the engineer who built Claude Code just dropped a 28-minute video on how to write prompts that actually work
I've seen $300 courses that don't cover what he shows in the first 10 minutes
CLAUDE.md files, memory shortcuts, parallel sessions, prompting patterns
all in one video and completely free
works whether you're a developer, a beginner, or someone who's been using Claude for months
based on this, I put together 18 things you can copy and use in Claude today
full guide in the article below
RL isn't always the right answer!
(Berkeley beat GRPO without a GPU)
Same task, same base model, 10 points higher on the benchmark.
The technique is called 𝗚𝗘𝗣𝗔. It came out of Berkeley in mid-2025, got accepted at ICLR 2026, and is now a first-class optimizer in DSPy.
The reason it works points at something most teams get wrong about reinforcement learning on language models.
Every team running agents in production is sitting on a pile of rollouts. A rollout is just one full run of your agent on a task, from the user query down to the final answer, with everything that happened in between.
Most teams have thousands of these traces and no real idea what to do with them beyond eyeballing a few when something breaks.
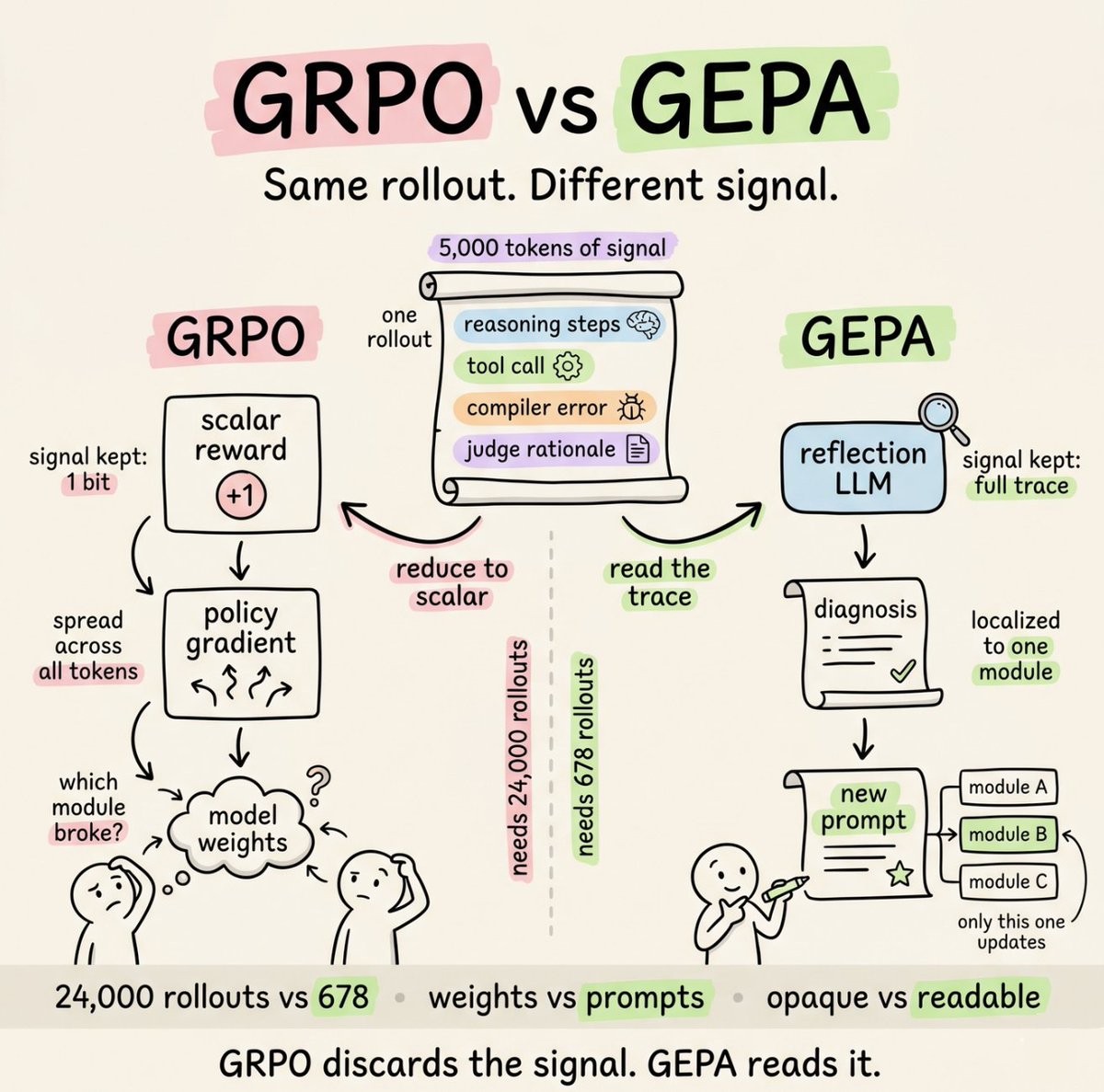
This is the part worth paying attention to. Each rollout is roughly a 5,000-token document containing reasoning steps, tool calls, compiler errors, and judge rationales. Rich, structured, and full of signal.
