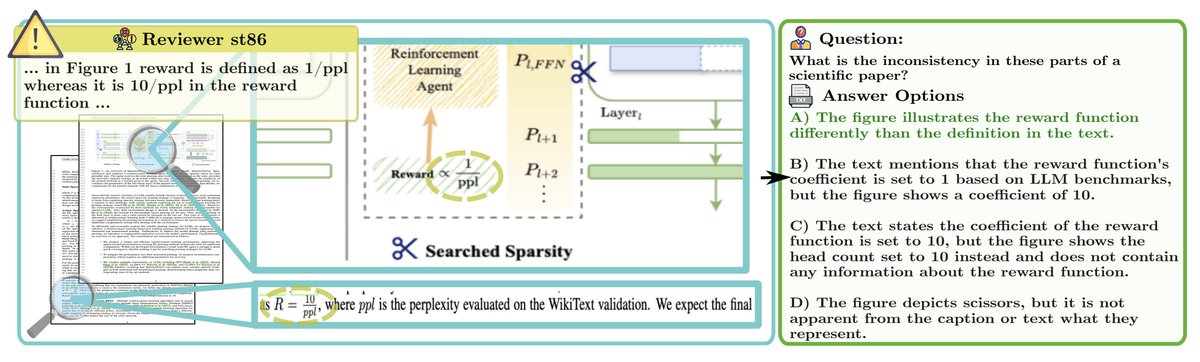
Excited to share our paper “PRISMM-Bench: A Benchmark of Peer-Review Grounded Multimodal Inconsistencies” has been accepted to ICLR 2026 🎉 🥳This work means a lot to me as it's my first time serving as the last author supervising a Master student Huge congrats to Lukas Selch!
🔍📄PRISMM-Bench is the first benchmark built from real reviewer-flagged multimodal inconsistencies in scientific papers, targeting a key challenge for multimodal scientific reasoning. I’m especially happy that the paper was well received, with an initial rating of 6-6-6-6 🙌🔥.
🚀 🚀 We are introducing VisualOverload🎨🖼️, a VQA benchmark designed to test fundamental vision skills in visually dense scenes. 2,720 Q&A pairs across 6 tasks, 150 high-res artworks, and private ground truth. Even top VLMs hit only ~20% on the hardest tasks. Try it yourself🤖👉
Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
🚨 New @ICCVConference 2025 paper!
Can GPT-4o actually localize an object from just a few examples?
Turns out not really. In our @ICCVConference paper, we propose a simple fix: teach it from video tracking data.
Results? Better few-shot localization, stronger context grounding.
IPLOC accepted to ICCV25 ☺️
Thanks to all the people that were part of it 🩷
The idea for this paper came by a lake during a visit to Graz for a talk. It has traveled with me through too many countries and too many wars, and it’s now a complete piece of work.
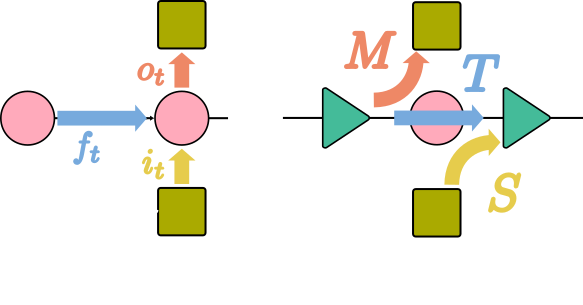
Check our new work pLSTM that brings the power of linear RNNs to arbitrary DAGs and multi-dimensional data, enabling parallel computation and long-range modeling. It outperforms Transformers on extrapolation tasks and handles images, graphs, and grids with remarkable efficiency.
Ever wondered how linear RNNs like #mLSTM (#xLSTM) or #Mamba can be extended to multiple dimensions?
Check out "pLSTM: parallelizable Linear Source Transition Mark networks". #pLSTM works on sequences, images, (directed acyclic) graphs.
Paper link: https://t.co/nU7626uHWK
Check out our poster and talk with Guofeng at #355 in ExHall D. PerLA, is our new 3D language assistant that helps LLMs better understand the physical world! PerLA fuses local details and global context from point clouds using cross-attention + GNNs, and achieves SOTA on 3D bench
🚨 Our panel kicks off at 11:30 AM in Room 207 A–D (Level 2)!
Don't miss an amazing discussion with: Ludwig Schmidt, Andrew Owens, Arsha Nagrani, and Ani Kembhavi 🔥
Our MMFM Panel Discussion "What is Next in Multimodal Foundation Models?" will happen at 11:30am in room 207 A-D
Moderator: Roei Herzig (UC Berkeley)
Panelists: Ludwig Schmidt, Andrew Owens, Arsha Nagrani, Ani Kembhavi
@MMFMWorkshop@CVPR
Ludwig Schmidt is giving the first talk on LAION-5B & DataComp: In search of the next generation of multimodal datasets at our MMFM workshop on Zoom 207 A-D!