Our work was cited by π0.7! This further highlights an important direction for VLA training: leveraging abundant human video data to address the bottleneck of task diversity.
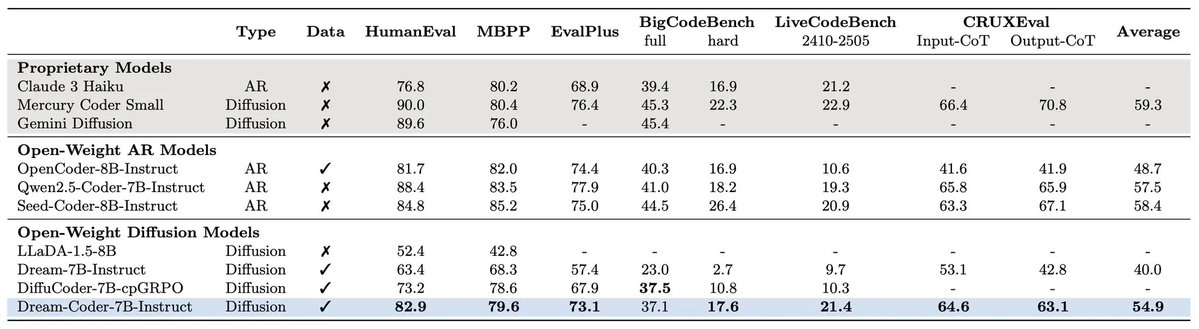
Excited to share our new paper: CLAP: Contrastive Latent Action Pretraining for Learning Vision-Language-Action Models from Human Videos.
CLAP aligns human video dynamics with executable robot actions, enabling VLAs to transfer manipulation skills from human demonstrations to real robot control.
We will open-source the code in May.
arXiv link: https://t.co/enofYlocon
video on youtube: https://t.co/G3rgRZbAH1
🚀 Turn ANY investment idea or research article into a backtested quant strategy. Let's have a try!
🌐 Pro Beta Investment Assistant Web App (🎁Sign up now to claim 500 FREE credits!): https://t.co/sO4aksmhvd
🔗 Lightweight Open-Source Agent Skill: https://t.co/tnFGIZDVeQ
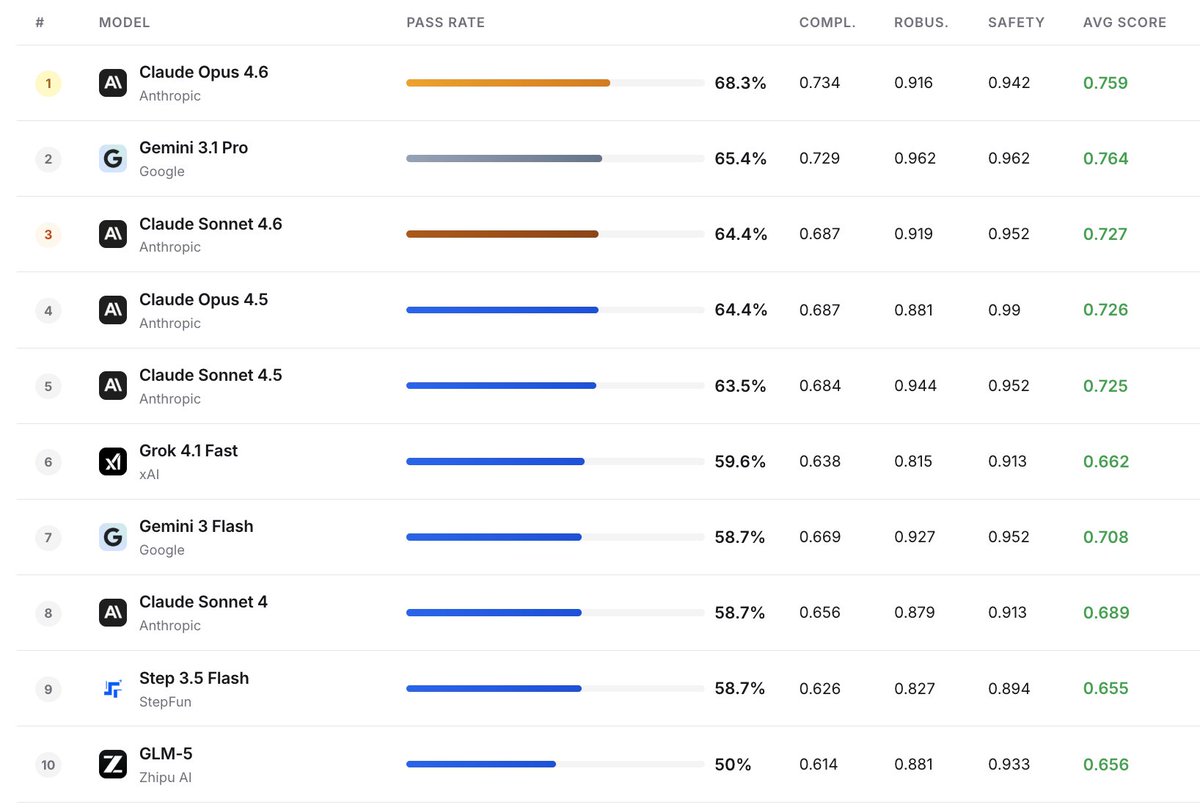
Agents are doing real work, but existing benchmarks still test them in isolation.