𝗚𝗥𝗣𝗢 compresses all of that to +1 or -1, scalar reward signal.
That single bit gets back-propagated across every token in the policy. The information that told you what went wrong and where gets thrown away on the way to the gradient.
This is why RL needs tens of thousands of rollouts to converge. The signal was never sparse, the optimizer made it sparse.
𝗚𝗘𝗣𝗔 reads the trace instead.
A reflection LLM ingests the full rollout, diagnoses the failure, localizes it to one module in the pipeline, and rewrites that module's prompt.
Same rollout, vastly more signal extracted. Weights become prompts, and opaque becomes readable.
This is also why GEPA shines on multi-module workflows. Most real agents are pipelines of several modules glued together, and GEPA lets you target the exact module you want to improve instead of nudging the whole system at once.
The honest framing is this. RL changes what the model knows, while GEPA changes how you ask.
If your base model genuinely can't do the task, no prompt evolution will save you and you should fine-tune.
But most of what teams currently route to GRPO is the second case, not the first. The model can already do it, and the prompt is the bottleneck.
Reading a rollout costs less than running ten thousand more.
If you want to go deeper, here's the paper and the DSPy implementation:
Paper: https://t.co/csPm64ZKNp
GEPA in DSPy: https://t.co/Bhkj3csq1G
The article below is a deep dive into exactly how GEPA works. Do give it a read.
April was a pretty strong month for LLM releases:
- Gemma 4
- GLM-5.1
- Qwen3.6
- Kimi K2.6
- DeepSeek V4
All are now added to the LLM Architecture Gallery.
More details once I am fully back in May!
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
🔹 Amid recent attention, a quick reminder: please rely only on our official accounts for DeepSeek news. Statements from other channels do not reflect our views.
🔹 Thank you for your continued trust. We remain committed to longtermism, advancing steadily toward our ultimate goal of AGI.
7/n
This 30-minute speech by the Head of Anthropic "Coding Agents" researcher will teach you more about vibe coding than 100 paid courses.
Bookmark it & give it 30 minutes today. This video will change the way you use AI forever,
In 14 minutes, this Anthropic engineer who wrote "Building Effective Agents" will
teach you more about building them right than most developers figure out on their own
in months.
Bookmark this for the weekend. Then read the builder's guide below.
🚨 ElevenLabs charges $5 to $99/month for AI voice cloning. Their Business plan costs $1,320/month.
Someone open sourced a voice AI that clones any voice from a short clip. 30 languages. Studio quality. Free.
It's called VoxCPM2.
Give it a short clip of anyone's voice. It clones their accent, emotion, tone, and pacing. Then generates any speech you want in their exact voice. 48kHz studio quality.
Type "A young woman, gentle and sweet voice" and it creates that voice from scratch. No reference audio. No voice actor. No recording. You describe a voice in words. It builds it.
2 billion parameters. Trained on 2 million hours of speech. 30 languages.
One command to install: pip install voxcpm
Here's what VoxCPM2 does:
→ Voice Design: describe any voice in words. Gender, age, tone, emotion, pace. AI creates it from nothing. No reference audio needed.
→ Voice Cloning: upload a short audio clip. AI clones the voice perfectly. Timbre, accent, rhythm, pacing.
→ Controllable Cloning: clone a voice AND control the emotion. "Slightly faster, cheerful tone." Done.
