👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
RLVR has become the recipe for agentic post-training. But for Computer-Use Agents, the bottleneck is not the algorithm, it is the data. 🐌
🚀 We introduce CUA-Gym: a scalable, lightweight synthesis engine that turns arbitrary task queries into verifiable RLVR data for computer-use agents. The largest open CUA RLVR dataset to date:
🎯 32,122 verifiable RLVR tasks with programmatic setup scripts + rewards
🌐 110 environments: 16 desktop apps + 94 synthesized mock web apps
🏆 Qwen3.5-based CUA models trained with GSPO reach 72.6% on OSWorld-Verified and 56.6% on WebArena
📄 Paper: https://t.co/cdvHJPzgb1
🏠 Homepage: https://t.co/kvhaOQxNx7
🤗 Dataset: https://t.co/w5vOIRdchR
💻 Codebase: https://t.co/CcRlNTlS1c
🧩 Environments: https://t.co/fNZ6YAI8LD
🧵[1/6]
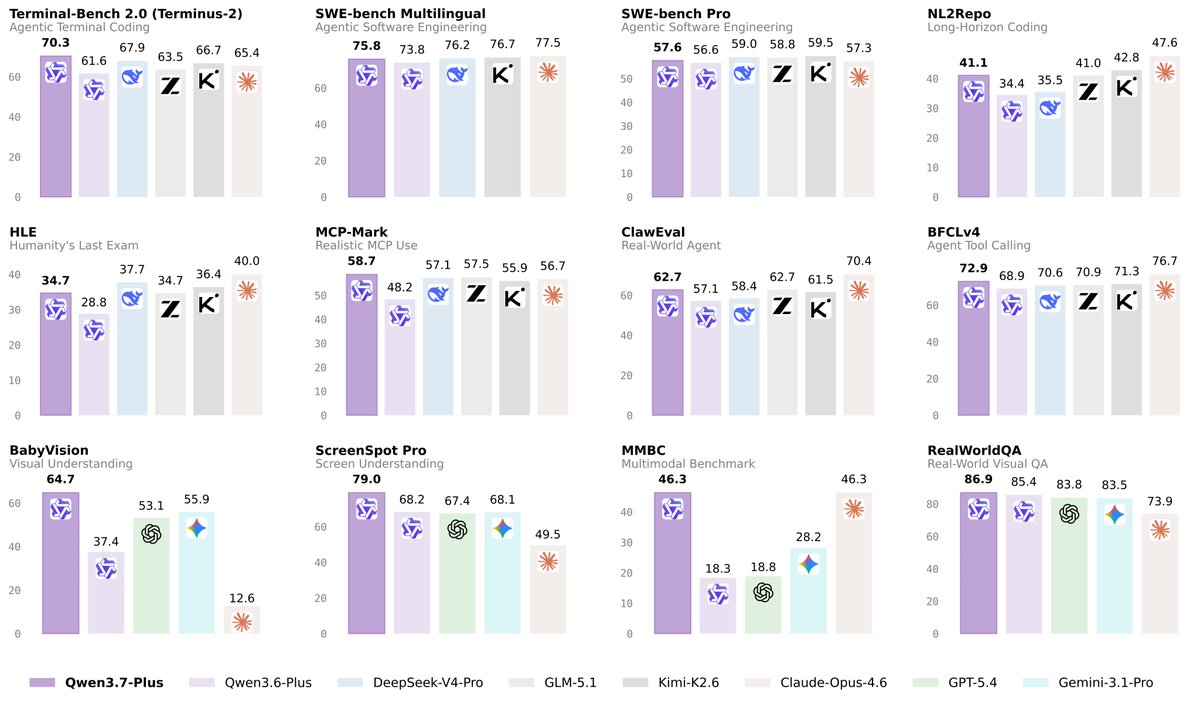
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: https://t.co/y3AupX3Pa0
✅ Qwen Studio: https://t.co/qpTnrCBjWt
⚡️ API:https://t.co/0sys00osKn
Thinky's secret plan:
1: Increase Human<->AI bandwidth
2: Raise ceiling of human+AI intelligence
3: Help humans continue as main-characters in the new world
We are at Step 1.
Interaction Models are great real-time collaborative tools for humans.
Here's a preview:
Big week for model releases, and Claw-Eval is updating too.
MiMo V2.5 Pro now ranks 3rd, and MiMo V2.5 ranks 5th.
Next up: DeepSeek V4?
👉🏻 https://t.co/wVioDjWntX
Real-world agents juggle instructions from skill files, tools, other agents, ... each with different trust levels. When these conflict, can models reliably prioritize the most trusted one?