Today we’re releasing Claw-Eval 🦞: an open-source, transparent evaluation framework for AI agents.
We feature 104 tasks spanning daily assistants, Office QA, deep finance research, and terminal usage.
We test completion, robustness, and safety across real and mock services with configurable error injection.
Fully traceable and human-verified.
First leaderboard results: Claude Opus 4.6 @AnthropicAI tops pass rate (68.3%), but Gemini 3.1 @GeminiApp Pro edges it on avg score (0.764 vs 0.759).
Agents have a long way to go.🤨
Check it out: https://t.co/NSt33x1toh
@steipete@openclaw
Introducing proxy compression for end-to-end language modeling: train on compressed (e.g., tokenized) data for efficiency, but run inference entirely on raw bytes without a tokenizer. No architectural changes required. At scale, proxy-trained byte models match or surpass tokenizer baselines at 7B and 14B.
📄 Paper: https://t.co/4NGVagTocP
💻 Code: https://t.co/tPcbReJ915
[1/9]
🧵👇
🚀 Introducing Dream-VL & Dream-VLA!
We’re proving that dLLMs have an amazing advantage in building VLA models.
The result is stunning performance:
🏆 97.2% on LIBERO
⚡ 27x speedup vs AR models
🔥 Beats OpenVLA & $\pi_0$
✅ Fully Open Source
Blog: https://t.co/klCKlUeR1l
🚀Building on the success of Dream 7B, we introduce Dream-VL and Dream-VLA, open VL and VLA models that fully unlock discrete diffusion’s advantages in long-horizon planning, bidirectional reasoning, and parallel action generation for multimodal tasks.
🚀 Thrilled to share our #NeurIPS2025 paper
DynaAct: Large Language Model Reasoning with Dynamic Action Spaces
A new test-time scaling view — optimizing the action space itself, while providing a general MCTS acceleration framework for reasoning.
💻 https://t.co/FFWIDBcbCV
We will have a guest talk from Cai Zhou. He is a second-year PhD in MIT EECS. "Continuous modeling in diffusion language models: HDLM and CCDD
". All are welcome to join via the following link.
https://t.co/ZlLDO5pKRH
DeepSeek-OCR: Exploring the boundaries of visual-text compression.
Ambitious! They might use 10X (near-lossless) compressed vision tokens to replace the KV cache of dialog histories.
https://t.co/gxjLBrkCWW
Introducing Generative Interfaces - a new paradigm beyond chatbots.
We generate interfaces on the fly to better facilitate LLM interaction, so no more passive reading of long text blocks.
Adaptive and Interactive: creates the form that best adapts to your goals and needs!
🌟 Thrilled to share our paper, "TreeSynth," has been accepted for a Spotlight presentation at #NeurIPS2025!
🤔 Struggling with repetition & space collapse in data synthesis? Our work introduces 🌳TreeSynth, a novel framework using tree-guided partitioning to generate large-scale, diverse datasets from scratch.
🏆 Models trained on TreeSynth data consistently outperform those trained on human-crafted datasets and other synthetic methods.
See you all at NeurIPS!
🔗 Paper: https://t.co/nc784c7X5Y
💻 Code: https://t.co/p0C75ZgWvz
Jinjie Ni @NiJinjie from NUS will be giving a talk titled "Diffusion Language Models are Super Data Learners" at Friday Aug 22 11am HKT. link to talk: https://t.co/WxTUSok1in
🚀 MiMo‑VL 2508 is live! Same size, much smarter.
We’ve upgraded performance, thinking control, and overall user experience.
📈 Benchmark gains across image + video: MMMU 70.6, VideoMME 70.8.
Consistent improvements across the board.
🤖 Thinking Control: toggle reasoning with `no_think`.
On (default): full reasoning visible;
Off: direct answers, no reasoning ⚡⚡;
❤️ Real‑world user experience: our VLM Arena rating improved from 1093.9 → 1131.2 (+37.3).
More capable, flexible, and reliable in everyday tasks.
Feedback welcome.
🤗 RL Version: https://t.co/ID71evQJLL
🤗 SFT Version: https://t.co/cm14ZtZzt9
#XiaomiMiMo
Xinyu Yang from CMU will be giving a talk titled "Multiverse: Your Language Models Secretly
Decide How to Parallelize and Merge Generation" at Friday July 25 11am HKT (Thursday July 24 8pm PDT). Link to talk: https://t.co/Cdn9TGqWQ2
📢 Update: Announcing Dream's next-phase development.
- Dream-Coder 7B: A fully open diffusion LLM for code delivering strong performance, trained exclusively on public data.
- DreamOn: targeting the variable-length generation problem in dLLM!
We present DreamOn: a simple yet effective method for variable-length generation in diffusion language models.
Our approach boosts code infilling performance significantly and even catches up with oracle results.






















![linzhengisme's tweet photo. Introducing proxy compression for end-to-end language modeling: train on compressed (e.g., tokenized) data for efficiency, but run inference entirely on raw bytes without a tokenizer. No architectural changes required. At scale, proxy-trained byte models match or surpass tokenizer baselines at 7B and 14B.
📄 Paper: https://t.co/4NGVagTocP
💻 Code: https://t.co/tPcbReJ915
[1/9]
🧵👇](https://pbs.twimg.com/media/HArqWrNaUAA_A7h.png)