→ Ultimate Cloning: provide audio + transcript. Every vocal nuance faithfully reproduced.
→ 30 languages. Arabic, Chinese, English, French, German, Hindi, Japanese, Korean, Spanish, and 21 more. No language tags needed.
→ Context-aware. It reads the text and adjusts emotion and rhythm automatically. News sounds like news. Stories sound like stories.
→ Real-time streaming. RTF as low as 0.13 on an RTX 4090. Faster than playback speed.
→ Runs on 8GB of VRAM.
→ Fine-tune with 5 to 10 minutes of your own audio using LoRA. Build a custom voice model.
→ 48kHz output. Studio quality. No external upsampler needed.
Here's the wildest part:
On the Minimax-MLS voice similarity benchmark:
→ English: VoxCPM2 scores 85.4%. ElevenLabs scores 61.3%.
→ Chinese: VoxCPM2 scores 82.5%. ElevenLabs scores 67.7%.
→ Arabic: VoxCPM2 scores 79.1%. ElevenLabs scores 70.6%.
A free, open source model is producing more realistic voice clones than a service that charges up to $1,320/month.
Professional voice actors charge $250 to $1,000+ per project. AI voice platforms charge $5 to $100/month. Recording studios charge $200/hour.
This runs on your GPU. Locally. No API costs. No per-character pricing. No subscription. Free forever.
Already hit #1 on GitHub Trending. Built by OpenBMB and Tsinghua University. 2 billion parameters. Apache 2.0 License. Free for commercial use.
100% Open Source.
Chris Manning says Yann LeCun sees language as a low bandwidth communication channel compared to vision.
But the gap between a chimp and a human wasn’t produced by superior eyes.
What took off for humans was language.
Not just for communication, but as a cognitive tool.
Gemma 4 watches raw video. Understands the scene. Then prompts SAM 3 to segment and RF-DETR to track.
One AI directing two others. Fighter jets. Crowds. Aerial defense footage.
All three models running locally on a MacBook. No cloud.
What scene should I point this at next?
🚨 BREAKING: NVIDIA just removed the biggest friction point in Voice AI
They open-sourced PersonaPlex 7B, a real-time conversational model. It listens and speaks simultaneously to handle natural interruptions and overlaps.
100% Open Source.
Google just dropped TurboQuant, and I'm about to get so much more out of my Mac Mini now lol.
It makes LLMs 6x smaller and 8x faster with zero quality loss.
Now I can run insane AI models locally for free.
→ Bigger context windows
→ Way faster processing
→ Completely secure
Google could have kept this to themselves. They didn't.
Huge respect for pushing the entire industry forward.
We're just 3 months into 2026 and so much has been happening already.
If you're not paying attention, you're already behind.
RIP OpenClaw 💀
Claude now has
> Voice mode
> Agent Teams
> 38+ Connectors
> Cowork Projects
> Scheduled tasks
> Plugin Marketplace
> Persistent memory
> 1M Context window
> Dispatch for remote control
> Channels for Telegram & Discord
> Claude can use computer to run apps💀
I've been working on a new LLM inference algorithm.
It's called Speculative Speculative Decoding (SSD) and it's up to 2x faster than the strongest inference engines in the world.
Collab w/ @tri_dao@avnermay. Details in thread.
🚨 Holy shit… Google published one of the cleanest demonstrations of real multi-agent intelligence I’ve seen so far.
Not another “look, two chatbots are talking” demo.
An actual framework for how agents can infer who they’re interacting with and adapt on the fly.
The paper is “Multi-agent cooperation through in-context co-player inference.”
The core idea is deceptively simple:
In multi-agent environments, performance doesn’t just depend on the task.
It depends on who you’re paired with.
Most current systems ignore this.
They optimize against an average opponent.
Or assume fixed partner behavior.
Or hard-code roles.
Google does something smarter.
They let the model infer its co-player’s strategy directly from the interaction history inside the context window.
No retraining, separate belief model and no explicit opponent classifier.
Just in-context inference.
The agent observes a few rounds of behavior. Forms an implicit hypothesis about its partner’s type. Then updates its own strategy accordingly.
This turns static policies into adaptive ones.
The experiments are structured around cooperative and social dilemma games where partner types vary:
Some partners are fully cooperative.
