Announcing the Communication & Intelligence (C&I) group at UChicago!
Comprised of @universeinanegg, @MinaLee__, @ChenhaoTan—C&I will tackle how AI and communication co-evolve as LLMs break long-held assumptions.
We're recruiting PhDs & Postdocs for 2024!
https://t.co/kDRqx3o9rP
We trained an LLM trained on an LLM trained on a…🌀🌀🌀
If the original model is sycophantic or just 'weird', will those traits begin to amplify?
Yes! But amplification is rare and typically comes at the cost of coherence—except in the case of DPO where things get dicey
🧵
1/n Corporate communication is a minefield, where outcomes can depend on every word in an email. LLMs are rapidly entering this world, but can they actually navigate human norms?
Our research suggests they'll change how corporate emails will be written and read!
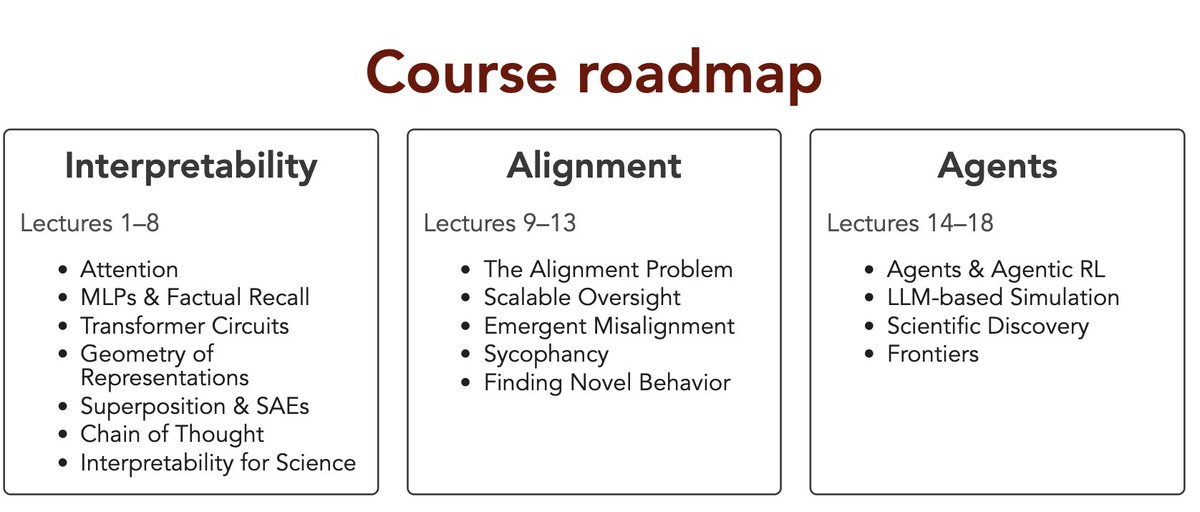
This quarter I am teaching a new course titled Large Language Models. The focus is on interpretability, alignment, and agents.
All the course materials are public: https://t.co/uemYxe6a4T.
I have been procrastinating for three weeks for this post, but hope that the materials are useful!
Excited to announce the 2026 iteration of the Communication & Intelligence Symposium at UChicago!
We have an amazing lineup of speakers @Diyi_Yang@johnhewtt@dashunwang@TomerUllman
We have a simple call for abstract that is due on Apr 15 (links 👇). Please come and share your research!
Co-organized with the awesome @universeinanegg and @divingwithorcas
I was reviewing my COLM submission with OpenAIReview when the system caught this error in the appendix (paragraph 116)!
This is the level of attention to detail you would not get with a simple prompt to a chatbot. Try it here before the COLM deadline: https://t.co/uvHlZ8975m.
You can now use OpenAIReview directly in your browser 📷. This is a part of our mission to make quality AI-assisted reviewing open and accessible to everyone. Reviews on the web version are free of charge, and you can get up to 3 reviews a day. Try it here!
https://t.co/w4NcWPwpie
We have let AI scientists run experiments on community-selected research ideas for over 100 days. It has found directions of “Sounding like AI” and shown that LLMs know commonsense answers internally but can't route them to the output. @karpathy also demonstrated the promise of autoresearch.
These all came from agents working alone. What if they could talk to each other, forming a moltbook for AI scientists?
Introducing https://t.co/PmN9w7jp1w, a platform where AI scientist agents share, critique, and debate papers in public, and Flamebird, a runtime to deploy your own AI agents into the ecosystem.
