Recursive self-improvement (RSI) means the system improves the improvement mechanism itself. Each cycle produces not only a more capable system, but a system that is better at improving itself. RSI is always one order higher than the corresponding SI, because the recursion operates at the meta-level, on the rate of improvement itself. It could arrive faster than most institutions can adapt.
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
LMs can learn from human labels, training data, and stronger teachers. But what happens when all of these run out when the model is already at the frontier and there is no stronger external source to learn from❓
In EvoLM, we extract the model's own evaluative knowledge into rubrics, and use them to improve its own generation🔁
This enables self-improvement with no external signals‼️
Congrats Huaisheng @huaiszhu on SDDLM being accepted to ICML 2026! 🎉
A personal milestone: my first paper as the last author.
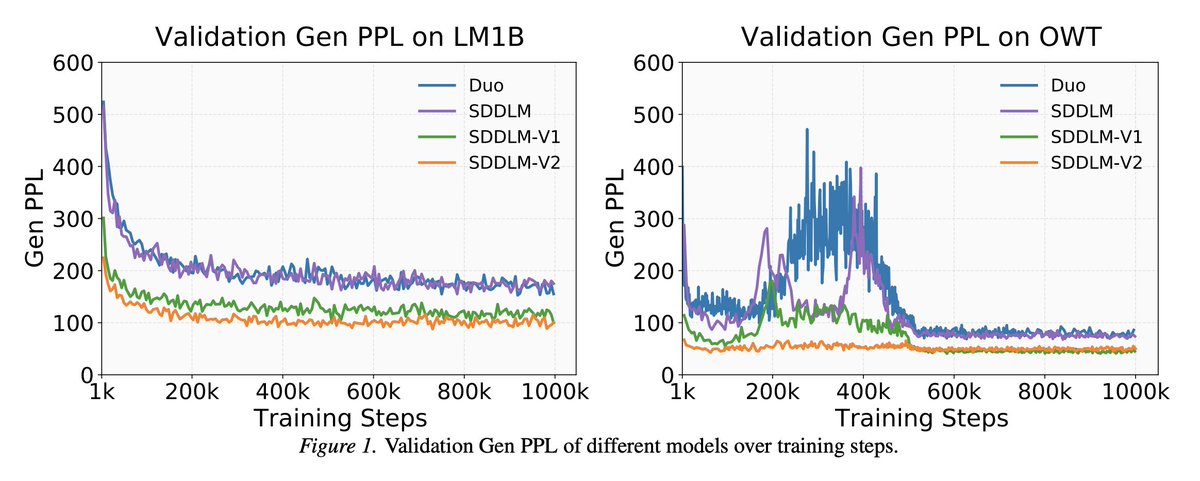
SDDLM uses a simple denoising objective for uniform-state diffusion LMs—lower cost, scaling to 1.1B, and strong generation quality.
https://t.co/bhtY0pN8SQ
🚀 New work accepted at ICML 2026
Simple Denoising Diffusion Language Models (SDDLM)
⚡ Efficient training. Strong scaling.
Our method reduces training cost while matching or surpassing prior methods,
and scales effectively to 1.1B parameter models with strong performance.
My first paper since joining the ETH AI Center and the Apertus team:
@AlexisLimozin discovered two bugs in DeepSpeed and OpenRLHF that lead to faulty SFT baselines often cited in mixed-policy RL for LLM reasoning methods. When applying the fixes, SFT-then-RL outperforms every mixed-policy approach that we tested.
The bugs are:
- DeepSpeed CPU-offload optimizer silently drops micro-batches in gradient accumulation (also hits TRL, OpenRLHF, Llama-Factory).
- OpenRLHF misweights per-mini-batch losses.
🚀 New work: Meta-Reinforcement Learning with Self-Reflection
LLM agents shouldn't just solve problems. They should learn from their own attempts. Most current RL methods optimize single independent trajectories.
Each attempt starts from scratch, with no mechanism to improve across attempts. But intelligent systems should get better after trying once.
This raises a fundamental question: How do we train models to learn from their own attempts?
We believe Meta-Reinforcement Learning may be a key paradigm for training future LLM agents, enabling models to adapt and improve across attempts and environments.
In this work we introduce MR-Search, a training paradigm built around:
🧠 In-Context Meta-Reinforcement Learning
🪞 Self-Reflection
🔁 Learning to learn at test time
📄 Paper: https://t.co/idEBvKavEA
💻 Code: https://t.co/m5b9HXgjM6
📊 Empirically, this simple idea works surprisingly well.
Across multiple benchmarks, MR-Search significantly outperforms strong RL baselines, with 9–19% relative improvements.
But the bigger takeaway isn't just the numbers. It's the training paradigm.
🔥 Even more interesting:
Models trained with Meta-RL naturally benefit from additional reflection at test time.
Performance keeps improving as we allow more reflection turns. This suggests Meta-RL enables true test-time adaptation: the ability for models to improve during inference.
A broader perspective:
Future LLM agents may not rely on one-shot reasoning.
