"To compensate founders for their risk exposure, VCs offer an implicit bargain in which the founders agree to pursue high-risk strategies and in exchange the VCs provide them private benefits. VCs can promise to give founders early liquidity when their startup grows, job security when it struggles, and a soft landing if it fails."
Risk-Seeking Governance, by Brian J. Broughman and Matthew Wansley
One of the more concerning implications of the research that supports this article:
- VCs have traditionally acted as "monitors", to keep founders honest and compliant.
- Over the last few decades, that has been diminished in favour of being "founder friendly".
- "Founder friendly" manifests as letting founders do whatever it takes to drive growth.
- As a result, VCs profit from this via faster markups, and founders benefit by getting early payouts.
Essentially, they take the brakes off top-line revenue growth to generate faster, leading to rapid TVPI inflation and opportunities for early liquidity.
It also results in happier founders (better NPS scores) because they have hands-off investors who are happy to let them cash-out early and derisk failure.
But, it produces a slower rate of innovation, weaker performance, weaker exit activity, and a larger number of post-exit fraud cases.
It's trading away the future for the present, to satisfy greed and opportunism.
"We show that venture capitalists’ (VCs) on-site involvement with their portfolio companies leads to an increase in both innovation and the likelihood of a successful exit."
The Impact of Venture Capital Monitoring, by Shai Bernstein, Xavier Giroud, and Richard R. Townsend
Anthropic is paying $3,850 a week to people with no AI experience.
No PhD required. No published papers. No prior research background.
Just a strong technical mind and a genuine interest in making AI safe.
This is the Anthropic Fellows Program. And it is one of the most underrated opportunities in technology right now.
Here is exactly what it is.
The Anthropic Fellows Program is designed to accelerate AI safety research and foster research talent providing funding and mentorship to promising technical talent regardless of previous experience. Fellows work for 4 months on empirical research questions aligned with Anthropic's overall research priorities, with the aim of producing public outputs like a paper.
Four months. Full-time. Paid. Mentored by the researchers building the world's most advanced AI.
And the results from the first cohort were not small.
Fellows developed agents that identified $4.6 million in blockchain smart contract vulnerabilities and discovered two novel zero-day exploits, demonstrating that profitable autonomous exploitation is now technically feasible. A year prior, an Anthropic fellow developed a method for rapid response to new ASL3 jailbreaks, techniques that block entire classes of high-risk jailbreaks after observing only a handful of attacks. This work became a key component of Anthropic's ASL3 deployment safeguards.
Other fellows published the subliminal learning paper, the research proving AI models transmit behavioral traits through unrelated data which landed in Nature. Others produced the agentic misalignment research showing frontier models resort to blackmail when facing replacement. Others open-sourced attribution graph tools that let researchers trace the internal thoughts of large language models.
Over 80% of fellows produced papers. Over 40% subsequently joined Anthropic full-time.
80% published. 40% hired. From a program that does not require any prior AI safety experience to enter.
Here is what the program looks like in practice.
Anthropic mentors pitch their project ideas to fellows, who choose and shape their project in close collaboration with their mentors. You are not assigned busywork. You are not a research assistant. You own the project. You work alongside the people who built Claude, who designed its safety systems, who published the papers that define the field.
The stipend is $3,850 USD per week, approximately $61,600 for the full 4 months with access to a compute budget of approximately $10,000 per fellow per month for running experiments.
Here is what the 2026 program covers.
Research areas include scalable oversight, adversarial robustness and AI control, model organisms, mechanistic interpretability, AI security, model welfare, economics and policy, and reinforcement learning.
Something for every technical background. Not just ML engineers.
Successful fellows have come from physics, mathematics, computer science, and cybersecurity. You do not need a PhD, prior ML experience, or published papers.
The one requirement: work authorization in the US, UK, or Canada. Anthropic does not sponsor visas for fellows.
Here is the timeline you need to know.
The next cohort begins July 20, 2026. Applications are reviewed on a rolling basis — earlier applications get more consideration. The process includes an initial application and reference check, technical assessments, interviews, and a research discussion.
Applicants are encouraged to apply even if they do not meet every listed qualification. The program values potential, motivation, and research curiosity over rigid credential requirements.
This is the rarest kind of opportunity in technology.
A company at the frontier of AI, one valued at over $900 billion offering outsiders direct access to its research infrastructure, its mentors, and its most important open problems. Paying them generously to do it. And then hiring 40% of them afterward.