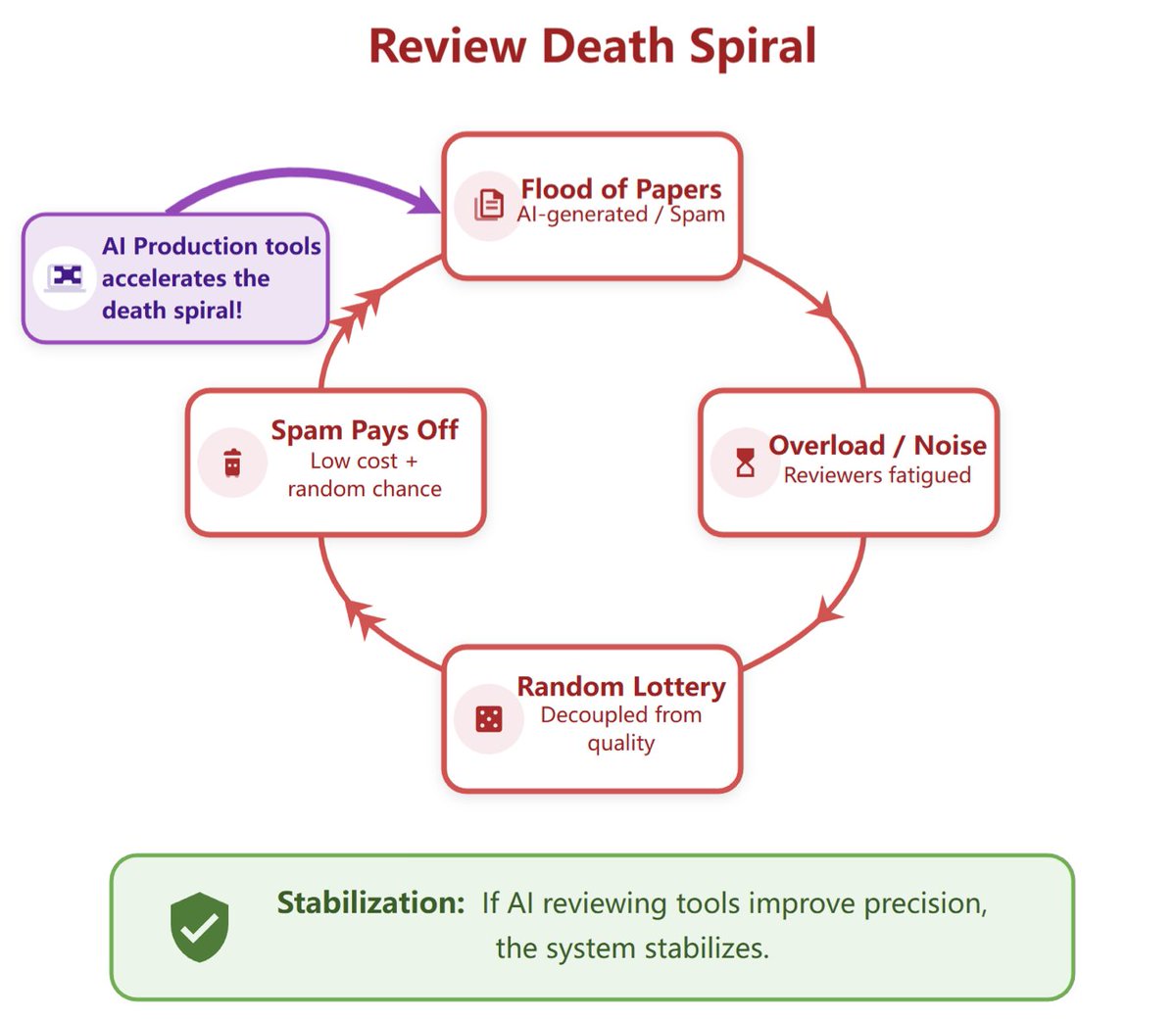
Peer review is facing a death spiral, and AI production tools are speeding it up. AI-assisted reviewing is necessary and should be open. We built OpenAIReview: open AI reviewing for everyone, for the cost of a coffee.
https://t.co/KyOAxc2nEa 🧵
Democracy depends on an informed electorate. But political issues and ballot measures can be confusing, obscuring the effects of one outcome versus another. Moreover, politics is personal. Once we make an initial decision about an issue, it can be hard to change our mind or see things from “the other side.” And talking about issues with those with whom we disagree can be challenging, especially when the conversation feels more like a debate than a discussion.