Our ManyIH-Bench🪜 finds that even frontier models like GPT-5.4 only get ~40% accuracy! 👇
Claw-Eval v1.1 is out, with multimodal tasks and multi-turn dialogue.
Now we have:
300 human-verified tasks | 2,159 rubrics | 9 categories | 14 models from 7 families tested.
Agents are graded on Completion, Safety, and Robustness through full-trajectory auditing.
Shoutout to Qwen @Alibaba_Qwen , GLM @Zai_org , and MiniMax @MiniMax_AI for integrating Claw-Eval into their model evaluations!
Paper: https://t.co/wtSqPyep50
Leaderboard: https://t.co/FilOv3qC7P
Code: https://t.co/7DHsMkP0PQ
🤗Data: https://t.co/yV0pAvhH3r
🧵 Here are our findings:
Two days ago, Anthropic cut off third-party harnesses from using Claude subscriptions — not surprising. Three days ago, MiMo launched its Token Plan — a design I spent real time on, and what I believe is a serious attempt at getting compute allocation and agent harness development right. Putting these two things together, some thoughts:
1. Claude Code's subscription is a beautifully designed system for balanced compute allocation. My guess — it doesn't make money, possibly bleeds it, unless their API margins are 10-20x, which I doubt. I can't rigorously calculate the losses from third-party harnesses plugging in, but I've looked at OpenClaw's context management up close — it's bad. Within a single user query, it fires off rounds of low-value tool calls as separate API requests, each carrying a long context window (often >100K tokens) — wasteful even with cache hits, and in extreme cases driving up cache miss rates for other queries. The actual request count per query ends up several times higher than Claude Code's own framework. Translated to API pricing, the real cost is probably tens of times the subscription price. That's not a gap — that's a crater.
2. Third-party harnesses like OpenClaw/OpenCode can still call Claude via API — they just can't ride on subscriptions anymore. Short term, these agent users will feel the pain, costs jumping easily tens of times. But that pressure is exactly what pushes these harnesses to improve context management, maximize prompt cache hit rates to reuse processed context, cut wasteful token burn. Pain eventually converts to engineering discipline.
3. I'd urge LLM companies not to blindly race to the bottom on pricing before figuring out how to price a coding plan without hemorrhaging money. Selling tokens dirt cheap while leaving the door wide open to third-party harnesses looks nice to users, but it's a trap — the same trap Anthropic just walked out of. The deeper problem: if users burn their attention on low-quality agent harnesses, highly unstable and slow inference services, and models downgraded to cut costs, only to find they still can't get anything done — that's not a healthy cycle for user experience or retention.
4. On MiMo Token Plan — it supports third-party harnesses, billed by token quota, same logic as Claude's newly launched extra usage packages. Because what we're going for is long-term stable delivery of high-quality models and services — not getting you to impulse-pay and then abandon ship.
The bigger picture: global compute capacity can't keep up with the token demand agents are creating. The real way forward isn't cheaper tokens — it's co-evolution. "More token-efficient agent harnesses" × "more powerful and efficient models." Anthropic's move, whether they intended it or not, is pushing the entire ecosystem — open source and closed source alike — in that direction. That's probably a good thing. The Agent era doesn't belong to whoever burns the most compute. It belongs to whoever uses it wisely.
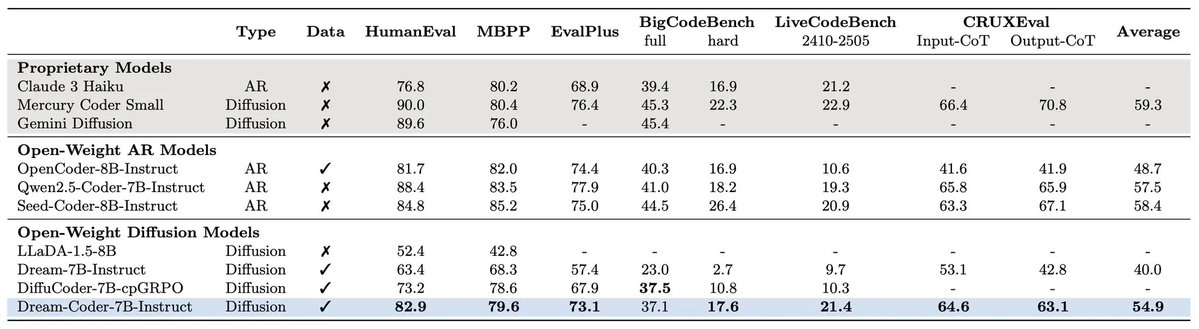
When training Qwen3.5, we kept asking ourselves:
🧐What kind of multimodal RLVR data actually leads to generalizable gains?