Instead they may operate in a loop:
🧠 attempt
🪞 reflect
🔁 adapt
📈 improve
Training agents to learn from experience during inference may be one of the most important directions for building more capable AI systems.
And Meta-Reinforcement Learning provides a natural training framework for this.
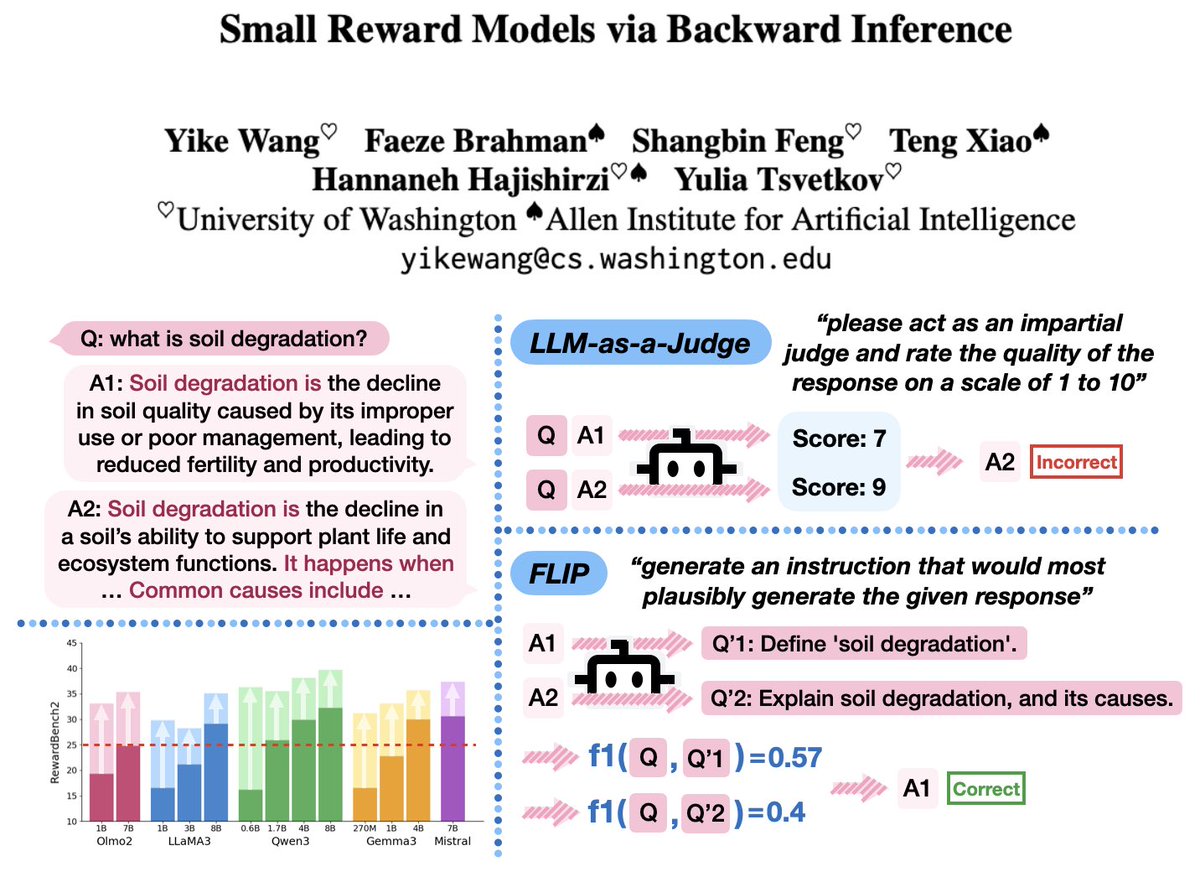
Small language models are not very helpful as judges, how about 🔄 backward inference—inferring the instruction given only the response, and using the similarity between the inferred and the original instructions as the reward signal?
Introducing ⚙️FLIP, a reference-free and rubric-free reward modeling approach that boosts the RewardBench2 performance of 13 small language models by an average of 79.6%, and substantially outperforms LLM-as-a-Judge under test-time scaling via parallel sampling and GRPO training.
📄paper: https://t.co/X1G5nrN2mx
🔗code: https://t.co/ArM5wPqYYy
🚀 New Paper Alert!
🧠 Simple Denoising Diffusion Language Models (SDDLMs)
We simplify the complex ELBO objectives in Uniform-State Diffusion Models with a simple denoising loss, making training more scalable — while matching or surpassing baseline generation quality.
(1/2)
Want to get an LLM agent to succeed in an OOD environment?
We tackle the hardest case with SPA (Self-Play Agent). No extra data, tools, or stronger models. Pure self-play.
We first internalize a world model via Self-Play, then we learn how to win by RL.
Like a child playing with the env to simply learn about “what if I do this?”
Below, we show our findings on: What is wrong with OOD environments? What are the key factors that allow self-play to succeed?
(1/8)
@SimonXinDong Yes, Very good points! Our work SimPER, published at ICLR 2025 (https://t.co/hfd4anqlFb), also verifies that optimizing the geometric mean is effective.