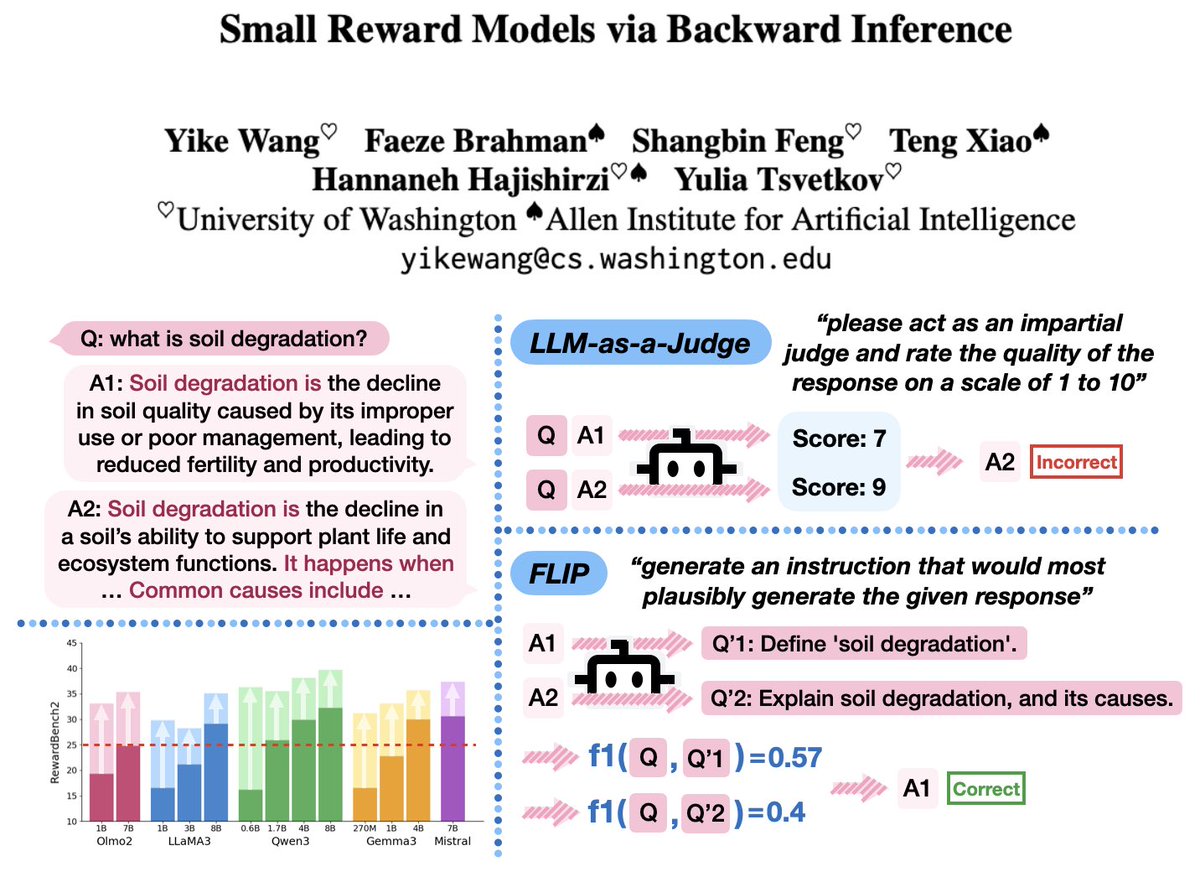
Small language models are not very helpful as judges, how about 🔄 backward inference—inferring the instruction given only the response, and using the similarity between the inferred and the original instructions as the reward signal?
Introducing ⚙️FLIP, a reference-free and rubric-free reward modeling approach that boosts the RewardBench2 performance of 13 small language models by an average of 79.6%, and substantially outperforms LLM-as-a-Judge under test-time scaling via parallel sampling and GRPO training.
📄paper: https://t.co/X1G5nrN2mx
🔗code: https://t.co/ArM5wPqYYy
It's time for a different kind of AI future.
Modular AI systems
Bottom-up development
Reduce unilateral control
Scaling participation
Our take: https://t.co/bIHob4Ho5V
collaboration w/ @yikewang_@WeijiaShi2@LukeZettlemoyer@YejinChoinka@tsvetshop
LMs can learn from human labels, training data, and stronger teachers. But what happens when all of these run out when the model is already at the frontier and there is no stronger external source to learn from❓
In EvoLM, we extract the model's own evaluative knowledge into rubrics, and use them to improve its own generation🔁
This enables self-improvement with no external signals‼️
Today, we’re releasing Continual Learning Bench 1.0: the first, realistic benchmark for measuring how AI systems can improve in online settings.
Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened.
But deployed AI systems should learn from experience. We tested 10+ frontier systems against novel, expert-validated tasks and find there’s still plenty of headroom for learning. (1/n)
Ever noticed how some writers imply multitude of meanings without explicitly stating them; e.g. the coin toss scene from No Country for Old Men. This phenomenon of "subtext" is what we explore in my internship work at Google DeepMind. With @_EffieLi_@AndrewLampinen
1/n
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
Life update here:
Last week marked the end of my time at Ai2.
Proud to have built releases like Olmo, Tülu, FlexOlmo, DRTulu, OLMoTrace, OlmoE, and datasets including Dolma and Dolci—and of how strongly we pushed for open models and open science.
Our artifacts reached 33M+ downloads, including ~4M for Olmo 3. I believe Olmo has empowered researchers to push the boundaries of AI
I’ll always be cheering on Ai2 and will continue to strongly support open-source, open-science AI.
I’m deeply grateful for this chapter and excited for what comes next.
🚀 New work: Meta-Reinforcement Learning with Self-Reflection
LLM agents shouldn't just solve problems. They should learn from their own attempts. Most current RL methods optimize single independent trajectories.
Each attempt starts from scratch, with no mechanism to improve across attempts. But intelligent systems should get better after trying once.
This raises a fundamental question: How do we train models to learn from their own attempts?
We believe Meta-Reinforcement Learning may be a key paradigm for training future LLM agents, enabling models to adapt and improve across attempts and environments.
In this work we introduce MR-Search, a training paradigm built around:
🧠 In-Context Meta-Reinforcement Learning
🪞 Self-Reflection
🔁 Learning to learn at test time
📄 Paper: https://t.co/idEBvKavEA
💻 Code: https://t.co/m5b9HXgjM6
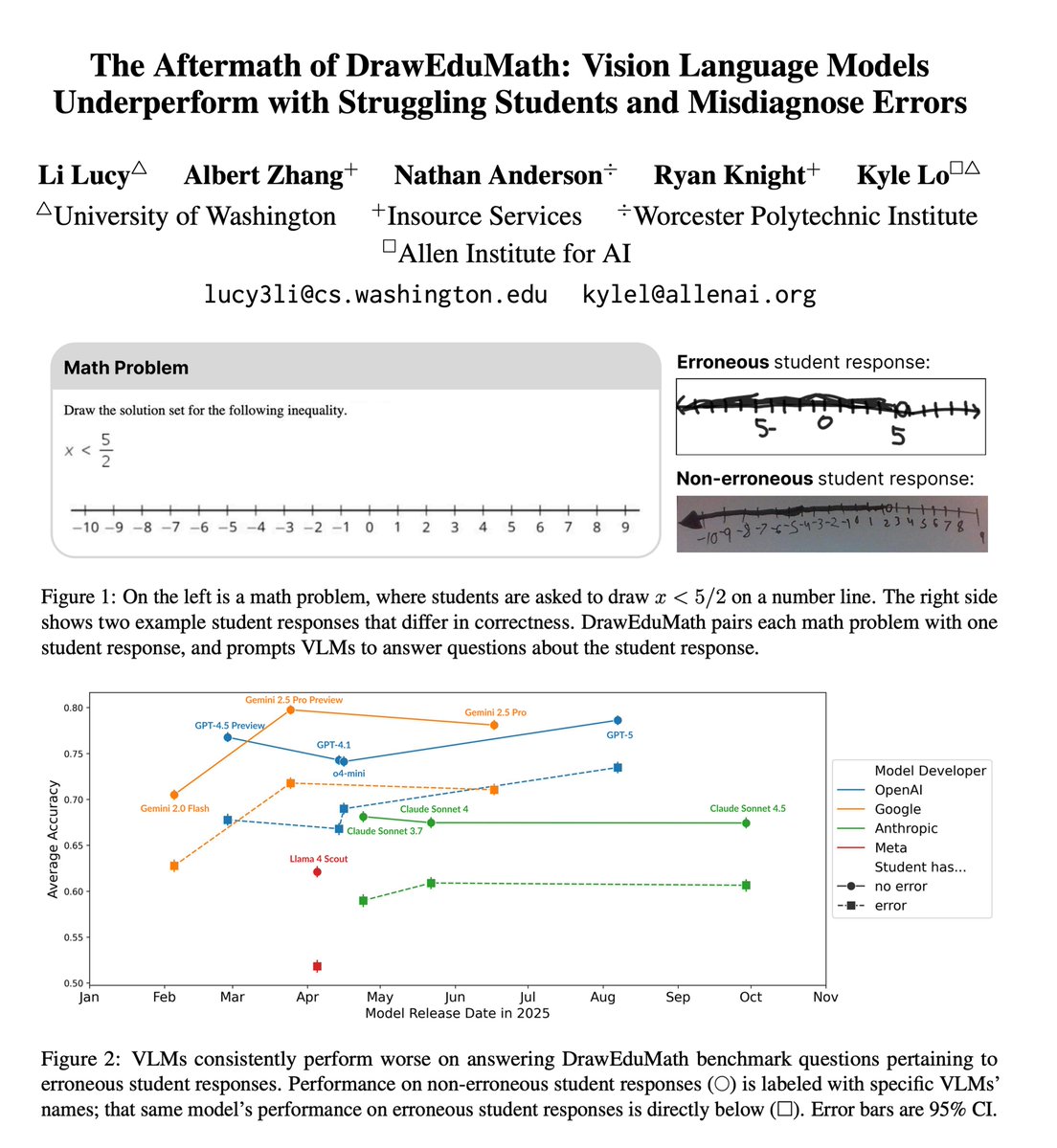
Models are now expert math solvers, and so AI for math education is receiving increasing attention.
Our new preprint evaluates 11 VLMs on our QA benchmark, DrawEduMath. We highlight a startling gap: models perform less well on inputs from K-12 students who need more help. 🧵
Can we build a blind, *unlinkable inference* layer where ChatGPT/Claude/Gemini can't tell which call came from which users, like a “VPN for AI inference”?
Yes! Blog post below + we built it into open source infra/chat app and served >15k prompts at Stanford so far. How it helps with AI user privacy:
