Whoa—my book is up for pre-order!
Model to meaning: How to interpret Statistical & ML Models in #RStats and #PyData
The book presents an ultra-simple and powerful workflow to make sense of ± any model you fit
Note: The web version stays free forever.
https://t.co/fpDmSdDWov
We have a new version of this paper out. The headline results are the same—political science must filter results heavily for statistical significance—but we've added many extensions and rewritten much of it in response to feedback (thank you!).
A quick thread on updates 👇
@adamaltmejd@haozhu233 Exactly! I'm putting a detailed spec together and starting to think about tooling. Maybe I'll ping you for feedback if you're interested.
@adamaltmejd@haozhu233 Ideally, these things should be reported in the paper, but Many-Analyst Projects showthis is far from the case. I think that if we can have a LLM assisted workflow to create "candidate decisions" and have humans approve them, that could be really useful. LLM-powered Lab notebook
@adamaltmejd@haozhu233 I mean more: "We report clustered standard errors at the level of random assignment: villages", with some justification and reference to literature, and link to the code line where this is done.
@adamaltmejd@haozhu233 Yeah, right. But an important desideratum is to distinguish "state" from "decision". I want a record of "analysis decisions" that could then be compared to code state by an agent to check for faithfulness. The LLM seeds "candidate decisions" that need explicit human approval.
@haozhu233 Yes, of course. But I was more thinking about something along the lines of a Architecture Decision Record, that the user "approves." Include both choice & justification. The AI can refer to it when implementing and to verify faithfulness. And humans can eval high level decisions.
@KyleLHandley@bechhof Instead of throwing insulting complaints up on social media ("anyone who picks up a textbook"), perhaps you could ask the maintainer (me) it we could convert the error into a warning. I am always happy to engage with users, listen to feedback, and fix (potentially) bad decisions.
Say I wanted ~9k USD to buy out the teaching time of a prof (a brilliant coauthor of mine) so he can work on creating a validated ground truth dataset for a challenging data extraction and labelling task that current public LLMs (e.g. GPT5) have not yet saturated. Who do I pitch?
Discover how rare it can be to uncover meaningful effects in political science research in this week’s episode of Not Another Politics Podcast. Listen here: https://t.co/Z9PiMTKGUW
Whoa—my book is up for pre-order!
Model to meaning: How to interpret Statistical & ML Models in #RStats and #PyData
The book presents an ultra-simple and powerful workflow to make sense of ± any model you fit
Note: The web version stays free forever.
https://t.co/fpDmSdDWov
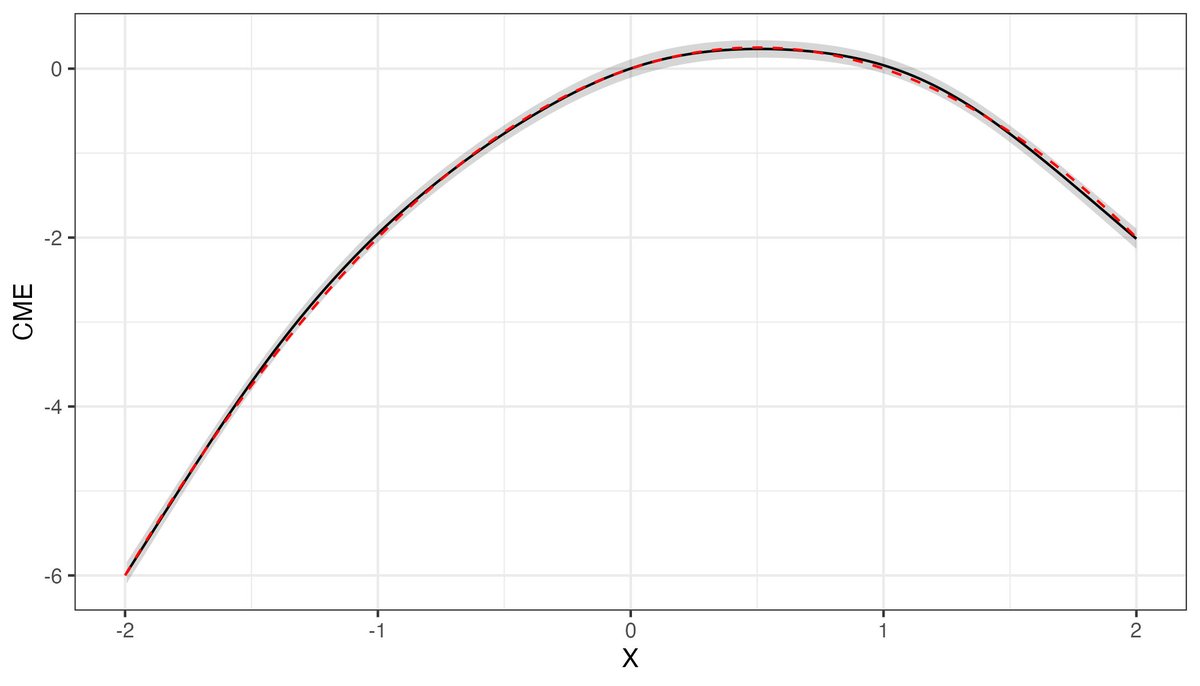
@xuyiqing I've been playing with your ideas for Step 2 and found a super cute 1-liner. Using the `transform` argument of the `comparisons` function, we can spline dydx immediately, instead of using cumbersome bins. Not sure this is actually useful, but it's too cool not to post!
@xuyiqing Oh yeah, doubly-robust is the good stuff! I also really like the part of your paper about dimensionality and regularization bias. A very clear and concise treatment. Good work!
@xuyiqing Interesting paper! Thanks for posting. IIUC, your main concern with the GAM approach is that it targets the wrong estimand. If so, I feel that your criticism of the approach is kind of unfair, given that it's easy to target CME w/ GAM. See this notebook: https://t.co/avwFcLF1Xk
@LeoBaccini That's all fine but, fundamentally, I'm not convinced that the president is actually looking for policy concessions. And I worry that spending more CAD in these areas will embolden further extortion attempts.
@robertwiblin You may be interested in our recent paper, where we show there is public support for buy-outs like the one you recommend. See Journal of Politics, Buy-in for Buyouts: Attitudes Toward Compensation for Reform https://t.co/YGS3d7NOQy