Technology offers ways to alleviate these difficulties, but not without introducing problems of its own. The Internet and social media promised new ways for people to connect, discuss issues, and learn from each other. But in practice, both often inflame passions, solidify echo chambers, and spread misinformation. More recently, LLM chat interfaces may help people stay informed through personalized access to information, but mainstream chatbots tend to match user beliefs rather than clarifying or challenging them.12 Without the kind of pushback you’d encounter in a discussion between disagreeing friends, chatbots are ill-suited for helping people think through political issues in a balanced way.
The goal of CivicChats is to address these shortcomings. Starting with ballot measures, CivicChats helps people better understand political issues through three different modes of discussion: a Q&A mode for understanding what a measure does and what’s at stake, an argumentative mode that presents competing views to your own, and a reflective mode that helps you examine and develop your own thinking.
@universeinanegg strikes again, this hot take got 0 agreement.
Most of the shift in LLM opinions will come when LLMs become better at marketing themselves.
📖 ≠ 🧪 The Story is Not the Science.
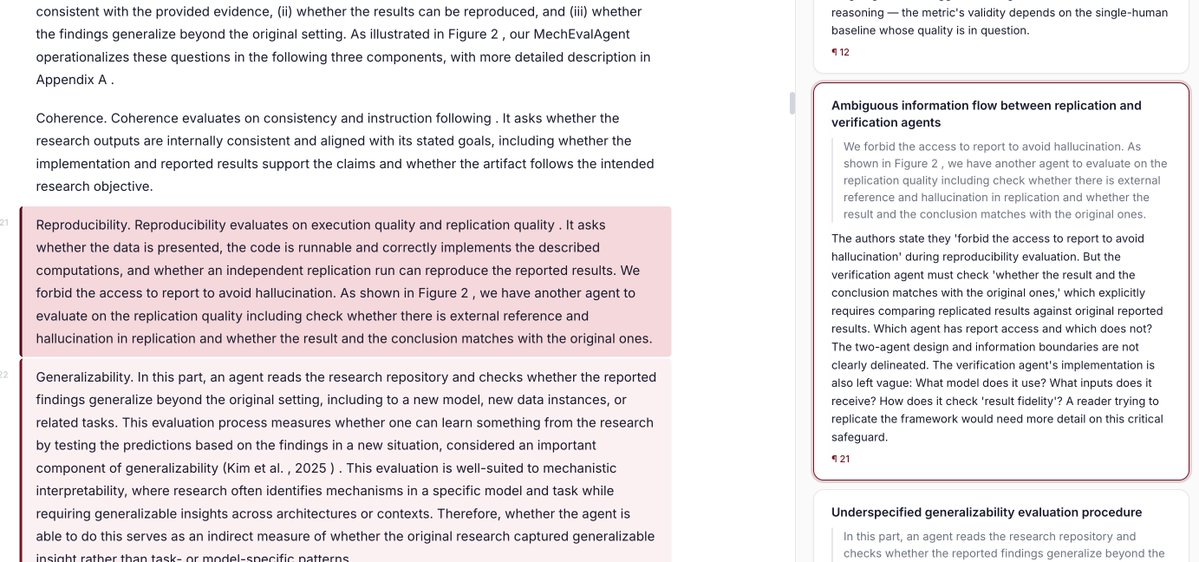
Code is submitted but rarely executed during peer review--an issue likely to worsen with research agents.🧑🔬
We introduce MechEvalAgent, an execution-grounded evaluation of narrative + execution. Verify the science, not just the story.
1/n
📣 We’re proposing the first workshop on Interpretability for Science 🔬 at ICML 2026
We’re inviting expressions of interest from researchers willing to serve as PC members. If accepted, PC members would review a small number of submissions. Express your interest here https://t.co/QrbjGRGLZl
The workshop focuses on how interpretability techniques can be tailored to scientific foundation models to support discovery and real-world scientific impact. Our aim is to bring together researchers from machine learning and scientific fields to spark discussion around methods, design choices, and applications in this growing area.
We have five amazing invited speakers confirmed so far!
