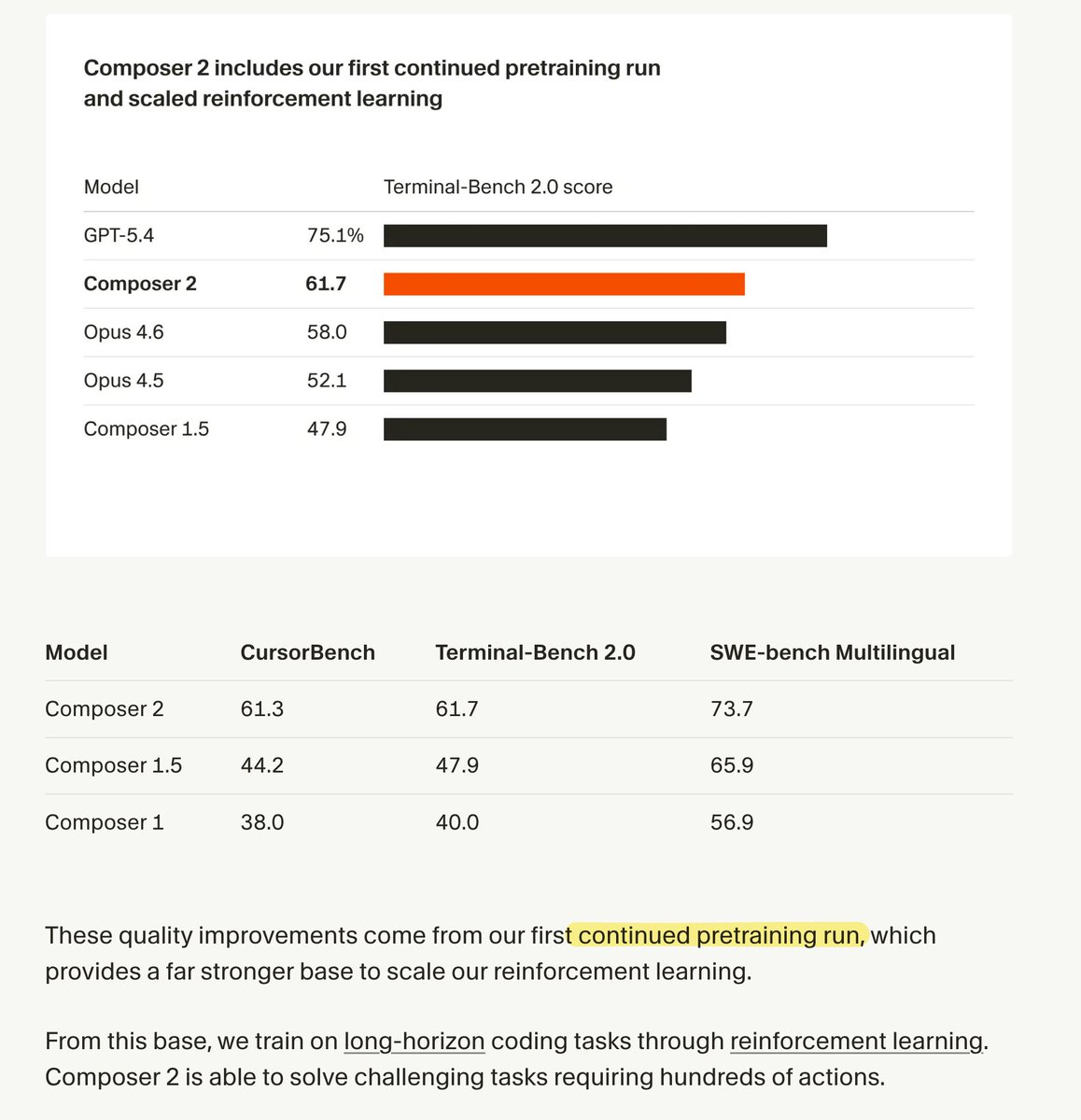
(continual) pre-training is not dead!
some thoughts about cost per task (on cursorbench) being 2x lower, imo it can be due to:
- new base model: seems straightforward but it's not imo, you need to optimize the inference/training stack (both for rl and consumer inference), GLM-5 > V3.2 doesn't mean glm-5-base > V3, they may not be equally malleable to post/mid training
- more optimized kernel and inference stack/serving (most likely)
- rl/mid-training with objective/data to make smaller CoT (most likely)
- mid-training with more efficient arch: i would love for this to be true, and i can see how it's necessary if they use the previous base model generation and need efficient memory for long context, but since they also released some tricks with self-summary, i'd say unlikely? (they can and imo should be combined together for very long tasks)
This week, we released a paper from Meta @AIatmeta
“MuLoCo: Muon is a practical inner optimizer for DiLoCo”, showing that K=1 MuLoCo has a Pareto-optimal performance-training-time tradeoff
Let’s drill deeper into single-worker MuLoCo’s efficiency 🧵1/5
https://t.co/HXyxYkexus
@deliprao Imho any work is worth publishing if you find it interesting and you have some kind of a contribution to share with the community. It should not be about flag planting but feeling confident to share your work. I hope you will find your way through academia :)
@natolambert Continual learning is needed if you deal with data distribution shifts. If you train your model with iid data all along and reach the level of IA you need, CL is useless. But tbh nowadays the multiple steps to pretrain/tune/post-train already have some taste of CL 🙃
After 5 years away from Paris, in Montreal and Berlin, I am excited to announce that I am back! 🎉
I am starting as a researcher in the freshly created IMEC AILABS at @imec_int 🚀
We will work on pushing the frontier of AI research and building creative innovations 🎈
@xeophon If you assume that the model can already realize all the operations you need then why not (ignoring the fact that the resulting algorithm might be slow) but if you need to change/increase the functional space of your model you have to update the parameters.
I mean it's a multimodal model (not inherently text-only), it's Instruct (not thinking), and it's compared with thinking models like K2 on non-thinking mode
this is an uneducated take imo
Intensifying geopolitical competition leaves AI bridge powers in a difficult situation where they’ll soon likely face insurmountable barriers to independent frontier AI development. To stay relevant and thrive economically, they need to work together and strategically choose their AI development approaches.
🔥 We stress-tested today’s best AI code generators in 𝑑𝑒𝑝𝑒𝑛𝑑𝑒𝑛𝑐𝑦 ℎ𝑒𝑙𝑙.
Introducing 𝐆𝐢𝐭𝐂𝐡𝐚𝐦𝐞𝐥𝐞𝐨𝐧 𝟐.𝟎: 328 challenges for version-controlled code generation.
The verdict? Even top models only hit ~50% success.
RAG and in-context learning are the go-to approaches for integrating new knowledge into LLMs, making inference very inefficient
We propose instead 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗠𝗼𝗱𝘂𝗹𝗲𝘀 : lightweight LoRA modules trained offline that can match RAG performance without the drawbacks
Tired of tuning hyperparameters? Introducing PyLO! We’re bringing hyperparameter-free learned optimizers to PyTorch with drop in torch.optim support and faster step times thanks to our custom cuda kernels. Check out our code here: https://t.co/5CnKdTHef0