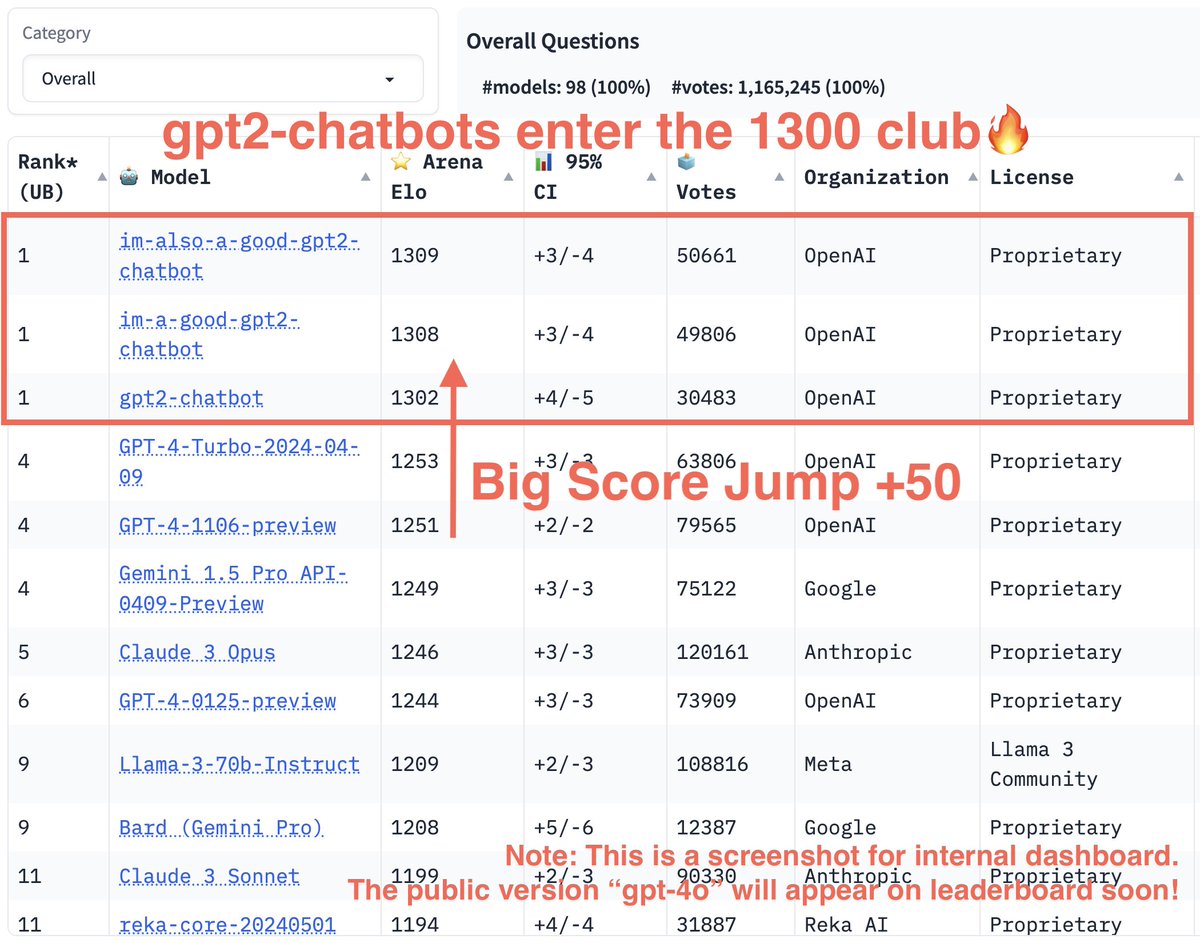
Breaking news — gpt2-chatbots result is now out!
gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Arena!
With improvement across all boards, especially reasoning & coding capabilities, we're excited to see what app can build on top.
Huge congrats to @OpenAI for this incredible milestone!
Note: this is an internal screenshot. Its public version "gpt-4o" is now in Arena and will soon appear on the public leaderboard!
I know your timeline is flooded now with word salads of "insane, HER, 10 features you missed, we're so back". Sit down. Chill. <gasp> Take a deep breath like Mark does in the demo </gasp>. Let's think step by step:
- Technique-wise, OpenAI has figured out a way to map audio to audio directly as first-class modality, and stream videos to a transformer in real-time. These require some new research on tokenization and architecture, but overall it's a data and system optimization problem (as most things are).
High-quality data can come from at least 2 sources:
1) Naturally occurring dialogues on YouTube, podcasts, TV series, movies, etc. Whisper can be trained to identify speaker turns in a dialogue or separate overlapping speeches for automated annotation.
