Claude Opus 4.7 just got dethroned by a Chinese AI model.
And nobody's talking about it.
Kimi K2.6:
→ #1 coding model on OpenRouter
→ 7x cheaper than Claude Opus 4.7
→ 100 sub-agents in parallel
→ 1,500 total steps per task
Here's what happens when you build instead of hype
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
عشان تشغل نماذج AI على جهازك فيه برنامجين يعتبرون الأفضل للمبتدئين LM Studio و Ollama. البرنامجين سهلين في التعامل مع كل التفاصيل التقنية المعقدة بالنيابة عنك.
كل اللي عليك تسويه هو تنزيل البرنامج، تختار النموذج اللي تبغاه من قائمة جاهزة، وتضغط زر التحميل. بعد ما ينتهي التحميل، تقدر تبدأ محادثة مع النموذج مباشرة.
مثال LM Studio أول شيء، تروح لموقعهم وتحمل البرنامج على جهازك سواء كان ويندوز أو ماك. بعد ما تشغله، راح تجد واجهة بسيطة فيها مربع بحث. تكتب اسم النموذج اللي تبغى تجربه، مثل Llama 3.
راح تظهر لك قائمة طويلة من النسخ المختلفة من نفس النموذج، كل نسخة تم ضغطها بدرجة مختلفة. كبداية، ممكن تختار أي نسخة يكون في اسمها (Q4_K_M)، لأنها تقدم توازن ممتاز بين الحجم والأداء.
تضغط تحميل، وتنتظر. بعد ما يخلص، تروح لقسم الدردشة في البرنامج، تختار النموذج اللي حملته من القائمة، وتبدأ تسأله أي شيء يخطر في بالك.
بالنسبة لمتطلبات التشغيل، القاعدة الأساسية هي إن حجم ذاكرة الوصول العشوائي (RAM) أو ذاكرة كرت الشاشة (VRAM) لازم تكون أكبر بشوي من حجم ملف النموذج اللي حملته.
لو حملت نموذج حجمه 4 جيجابايت، فأنت تحتاج يكون عندك على الأقل 8 جيجابايت من الرام في جهازك عشان يشتغل بشكل مريح. أغلب أجهزة اللابتوب الحديثة فيها 16 جيجابايت رام، وهذا كافي جداً لتشغيل نماذج بحجم 7 مليار بارامتر (7B).
خلك عارف أن حجم الذاكرة المطلوب بالجيجابايت يساوي تقريباً عدد متغيرات النموذج بالمليار مضروب في حجم المتغير الواحد بالبت مقسوماً على ثمانية.
أيضا لازم تعرف أن النماذج تأتي بأحجام مختلفة، تقاس بالمليارات من الـ Parameters أو المعاملات، مثلًا نموذج Llama 3 منه عدة نسخ منها 8B (ثمانية مليار معامل) و 70B (سبعين مليار معامل).
و كل حجم ممكن يأتي بصيغ ضغط مختلفة مثل Q4, Q6, Q8, FP16. مثلا نموذج بصيغة FP16 معناها كل معامل يحتاج 16 بت.
بالتالي حجم الذاكرة المطلوبة = (عدد المعاملات بالمليار) * (معامل ضغط النموذج / 8)
يعني نموذج بحجم 7 مليار معامل بصيغة FP16 يحتاج حوالي 14 جيجابايت. ( 7 * (16/8)) = 14
طبعاً، كل ما زاد حجم النموذج، زادت دقته وقدرته، لكن في نفس الوقت زاد حجمه واحتياجه لموارد الجهاز. عشان كذا نلجأ للضغط أو Quantization.
مثلاًَ لو ضغطنا نموذج 7 مليار لصيغة 8 بت، حجم الذاكرة راح يقل النصف تقريباً، يعني 7 جيجابايت. وعند ضغطه لـ 4 بت، يقل حجم الذاكرة المطلوب للربع، يعني حوالي 3.5 جيجابايت.
بالمناسبة هذه الحسبة تقريبية، ذاكرة الجهاز ما تحمل فقط أوزان النموذج، نحتاج مساحة إضافية لأشياء أخرى مثل الـ KV Cache اللي يكبر مع طول المحادثة.
القاعدة العامة هي أنك تحتاج دائماً ذاكرة إضافية بنسبة 10 إلى 30 بالمئة فوق الحجم الصافي للنموذج عشان يشتغل بسلاسة.
أيضاً مهم أننا ننتبه لسرعة الذاكرة، أو الـ Bandwidth. هذه هي اللي تحدد سرعة توليد التوكينات. السعة تحدد لك إن كان النموذج راح يعمل، والسرعة تحدد إن كان استخدامه سلس.
كروت الشاشة المنفصلة من إنفيديا، مثل RTX 5090، تملك أعلى عرض نطاق ترددي في السوق، ممكن يصل إلى 1.8 تيرابايت في الثانية.
