Introducing DreamReasoner-8B🚀 — an open-source block diffusion model for math and code reasoning. It reaches reasoning performance comparable to Qwen3-8B-Thinking while enabling parallel block-wise generation.
@rchmielarz Thanks for the question. By on par, we are referring to accuracy on reasoning benchmarks. Please check our technical report for further analysis on inference speed. https://t.co/eyn5N645Ar.
Introducing DreamReasoner-8B🚀 — an open-source block diffusion model for math and code reasoning. It reaches reasoning performance comparable to Qwen3-8B-Thinking while enabling parallel block-wise generation.
We’re releasing DreamReasoner-8B to support research on diffusion-based reasoning models.
Checkpoint: https://t.co/c8Xa8tm2UT
SGLang Inference: https://t.co/8Nt9kfmsE5
Code: https://t.co/VRecksesWv
Excited to introduce 🌠Orion: Towards Lab Automation with Computer-Using Agents.
Give it control of your lab computer💻, and it can use software, analyze any experiment images, browse databases on Chrome exactly like you, and work for hours to analyze your experiments.
🌎:https://t.co/5EAe8vEetl
📎:https://t.co/D08hYrkJuG
🚀 1,000+ TOKENS/S ON A 1T MODEL! 🚀
We are thrilled to release Xiaomi MiMo-V2.5-Pro-UltraSpeed in collaboration with @TileRT_AI , breaking the 1,000 tokens/s output speed on a 1 Trillion parameter model for the FIRST TIME!
Not wafer-scale integration like Cerebras. Not pure on-chip SRAM chips like Groq. We achieve 1,000 tps on a 1T MoE model using just a SINGLE, STANDARD 8-GPGPU NODE.
Read the full technical deep dive:https://t.co/MX0kjHKdKi
Want to experience the future of real-time AI?
👉 Apply for UltraSpeed now: https://t.co/aeWAxyhwVk
⏳ Limited-Time Access: Application-based · Jun 8 – Jun 23 (PDT)
💬 Chat Experience: Completely FREE for a limited time — try the blazing-fast web chat now.
⚡ UltraSpeed API: Just 3x the price for a ~10x boost in output experience.
🤝 Enterprise & Large-Scale Needs: [email protected]
🚀 Check out our Nemotron-Labs-Diffusion model!
We have been wondering about the true promise of diffusion LMs, especially when competing with strong AR models in terms of accuracy and with MTP methods in terms of efficiency.
💡 Nemotron-Labs-Diffusion is an important step toward answering this question, delivering a tri-mode LM that unifies AR, diffusion, and self-speculation (diffusion drafts, AR verifies) decoding within a single model.
🌟 Core Insights
🔸 AR and diffusion objectives can be mutually beneficial and harmonized within a single model.
🔸 Self-speculation, enabled by joint AR/diffusion training, can outperform Eagle3 in throughput.
🔸 Diffusion shows strong long-term potential for parallel decoding under an optimal sampler.
📊 Model performance: Our 8B/14B models match or exceed Qwen3-8B/14B accuracy while generating 6× more tokens per forward pass, leading to a 4× speedup in SGLang on GB200.