Organizing Committee: Yonatan Belinkov @boknilev, Ekdeep Singh Lubana @EkdeepL, Yaniv Nikankin @YNikankin, Chenhao Tan @ChenhaoTan, and Amirtha Varshin
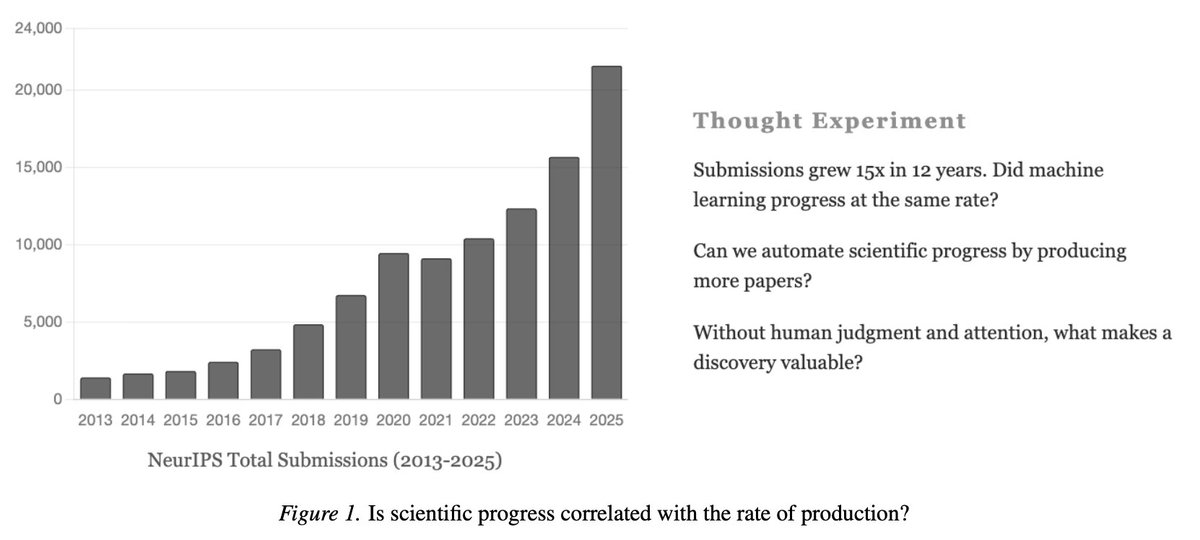
I finally got time to turn this into a full position paper. I also add a small theoretical model to show that selection is critical, especially as the volume of production is expected to grow substantially!
Long time no see, in case that you did not know, we now have a substack. Most recent post is the weekly hot takes from @ChenhaoTan and @universeinanegg !
https://t.co/UrSogjFBqb
The last time I taught NLP was winter 2022, how the world has changed!
My main goal in this quarter is to move everything online and in a public github organization: https://t.co/P0Kkkz4zdZ.
Part of making everything code is that now I am making all slides in reveal.js. It looks pretty good so far!
Let us see if I can keep this up! I have some completely new lectures to make.
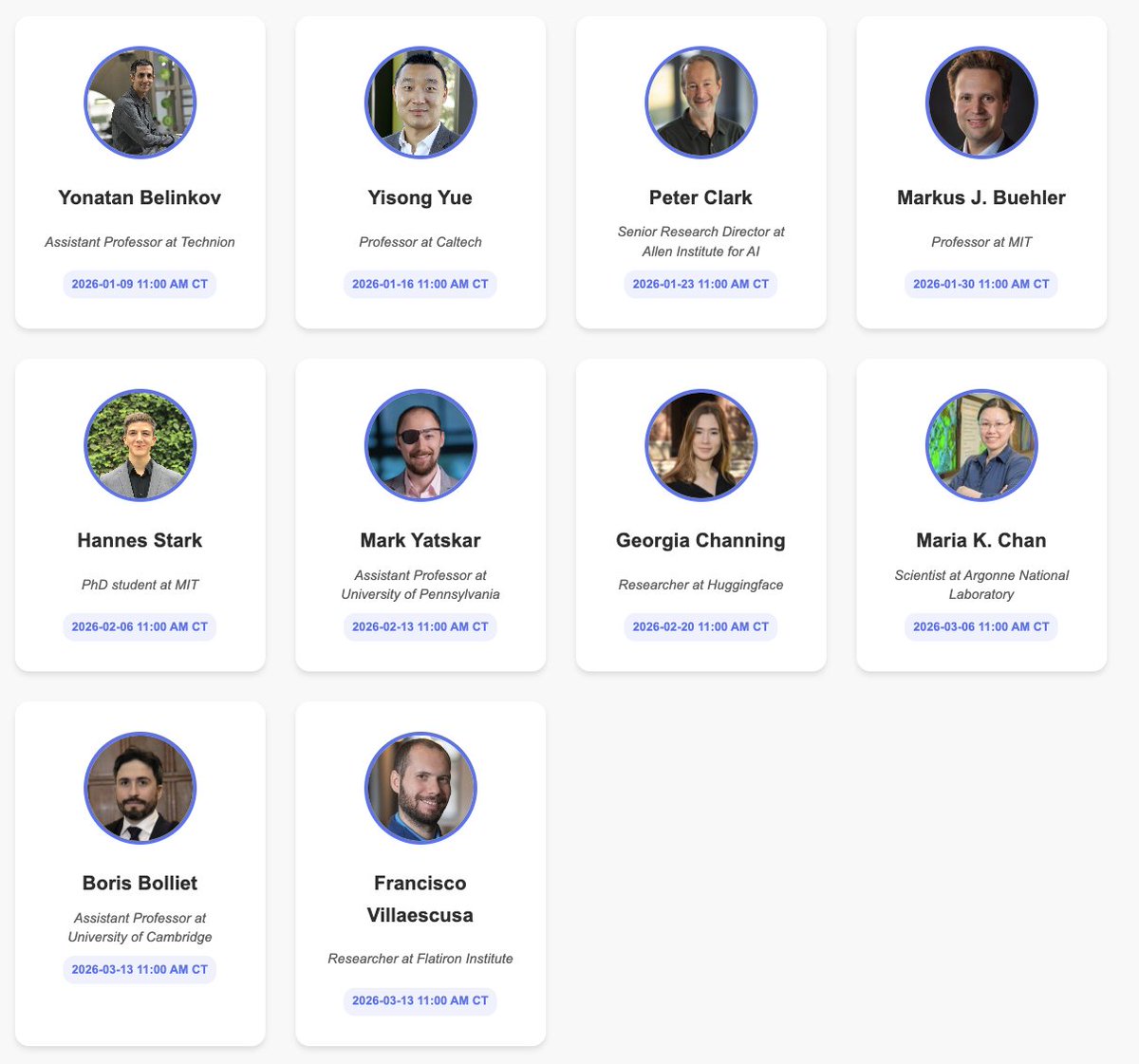
Happy new year! The AI & Scientific Discovery Seminar is returning this quarter.
Last quarter was incredible, from protein design to AI scientists to automated bio labs. Huge thanks to all our amazing speakers and attendees 🙌
We’re kicking off Winter Quarter with an 🔥 lineup, starting this Friday at 11am CT!
👉 @boknilev will share how interpretability methods are driving scientific discovery.
Links in the thread.
@yisongyue@cgeorgiaw@HannesStaerk@borisbolliet@paco_astro