# The AI user privacy problem
If you ask AI to analyze your ChatGPT history today, it’s surprisingly easy to infer your demographics, health, immigration status, and political beliefs. Every prompt we send accumulates into an (identity-linked) profile that the AI lab controls completely and indefinitely. At a minimum this is a goldmine for ads (as we know now). A bigger issue is the concentration of power: AI labs can easily become (or asked to become) a Cambridge Analytica, whistleblow your immigration status, or work with health insurance to adjust your premium if they so choose.
This is a uniquely worse problem than search engines because your average query is now more revealing (not just keywords), interactive, and intelligence is now cheap. Despite this, most of us still want these remote models; they’re just too good and convenient! (this is aka the "privacy paradox".)
# Unlinkable inference as a user privacy architecture
The idea of unlinkable inference is to add privacy while preserving access to the remote models controlled by someone else. A “privacy wrapper” or “VPN for AI inference”, so to speak.
Concretely, it’s a blind inference middle layer that:
(1) consists of decentralized proxies that anyone can operate;
(2) blindly authenticates requests (via blind signatures / RFC9474,9578) so requests are provably sandboxed from each other and from user identity;
(3) relays prompts over randomly chosen proxies that don’t see or log traffic (via client-side ephemeral keys or hosting in TEEs); and
(4) the provider simply sees a mixed pool of anonymous prompts from the proxies. No state, pseudonyms, or linkable metadata.
If you squint, an unlinkable inference layer is essentially a vendor for per-request, anonymous, ephemeral AI access credentials (for users or agents alike). It partitions your context so that user tracking is drastically harder.
Obviously, unlinkability isn’t a silver bullet: the prompt itself still goes to the remote model and can leak privacy (so don't use our chat app for a therapy session!). It aims to combat *longitudinal tracking* as a major threat to user privacy, and its statistical power increases quickly by mixing more users and requests.
Unlinkability can be applied at any granularity. For an AI chat app, you can unlinkably request a fresh ephemeral key for every session so tracking is virtually impossible.
# The Open Anonymity Project
We started this project with the belief that intelligence should be a truly public utility. Like water and electricity, providers should be compensated by usage, not who you are or what you do with it. We think unlinkable inference is a first step towards this “intelligence neutrality”.
# Try it out! It’s quite practical
- Chat app “oa-chat”: https://t.co/ELf8LvxFzX
(<20 seconds to get going)
- Blog post that should be a fun read: https://t.co/OwFmyFlZH5
- Project page: https://t.co/Swerz1xDE2
- GitHub: https://t.co/38CeKajCy2
Many people are using RL to make models smarter.