🤗 𝗛𝗙 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗶𝗼𝗻 (3B/8B/14B base + instruct and 8B VLM):
https://t.co/UJ8qLM7OBB
📰 𝗧𝗲𝗰𝗵 𝗥𝗲𝗽𝗼𝗿𝘁:
https://t.co/kXEXU20VAk
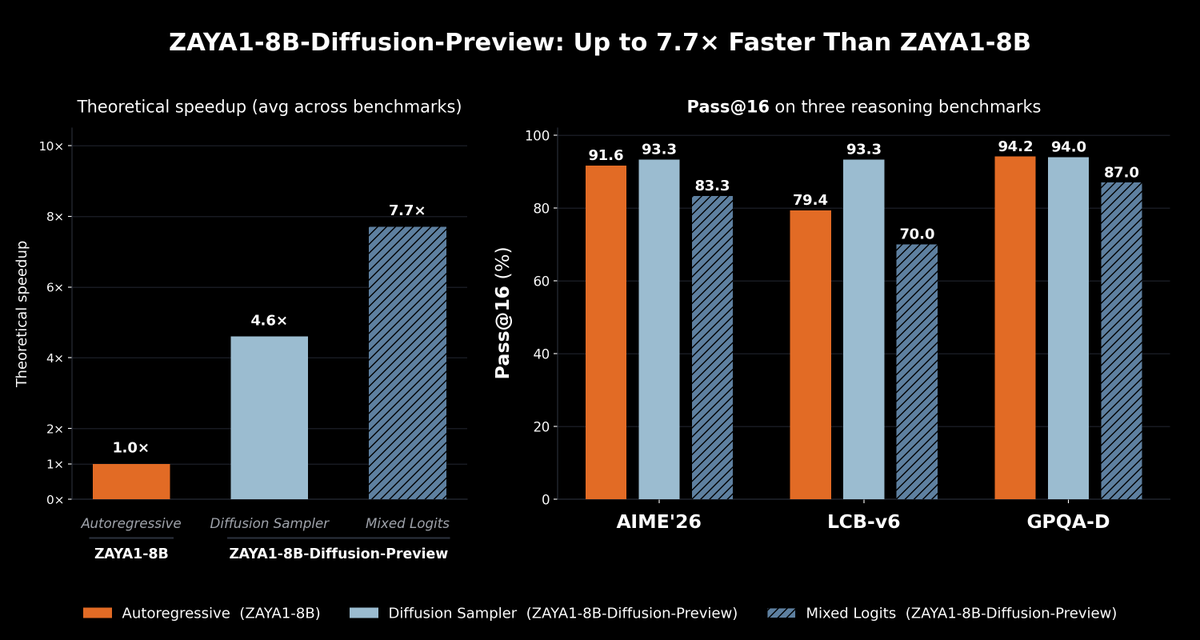
We present ZAYA1-8B-Diffusion-Preview, the first diffusion language model trained on @AMD.
Autoregressive LLMs generate one token at a time; diffusion generates a block in parallel, speeding up inference.
We show a 4.6-7.7x decoding speedup with minimal quality degradation 🧵
Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo.
Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm.
https://t.co/1ZaIneleuW
🦞 Claw-Eval-Live is out, a live extension of the Claw-Eval Family!
This live release includes:
105 tasks | 17 workflow families | 13 frontier models tested | quarterly refresh from real ClawHub marketplace signals.
Instead of relying on a static task set, Claw-Eval-Live keeps agent evaluation aligned with evolving real-world enterprise workflows.
Check it out:
🤗 HF Paper: https://t.co/jKLlpTyLEL
Leaderboard: https://t.co/lWVGhak47l
Code: https://t.co/n70zwnTLsn
Happy to present our #ICLR2026 paper: Dual-objective LMs! How can we make autoregressive LLMs more robust to overfitting and masked-diffusion models more sample-efficient? Simply by training on both objectives at the same time!
Meet Kimi K2.6 Agent Swarm 👋
Highlights:
🔹 Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from 100 / 1,500 in K2.5).
🔹 Outputs are real files, not chat - one run delivers 100+ files, 100,000-word literature reviews, or 20,000-row datasets.
🔹Heterogeneous skills - search, analysis, coding, long-form writing, and visual generation all running in parallel
🔗Try it at: https://t.co/2Tu8McUaUa
Introducing DDTree: accelerates speculative decoding by drafting a tree with one block diffusion pass, then verifying multiple likely continuations together.
Paper: https://t.co/cgYBw70O5i
Project page: https://t.co/ygFukxrZLB
Code: https://t.co/2z7U00NsuH
Claw-Eval v1.1 is out, with multimodal tasks and multi-turn dialogue.
Now we have:
300 human-verified tasks | 2,159 rubrics | 9 categories | 14 models from 7 families tested.
Agents are graded on Completion, Safety, and Robustness through full-trajectory auditing.
Shoutout to Qwen @Alibaba_Qwen , GLM @Zai_org , and MiniMax @MiniMax_AI for integrating Claw-Eval into their model evaluations!
Paper: https://t.co/wtSqPyep50
Leaderboard: https://t.co/FilOv3qC7P
Code: https://t.co/7DHsMkP0PQ
🤗Data: https://t.co/yV0pAvhH3r
🧵 Here are our findings:
Finally getting to share one of my favorite projects. ICLR Oral! 🏆
It’s so strange how rigid video tokenization is. Think about it: why should a still landscape cost the same amount of tokens as a busy street?
We built InfoTok. We went back to basics with Shannon’s information theory to make tokens "adaptive" in a principled way. Its 2.3x better compression and 11x faster inference demonstrates the magic of the old-school theory ✨
Check it out: https://t.co/0PeYtaVY1y