هذا يخليها قادرة على استدعاء البيانات من الذاكرة بسرعة هائلة، وبالتالي توليد التوكنز بسرعة فائقة. مشكلتها أن سعتها محدودة نسبياً، 32 جيجابايت مثلاً، وهذا راح يكون السقف لحجم النماذج اللي ممكن تشغيلها.
في المقابل، أجهزة أبل مثل Mac Studio M3 Ultra تعتبر حل وسط. عرض النطاق الترددي فيها أقل، حوالي 800 جيجابايت في الثانية، لكنها تتيح لك الوصول إلى ذاكرة موحدة ضخمة تصل إلى 512 جيجابايت.
هنا أنت تضحي بجزء من السرعة القصوى مقابل القدرة على تشغيل نماذج عملاقة جداً لا يمكن أن تتسع في أي كرت شاشة استهلاكي.
أيضاً فيه فئة جديدة بدأت تظهر، وهي أجهزة الكمبيوتر بمعالجات مثل Strix Halo من AMD، واللي تقدم ذاكرة موحدة بسعة كبيرة تصل إلى 96 جيجابايت وعرض نطاق ترددي مقبول نسبياً، حوالي 256 جيجابايت في الثانية.
هذه تمثل أول محاولة حقيقية لتقديم حل متكامل في عالم x86 ينافس فلسفة أبل.
بالنسبة لـ AI PC أو أجهزة اللابتوب الخفيفة، فعرض النطاق الترددي فيها يعتبر منخفض جداً، وهذا يجعلها مناسبة للمساعدات الصغيرة والمهام البسيطة، وليس لتشغيل النماذج القوية.
واذا كان عندك وقت وحاب تتعلم أكثر عن موضوع تشغيل نماذج الـ AI على جهازك راح أضع لك مقالين نصيحة أقرأهم راح تتعلم كثير خصوصا موضوع حساب الذاكرة ، كل ما كتبته هنا أخذته من هذين المقالين .
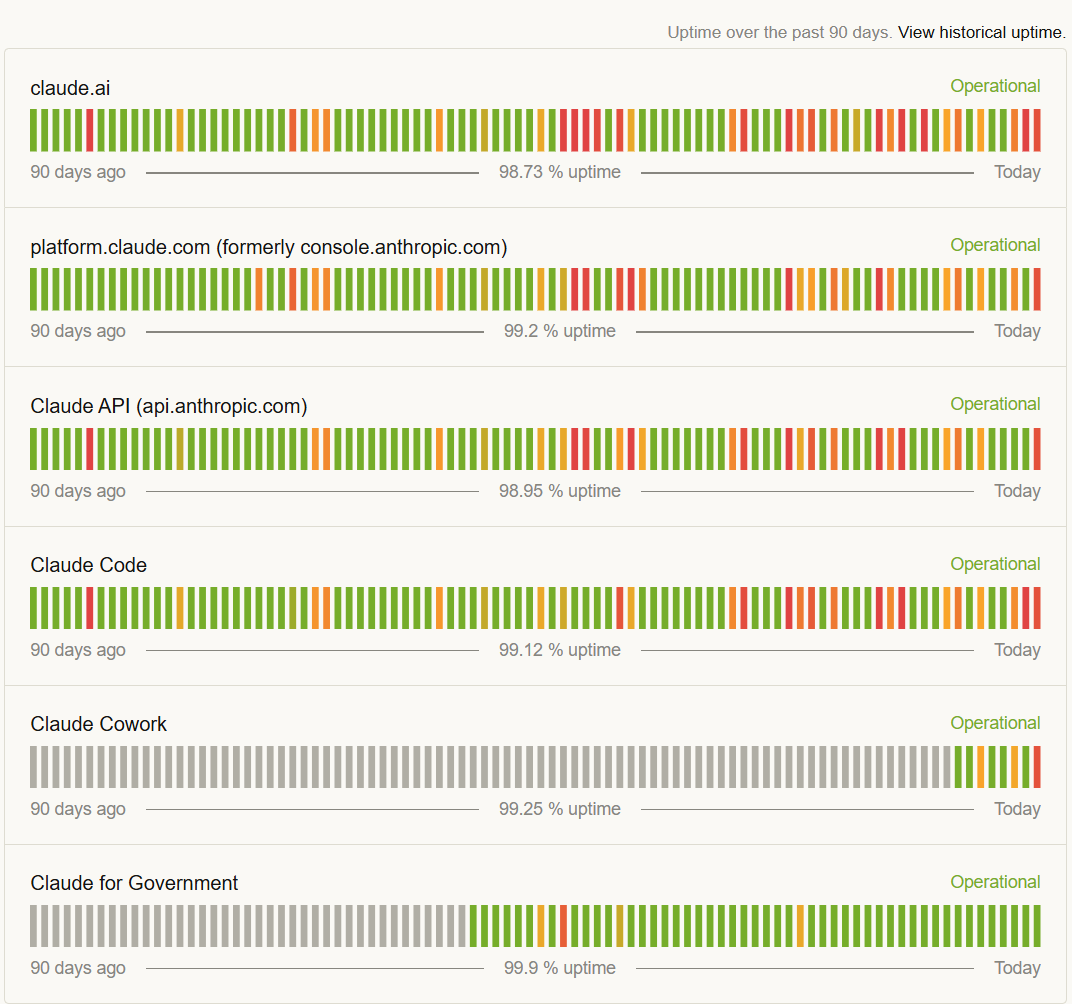
@claudeai That's cool and all but your entire status page is orange right now. Shipping new products while https://t.co/URY9MRDn51, Claude Code, Cowork, and the API are all showing Degraded Performance simultaneously is certainly a choice. 🙄
Anthropic banned OpenClaw from using Claude subscriptions 4 days ago
Today they just launched their own managed agents platform
So basically OpenClaw without all the headache and cheaper usage
Introducing Qwen3.6-Plus: Towards Real-World Agents!