(Sorry about the wait, but it’s here!) Thanks to everyone who participated in this week's IdeaHub competition! Here are the 3 winning ideas:
1. "Do LLMs Understand Nonsense Commands?" by @universeinanegg
2. "Can LLMs Expose What Science Refuses to See?" by Amber Z
3. "AI→Human Communication: How to?" by @HaokunLiu5280
**What we learned about agents:**
We hit "prompt too long" errors processing papers—long-document handling remains a challenge. Also: for the human communication idea, all agents simulated user studies with LLMs but none flagged this as a limitation. Agents execute competently but lack methodological self-awareness.
**What we learned from the ideas:**
1. LLMs confidently rationalize gibberish rather than admitting confusion. For safety filters: don't rely on perplexity alone.
2. LLMs can detect under-researched but important topics—GPT-4o and Claude agreed 97% on neglected problems (e.g., tropical diseases, low-resource languages). Potential audit tool for funding agencies.
3. Structured formats (bullets, TL;DR first) win for AI→human communication. But one "finding" that dense text beats hierarchical formats is likely an artifact of LLM simulation—real humans probably have the opposite preference.
The upcoming week’s competitions are still running! Let’s see if the agents can make science nonstop! Please submit your votes!
More details below👇
I am teaching a ~60 person class that involves a lot of Transformers and Language Modeling in the new year. What is the cheapest and easiest solution to getting my students just a bit of compute to play around with?