2) Synthetic data. Run the slow 3-stage pipeline using the most powerful models: speech1->text1 (ASR), text1->text2 (LLM), text2->speech2 (TTS). The middle LLM can decide when to stop and also simulate how to resume from interruption. It could output additional "thought traces" that are not verbalized to help generate better reply.
Then GPT-4o distills directly from speech1->speech2, with optional auxiliary loss functions based on the 3-stage data. After distillation, these behaviors are now baked into the model without emitting intermediate texts.
On the system side: the latency would not meet real-time threshold if every video frame is decompressed into an RGB image. OpenAI has likely developed their own neural-first, streaming video codec to transmit the motion deltas as tokens. The communication protocol and NN inference must be co-optimized.
For example, there could be a small and energy-efficient NN running on the edge device that decides to transmit more tokens if the video is interesting, and fewer otherwise.
- I didn't expect GPT-4o to be closer to GPT-5, the rumored "Arrakis" model that takes multimodal in and out. In fact, it's likely an early checkpoint of GPT-5 that hasn't finished training yet.
The branding betrays a certain insecurity. Ahead of Google I/O, OpenAI would rather beat our mental projection of GPT-4.5 than disappoint by missing the sky-high expectation for GPT-5. A smart move to buy more time.
- Notably, the assistant is much more lively and even a bit flirty. GPT-4o is trying (perhaps a bit too hard) to sound like HER. OpenAI is eating Character AI's lunch, with almost 100% overlap in form factor and huge distribution channels. It's a pivot towards more emotional AI with strong personality, which OpenAI seemed to actively suppress in the past.
- Whoever wins Apple first wins big time. I see 3 levels of integration with iOS:
1) Ditch Siri. OpenAI distills a smaller-tier, purely on-device GPT-4o for iOS, with optional paid upgrade to use the cloud.
2) Native features to stream the camera or screen into the model. Chip-level support for neural audio/video codec.
3) Integrate with iOS system-level action API and smart home APIs. No one uses Siri Shortcuts, but it's time to resurrect. This could become the AI agent product with a billion users from the get-go. The FSD for smartphones with a Tesla-scale data flywheel.
We’ve just passed 100 days since the first participant in our clinical trial received his Neuralink implant. Read our latest progress update here: https://t.co/7lckGYCK1H
You are welcome!
1, 2, 3) Cool
4) What I meant is that I was personally a bit confused regarding the messages: "Please sign in to Groq to prompt." and "Login to see prompt results" (inline login form).
By visiting the website first time and getting login screen the user generally expect the need to sign up with email / login + password.
Alternatively user can expect to be presented with a message before typing the email informing her that the password will be generated. Or that there will be no password like in Groq's case.
Something like: "Provide an email address and wait for email message with link" (poor copy to explain quickly what I mean, but you get my point).
Maybe just something like: "Type email address to get the Magic Link" and do not use phase "Login to..." that may be confusing.
Also the "inline form" and "modal form" are slightly different and I do not see the value to show the modal when clicking top link "sign in to Groq". The inline form is already here clearly visible. E.g. some subtle one time animation would do the job by outlining the form or something like that.
You could also just show the input field dimmed / blocked until signed, but I believe it may be on purpose to encourage staying on the website. Fair enough.
Cloud page also has GitHub login option. Anything against to unify those forms? I would consider using it if I would see if earlier as I prefer it than Google for such tech tools. Used the email option otherwise.
Please keep in mind that I focused on people visiting the site for the first time. It personally does not bother me now when I am coming back.
Announcing TypeScript 5.5 Beta! 📣
Now with type predicate inference, more type narrowing, an @import tag for JSDoc, the --isolatedDeclarations flag, performance & reliability improvements, and much more!
https://t.co/wvLzGx5dk2
There is a pretty new GIT client @gitbutler with unique Kanban-like virtual branches approach. Those can be used at the same time without switching. The author is GitHub's co-founder.