Here is what makes Qwen3.6-Plus a game-changer:
· Next-level Agentic Coding
· Enhanced Multimodal Vision
· Top-tier Performance:
· 1M Context Window
Noted: More Qwen3.6 models to come and be open-sourced! Stay tuned!
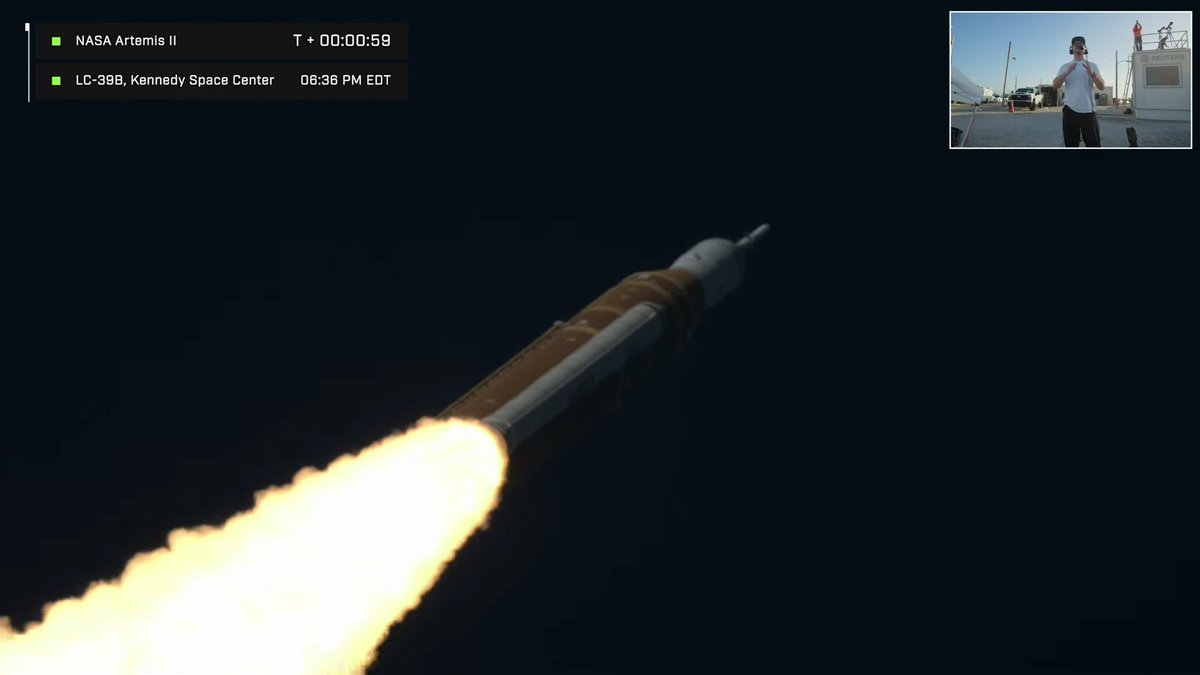
NASA appears to be centralizing a lot of their high-resolution Artemis II media at this link. A good one to keep in your bookmarks.
https://t.co/5xBvnDaB92
Everyday Astronaut (arriba) VS Director oficial de la NASA (abajo).
Que un youtuber sea capaz de darnos mejores imágenes que la agencia espacial más importante del mundo no tiene ningún sentido.
🤦♂️🤦♂️🤦♂️
This is a truly incredible shot, especially given that the NASA live feed chose to show video of the cheering crowd right at the exact moment of solid rocket booster separation…
Brilliant to see the Artemis II mission launch @NASA - but for the love of all things space, spend a few $$ more on the cameras next time 'eh and perhaps talk to @SpaceX about @Starlink ? If this is the pinnacle of your technology isn't it a touch embarrassing?