We used RL to pull training data out of the models themselves.
Our results show that models know a lot more about their training data than most people think.
We develop Active Data Reconstruction Attack (ADRA) — a data detection method that uses RL to induce models to reconstruct data seen during training.
ADRA beats existing methods by an average of >10% across pre-training, post-training, and distillation.
Our paper, with @uwnlp, @Cornell, and @BerkeleyNLP @Berkeleyai, is now available.
Arxiv: https://t.co/B9B63vFm5P
Joint work with @jxmnop@shmatikov@sewon__min@HannaHajishirzi
Agents interact with environments to gather information. But exploration can be expensive.
Tool use, retrieval, and user interaction carry latency or monetary cost.
Calibrate-Then-Act allows LLM agents to balance exploration with cost:
📐 Estimate uncertainty about the environment
💭 Reason about cost-uncertainty tradeoffs
⚙️ Act accordingly
For this week's seminar, we are excited to host @shangbinfeng from University of Washington!
Date and Time: Thursday, February 26, 11:00 AM — 12:00 PM Pacific Time.
Zoom Link: https://t.co/jmz2wb8Xyn
Title: Protocols of Model Collaboration
Abstract: Human intelligence is compositional: there is no “general-purpose” human and we are all specialized in our own ways, while collaboration protocols guide diverse individuals to come together and achieve what they cannot on their own. Moving beyond single monolithic AI models, I aim to advance compositional intelligence through model collaboration, where multiple (language) models collaborate, compose, and complement each other. In this talk I discuss three specific protocols of model collaboration: Model Swarms, multiple LMs collaboratively search in the model weight space for adaptation; Sparta Alignment, multiple LMs collectively evolve via competition and combat; and Switch Generation, pretrained and aligned stages of LMs take turns to generate segments of responses to patch the tradeoffs of RL/alignment. These protocols span diverse levels of model access and information exchange, spearheading a new paradigm of AI systems featuring compositional intelligence and collaborative development.
Excited to see everyone at the seminar!
Really interesting reward modeling approach that works well for small LLM judges: https://t.co/ra5r8e4uzQ
Generally, small language models (SLMs) aren’t great judges, but there are tons of situations where using these models as a judge would be useful (e.g., large data filtering jobs or as a reward model in RL to improve efficiency). This paper argues SLMs struggle with evaluation due to a validation-generation gap: these models can generate a plausible completion more easily than they can validate a solution.
Inspired by the validation-generation gap, this paper proposes an inverted approach. Given instruction x and prompt y, we have the SLM predict x given y. If a response is good, we should be able to “work backwards” from it and recover the original instruction. And, we can easily derive a reward signal from this by measuring similarity between the predicted instruction x’ and the actual instruction x (e.g., using word-level F1). This similarity can be directly used as a reward signal or for preferences / ranking.
This reverse setup works really well for relative scoring. For example, when used to evaluate SLMs on (preference-based) RewardBench2, the backwards approach drastically outperforms direct assessment scoring. This approach also works well with best-of-N sampling. We also see benefits when this approach is used for reward modeling in GRPO, where the biggest benefits are seen with smaller judges.
Checkout FLIP, a new reference- and rubric-free reward modeling method that allows much smaller LMs to excel under test-time scaling & GRPO training!
Check @yikewang_ 🧵 below
Small language models are not very helpful as judges, how about 🔄 backward inference—inferring the instruction given only the response, and using the similarity between the inferred and the original instructions as the reward signal?
Introducing ⚙️FLIP, a reference-free and rubric-free reward modeling approach that boosts the RewardBench2 performance of 13 small language models by an average of 79.6%, and substantially outperforms LLM-as-a-Judge under test-time scaling via parallel sampling and GRPO training.
📄paper: https://t.co/X1G5nrN2mx
🔗code: https://t.co/ArM5wPqYYy
[7/n] Qualitative analysis shows that FLIP effectively captures several major categories of rejected or low-quality responses, including:
▪️Off-topic or irrelevant responses
▪️Factually incorrect responses
▪️Under- or over-addressed responses
see examples at https://t.co/X1G5nrNAc5








































![yikewang_'s tweet photo. [8/n] We also show that FLIP is robust to common forms of ☠️adversarial prompts / reward hacking. https://t.co/1R6VzMCp1p](https://pbs.twimg.com/media/HBclbgSa4AAbjC8.jpg)



