Some are selfish.
Some are stochastic.
Some strategically defect.
Agents without co-player inference treat all partners the same.
Agents with inference adjust.
And the performance gap is significant.
What makes this paper uncomfortable for a lot of current “multi-agent” hype is how clearly it shows what real coordination requires.
First, coordination is not just communication. It’s modeling the incentives and likely actions of others.
Second, robustness matters. An agent that cooperates blindly gets exploited. An agent that defects blindly loses cooperative gains. The system must dynamically balance trust and caution.
Third, adaptation must happen at inference time. In real deployments, you cannot retrain every time the population changes.
The most interesting part is that this capability emerges purely from structured context.
The model isn’t fine-tuned to classify opponent types explicitly. It uses behavioral traces embedded in the prompt to infer latent strategy.
That’s belief modeling through language.
And it scales.
Think about where this matters outside toy games:
Autonomous trading systems reacting to different market participants.
Negotiation agents interacting with unpredictable humans.
Distributed AI workflows coordinating across departments.
Swarm robotics where teammate reliability varies.
In all these settings, static competence is not enough.
Strategic awareness is the bottleneck.
The deeper shift is philosophical.
We’ve been treating LLM agents as isolated optimizers.
This paper moves us toward agents that reason about other agents reasoning about them.
That’s recursive modeling.
And once that loop becomes stable, you no longer have “a chatbot.”
You have a participant in a strategic ecosystem.
The takeaway isn’t that multi-agent AI is solved.
It’s that most current systems aren’t even attempting the hard part.
Real multi-agent intelligence isn’t multiple prompts in parallel.
It’s adaptive belief formation under uncertainty.
And this paper is one of the first clean proofs that large models can do that using nothing but context.
Paper: Multi-agent cooperation through in-context co-player inference
🚨 BREAKING: A developer on GitHub just built a tool that turns any GitHub repo into an interactive knowledge graph and open sourced it for free.
It's called GitNexus. Think of it as a visual X-ray of your codebase but with an AI agent you can actually talk to.
No server. No subscription. No enterprise sales call.
Here's what it does inside your browser:
→ Parses your entire GitHub repo or ZIP file in seconds
→ Builds a live interactive knowledge graph with D3.js
→ Maps every function, class, import, and call relationship
→ Runs a 4-pass AST pipeline: structure → parsing → imports → call graph
→ Stores everything in an embedded KuzuDB graph database
→ Lets you query your codebase in plain English with an AI agent
Here's the wildest part:
It uses Web Workers to parallelize parsing across threads so a massive monorepo doesn't freeze your tab.
The Graph RAG agent traverses real graph relationships using Cypher queries not embeddings, not vector search. Actual graph logic.
Ask it things like "What functions call this module?" or "Find all classes that inherit from X" and it traces the answer through the graph.
This is the kind of code intelligence tool enterprise teams pay thousands per month for.
It runs entirely in your browser.
Works with TypeScript, JavaScript, and Python.
100% Open Source. MIT License.
Repo: https://t.co/RzIoLR2vAe
🚨 Someone just built a tool that turns any GitHub repo into an interactive knowledge graph and open sourced it for free.
It's called GitNexus. Think of it as a visual X-ray of your codebase but with an AI agent you can actually talk to.
Here's what it does inside your browser:
→ Parses your entire GitHub repo or ZIP file in seconds
→ Builds a live interactive knowledge graph with D3.js
→ Maps every function, class, import, and call relationship
→ Runs a 4-pass AST pipeline: structure → parsing → imports → call graph
→ Stores everything in an embedded KuzuDB graph database
→ Lets you query your codebase in plain English with an AI agent
Here's the wildest part:
It uses Web Workers to parallelize parsing across threads so a massive monorepo doesn't freeze your tab.
The Graph RAG agent traverses real graph relationships using Cypher queries not embeddings, not vector search. Actual graph logic.
Ask it things like "What functions call this module?" or "Find all classes that inherit from X" and it traces the answer through the graph.
This is the kind of code intelligence tool enterprise teams pay thousands per month for.
It runs entirely in your browser. Zero server. Zero cost.
Works with TypeScript, JavaScript, and Python.
100% Open Source. MIT License.