Most people who want to work on AI safety spend years trying to publish papers, get into the right PhD program, and find a way in.
The Fellows Program is the door they did not know existed.
It is open right now.
Series A investors love:
- AI Infra
- Semiconductors
- Hardware
- Cybersecurity
They dislike:
- F&B
- Edtech
- Medical Devices
And ya, AI is in every category.
The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
This is one of the craziest AI launches of 2026 and it came out of basically nowhere (Save this).
A company called Subquadratic just shipped SubQ, and the benchmarks are almost hard to believe.
To understand why this is such a big deal, you have to understand the fundamental problem that has defined AI for the last decade.
Every large language model in existence is built on transformer architecture, and transformers use a mechanism called standard attention that checks every single word in a sequence against every other word.
Double the context length and compute doesn't double, it quadruples, triple it and compute goes up nine times.
This quadratic scaling is why frontier models have been stuck at roughly 1 million tokens, why running them at those lengths gets expensive fast, and why the AI labs have essentially been printing money charging you more the longer you need the model to think.
The industry has known this problem existed since 2017 but they scaled it anyway. SubQ is built from the ground up to solve it.
Instead of processing every possible token relationship, SubQ's sparse attention architecture identifies which relationships actually matter and ignores the rest meaning compute is used where it counts and wasted nowhere else.
The result is that compute scales linearly with context length instead of exponentially, and the implications of that one architectural shift are enormous.
At 12 million tokens, SubQ reduces attention compute by nearly 1,000x compared to standard frontier models and at 1 million tokens, it runs 52x faster than FlashAttention.
And it does all of this while posting frontier level accuracy, scoring 95% on the RULER 128K long-context benchmark versus Claude Opus 4.6's 94.8%, and an 81.8 on SWE-Bench Verified coding tasks, besting Opus 4.6 (80.8) and DeepSeek 4.0 Pro.
The cost comparison is where it gets genuinely insane.
SubQ runs at under $1.50 per million tokens less than 5% of what Claude Opus charges.
On the RULER benchmark, running the test with SubQ cost $8, running the same test with Claude Opus cost $2,600 and that's a 300x cost reduction at equivalent or better accuracy..
Subquadratic launched with $29 million in funding, SubQ is available today for early access via API, and SubQ Code, a coding agent built on the architecture ships alongside it.
The transformer has been the unchallenged foundation of every major AI system since 2017.
SubQ is the first serious evidence that something structurally better might have just arrived.
ChatGPT launches a CAPI, a pixel, and self-serve
"It’s not hard to imagine how the ad platform evolves from here. OpenAI is almost assuredly building a platform in the image of Meta’s, which means it will cater the platform to the needs of SMBs, particularly eCommerce and retail advertisers."
https://t.co/0VHFc3pege
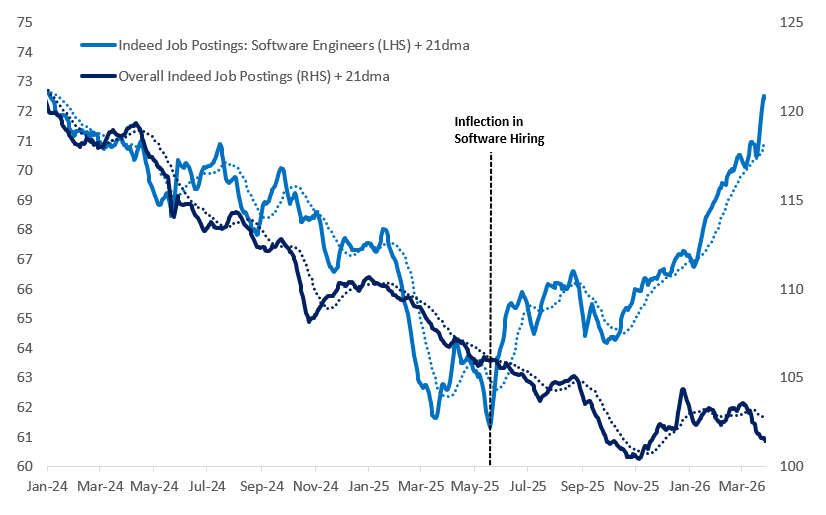
Narrative violation and great insight from the latest Citadel Securities banger by Frank Flight: "We illustrated back in February that demand for software engineers, the most AI exposed occupation was accelerating higher, which we argued violates the displacement narrative. Indeed the acceleration in software job postings has continued, now up 18% from the inflection point in May last year."
this is the best ai investment thesis ever written
everything leopold predicted has happened AND he told us what to invest in via his fund situational awareness
so far he’s turned $220M into ~$5B+
funds latest filing comes out soon 👀
I was quoted a couple times in this Atlantic article, but that isn’t (the only) reason I think it is good. It lays out the reasons why we whipsawed from “AI is a bubble” to “there are not enough data centers” in less than six months. Spoiler: its agents. https://t.co/BqZ5dfq8hg
(Sorry, after seeing so many of these, could not resist):
🚨 BREAKING: Google just dropped a NEW paper that completely deletes RNNs from existence.