💡We believe the answer may not lie only in data tightly tailored to specific benchmarks, but also in OOD proxy tasks that train the foundational abilities behind long-chain visual reasoning.
The motivation is simple: VLMs are still unreliable in long-CoT settings. Small mistakes in perception, reasoning, knowledge use, or grounding can compound across intermediate steps and eventually lead to much larger final errors. However, much of today’s RLVR data still does not require complex reasoning chains grounded in visual evidence throughout, meaning these failure modes are often not sufficiently stressed during training.
🚀Excited to share our new work from Qwen and Tsinghua LeapLab:
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
This is also one of the training task sources used in Qwen3.5 VL RLVR.
To study this question, we propose HopChain, a scalable framework for synthesizing multi-hop vision-language reasoning data for RLVR training. The key idea is to build each query as a chain of logically dependent hops: earlier hops establish the instances, sets, or conditions needed for later hops, while the model must repeatedly return to the image for fresh visual grounding along the way. At the same time, each query ends with a specific, unambiguous numerical answer, making it naturally suitable for verifiable rewards.
Concretely, HopChain combines two complementary structures: perception-level hops and instance-chain hops. We require each synthesized example to involve both, so the model cannot simply continue reasoning from language inertia. Instead, it is forced to keep grounding intermediate steps in the image, maintain cross-step dependencies, and control error accumulation across long reasoning trajectories. Our goal is not to mimic any specific downstream benchmark, but to strengthen the more fundamental abilities that long-CoT vision-language reasoning depends on.
We add HopChain-synthesized data into RLVR training for Qwen3.5-35B-A3B and Qwen3.5-397B-A17B, and evaluate on 24 benchmarks spanning diverse domains. Despite not being designed for any particular benchmark, HopChain improves 20 out of 24 benchmarks on both models, indicating broad and generalizable gains. We also find that full chained multi-hop queries are crucial: replacing them with half-multi-hop or single-hop variants reduces performance substantially. Most notably, the gains are especially strong on long-CoT and ultra-long-CoT vision-language reasoning, peaking at more than 50 accuracy points in the ultra-long-CoT regime.
Our main takeaway is simple:
beyond benchmark-aligned data, OOD proxy tasks that systematically train the core mechanics of long-chain visual reasoning can be a powerful and scalable source of RLVR supervision for VLMs — and can lead to more generalizableimprovements.
🔗 https://t.co/Bv887MDDdt
🧮 Principia: Training LLMs to Reason over Mathematical Objects 📐
We release:
- PrincipiaBench, a new eval for *mathematical objects* (not just numerical values or MCQ)
- Principia Collection: training data that improves reasoning across the board.
For models to help with scientific and mathematical work, you need to train on such data & test whether they can derive things like equations, sets, matrices, intervals, and piecewise functions.
We show that this ends up improving the overall reasoning ability of your model for all tasks.
Read more in the blog post: https://t.co/2VlT2PIxrX
🚀 New work: Meta-Reinforcement Learning with Self-Reflection
LLM agents shouldn't just solve problems. They should learn from their own attempts. Most current RL methods optimize single independent trajectories.
Each attempt starts from scratch, with no mechanism to improve across attempts. But intelligent systems should get better after trying once.
This raises a fundamental question: How do we train models to learn from their own attempts?
We believe Meta-Reinforcement Learning may be a key paradigm for training future LLM agents, enabling models to adapt and improve across attempts and environments.
In this work we introduce MR-Search, a training paradigm built around:
🧠 In-Context Meta-Reinforcement Learning
🪞 Self-Reflection
🔁 Learning to learn at test time
📄 Paper: https://t.co/idEBvKavEA
💻 Code: https://t.co/m5b9HXgjM6
Introducing proxy compression for end-to-end language modeling: train on compressed (e.g., tokenized) data for efficiency, but run inference entirely on raw bytes without a tokenizer. No architectural changes required. At scale, proxy-trained byte models match or surpass tokenizer baselines at 7B and 14B.
📄 Paper: https://t.co/4NGVagTocP
💻 Code: https://t.co/tPcbReJ915
[1/9]
🧵👇






































![linzhengisme's tweet photo. Introducing proxy compression for end-to-end language modeling: train on compressed (e.g., tokenized) data for efficiency, but run inference entirely on raw bytes without a tokenizer. No architectural changes required. At scale, proxy-trained byte models match or surpass tokenizer baselines at 7B and 14B.
📄 Paper: https://t.co/4NGVagTocP
💻 Code: https://t.co/tPcbReJ915
[1/9]
🧵👇](https://pbs.twimg.com/media/HArqWrNaUAA_A7h.png)



















