FYI to anyone using @MistralAI's Mixtral for long context tasks -- you can get even better performance by disabling sliding window attention (setting it to your max context length)
config.sliding_window = 32768
Transformers now supports Mixtral GPTQs and I've updated my READMEs accordingly. It was awesome working with @_marcsun and @younesbelkada of @huggingface on this!
Credit to LaaZa for coding the AutoGPTQ quant and inference implementation which enabled me to get GPTQs out fast!
Announcing 4-bit Mixtral 8x7B on 🤗Transformers!
Run the new Mistal MoE with minimal performance degradation on your local computer (24Go) 🔥
Stay tuned as more quants are coming soon using AWQ. We are also looking into sparsification with @Tim_Dettmers
https://t.co/Pu4XfpYOmW
@TheBlokeAI joined me to share his work in the open-source AI space - don't miss it! happening right now
server link: https://t.co/C21orV2hzx
(see the general channel or events channel for google meet link)
@MTrofficus You're much too kind - I've merely played a small part in pushing forward the wave. Remember that without the model creators, I'd have nothing to quantise! :) And without the model training code, they'd not be able to train. And so on
We're all doing our bit in our own ways 🚀
Blazing fast text generation using AWQ and fused modules! 🚀
Up to 3x speedup compared to native fp16 that you can use right now on any models supported by @TheBlokeAI
Simply pass an `AwqConfig` with `do_fuse=True` to `from_pretrained` method!
https://t.co/4bbDGPebsC
It's been awesome to see Transformers getting support for more and more quantisation methods. And I've loved collaborating with @younesbelkada and @huggingface again!
All my AWQ uploads now support Transformers. READMEs will update soon to show a Transformers Python example.
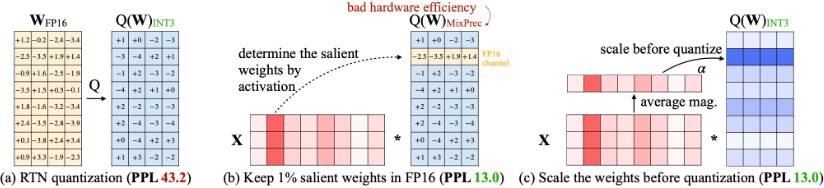
Few months ago, researchers from MIT-Han Lab released AWQ
The method is now supported in 🤗 transformers library !
As simple as 1- `pip install autoawq` or install llm-awq kernels and 2- call `from_pretrained`
A great work from MIT-Han lab folks, Casper Hansen & @TheBlokeAI 🧵
oh hello @TheBlokeAI
I want to bookmark your 'Recent models' Collection on @huggingface 🔥
Well... you can now upvote Collections!
and browse upvoted collections on your profile ❤️
@natserran0 Glad you found the quantization useful. All credit for the quality of the model goes to its creators! And yes that model is still very popular after many months.
Thanks again to @latitudesh for the loan of a beast 8xH100 server this week. I uploaded over 550 new repos, maybe my busiest week yet!
Quanting is really resource intensive. Needs not only fast GPUs, but many CPUs, lots of disk, and 🚀 network. A server that ✅ all is v. rare!
@vanstriendaniel Aw shucks! BTW, are you involved with the Librarian Bot that sends PRs asking people to add base_model to YAML? If so, FYI last week I updated my code so I now link to the source model (the model I quantised) using base_model - hope you can use this data somehow!
🔥Excited to introduce LMSYS-Chat-1M, a large-scale dataset of 1M real-world conversations with 25 cutting-edge LLMs!
This dataset, collected from https://t.co/4LVJjx4pZi, offers insights into user interactions with LLMs and intriguing use cases.
Link: https://t.co/koniYAR4MD
New feature alert in the @huggingface ecosystem!
Flash Attention 2 natively supported in huggingface transformers, supports training PEFT, and quantization (GPTQ, QLoRA, LLM.int8)
First pip install flash attention and pass use_flash_attention_2=True when loading the model!
@SebastianB929@teknium@latitudesh No, I've not tried LMDeploy properly yet. I tried it briefly once but I was getting terrible performance and I didn't have time to investigate it further. I know they claim a lot but I've not been able to verify it myself yet
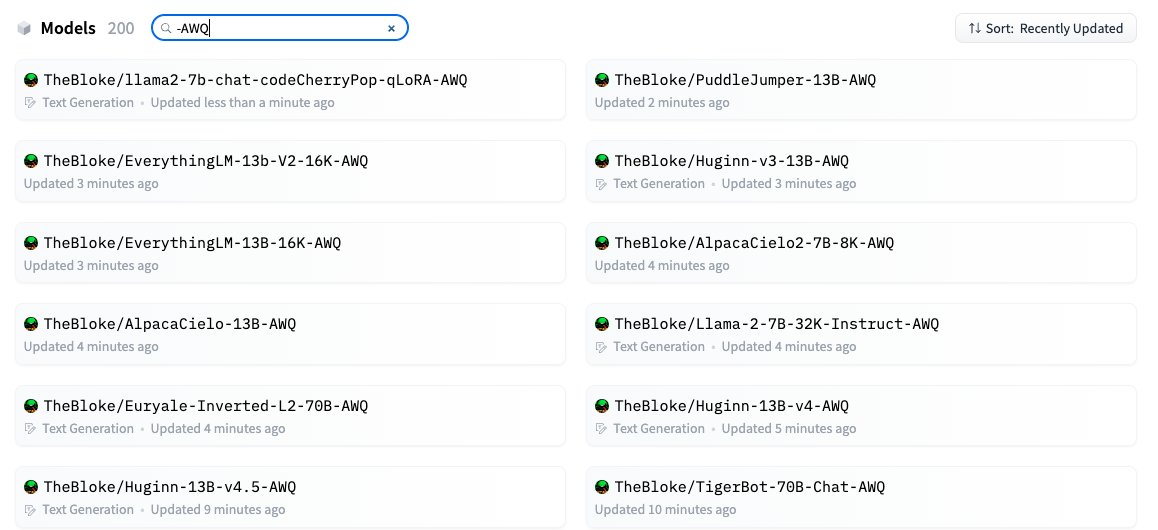
It's the AWQpocalypse!
I've cranked the handle and AWQs are flooding HF. Why now? New library AutoAWQ provides turbo-charged Transformers-based inference, and vLLM now supports AWQ for multi-user inference serving.
Making 8 at once on a beautiful 8xH100 server from @latitudesh
@teknium@latitudesh It can. Currently it doesn't scale quite as well as unquantised, so best performance is still fp16. But it does enable using smaller hardware, which could work out cheaper overall, and often has much easier availability.
@teknium@latitudesh vLLM is a continuous batching server, yes. AWQ is not faster than standalone ExLlama for batch size 1 but in a continuous batching scenario yes it would be - ie vLLM with AWQ will outperform TGI using GPTQ + ExLlama kernel. But for max bsz=1 throughput, ExLlama still rules all.