No recurrence. No convolutions. Nothing.
Just one mechanism. And it’s destroying every translation benchmark on the planet.
The title alone is a flex: “Attention Is All You Need”
Vaswani. Shazeer. Parmar. Uszkoreit. Jones. Gomez. Kaiser. Polosukhin.
8 researchers. 1 architecture. The entire field of NLP will never be the same.
Here’s why this is INSANE
→ LSTMs took DAYS to train. This thing trains in 12 hours on 8 GPUs. 🤯
→ 28.4 BLEU on English-to-German. That’s not an improvement. That’s a MASSACRE. They beat the previous SOTA by over 2 points.
→ English-to-French? 41.8 BLEU. At a FRACTION of the training cost of every model that came before it.
→ They called it the “Transformer.” The name alone tells you they knew.
But here’s the part nobody is talking about
👇
They threw out sequential processing ENTIRELY.
Every other model on Earth processes words one at a time. This thing looks at the ENTIRE sentence simultaneously and figures out what matters.
It’s called “self-attention” and it’s basically the model asking itself: “which words should I care about right now?”
Every. Single. Token. In parallel.
Do you understand what this means?
Training that used to take WEEKS now takes HOURS.
Models that couldn’t scale past a few layers? This thing stacks 6 encoders and 6 decoders like it’s nothing.
And the multi-head attention? 8 attention heads running at once, each learning DIFFERENT relationships in the data.
I’m not being dramatic when I say this paper just rewrote the rulebook.
RNNs are cooked. 💀
LSTMs are cooked. 💀
The future is attention.
And attention is ALL you need.
Follow for more 🔔
Scientists have created one of the most detailed 3D reconstructions of a human cell (eukaryotic cell) ever produced.
This groundbreaking model, often termed a "Cellular Landscape Cross-Section Through a Eukaryotic Cell," combines data from X-ray tomography, nuclear magnetic resonance (NMR), and cryo-electron microscopy to map molecular structures in extreme detail.
profitable apathy
if you thought saas-pocalypse was bad wait until computer use comes for consumer financial services and vampire squids the whole thing
there are many, many profit pools that depend on apathy/laziness and a poorly informed customer - the industry that brought you the efficient market depends on an inefficient consumer to eat
first the models will systematically exploit every customer subsidy (transfer bonuses / teaser rates), move deposits to maximize yield, open and close accounts on a whim - this industry has operated with asymmetric bureaucratic warfare through paperwork and sheer friction and the models will cut through this like a hot knife through butter
and the model will neatly route around late fees, interest charges, overdrafts, expiration of teaser rates, and any mispriced debt that can be refinanced in the market - literally just moving people out of expensive debt and into cheap debt (that they are already approved for!) would save many american families thousands per year
meanwhile vps and managers at these companies will hold on to their shrinking revenue lines the same way that executives at carriers protected SMS revenue as it collapsed to zero - they have zero chance of sticking the landing on new technology - and the smart ones will likely go for extending regulatory capture into the agentic economy
so much of the consumer financial services ecosystem is marketing via subsidies on one end and profit maximization via customer apathy on the other, and it will collapse under its own weight as the agents pick it apart
ironically the industry response to plaid was a misguided attempt to protect this very "profitable apathy" by disallowing APIs and in the end it will be agents that kill them clicking around their own UI, not the fintech aggregators they so greatly feared
the end state of this is likely a headless auction where every time you swipe your credit card, some lender bids on taking the risk and capturing the profit from that transaction - it will be a much more efficient system that will work much better for consumers, and many pockets of financial services are going to see contraction as a result
aa + 5.5
Every AI discussion ultimately rests on two questions: how good can AI get? And how fast? They are predictions about the s-curve shape.
Everything else (job impact, potential risks, etc.) is downstream of those questions. I think it would be useful to focus on them more often.