I just started using it. I need more time spent and use it in more projects for a better evaluation, but it works pretty nice for now.
https://t.co/sCytr3QICT
Starship completed its rehearsal for launch, loading more than 10 million pounds of propellant on Starship and Super Heavy and taking the flight-like countdown to T-10 seconds
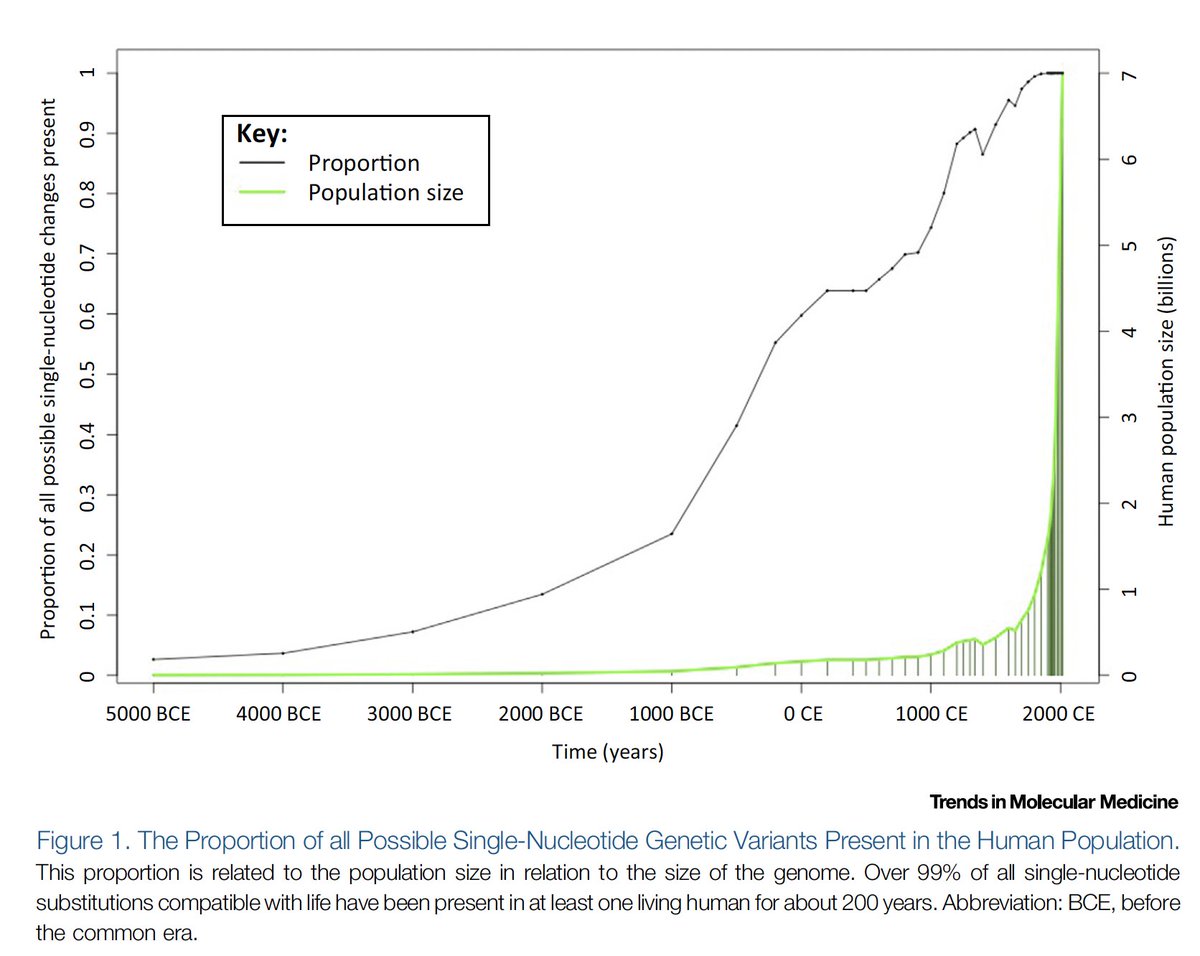
Every mutation that could exist, does exist. That has only been true for ~200 years. Most beneficial variants just haven't had the time to become ubiquitous. But now, at least 50 people in the world have every possible mutation in the human genome.
The progress is clear.
Now I am curious how fast we will see Phoenix walking and when those huge cables connected to the hands will be replaced / hidden.
The #GTC24 session catalog is open: Browse 600+ sessions to see what's in store—from the latest in #generativeAI, accelerated computing, and beyond.
Plus, get an additional 20% off your conference pass when you register with code GTCSAVE20. https://t.co/ynmDeNTHPV
Cutting-edge zero-shot object tracking with OWLv2 ⚡️
https://t.co/qz6PRX7X2P
Just upload a video and the objects you want to look for in a video and let the model track! 🤩
Powered by 🤗 transformers and supervision for annotation part (@skalskip92)
New breakthrough from Microsoft: 1-bit LLMs.
New models that use ternary values (-1, 0, 1) instead of 16-bit.
This makes them 2.7x faster, use 3.5x less GPU memory, and 71x less energy.
Bitnet also matches or outperformed traditional models like LLaMA 3B.