@agupta There is a circular economy at the heart of the current agentic industry, namely the relationships between Nvidia, Oracle and OpenAI is somewhat incestuous rather than symbiotic.
This should phase out over time, but it's not a bad take on current affairs.
Testing harness + model combinations is better data than model-only leaderboards. But SWE-Bench-Pro-Hard is not your codebase. The decision layer you need is per-agent-instance, scored on your own sessions.
Food for agentic thoughts.
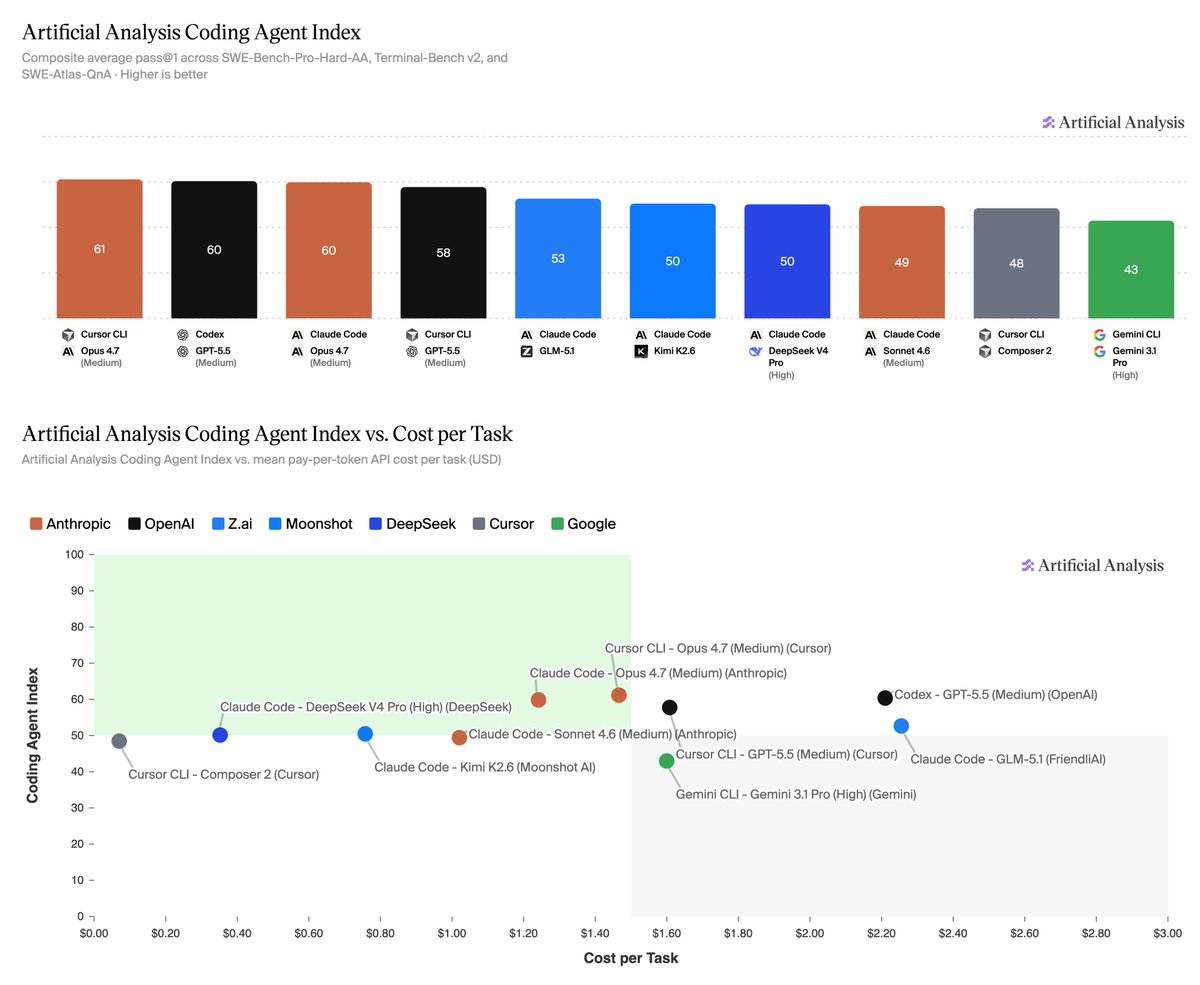
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
@johncrickett You had me at judgment. The part that often gets missed: judgment requires a receipt. When you're approving agent work without a session trace, you're not exercising judgment. You're hoping.
@milesdeutscher The workflow composability is real. Buuuuut, running 100 instances through it without a trust profile for any of them is just scaling the guess.
@levie Cost routing gets you to the right model tier. The harder problem is that the same model behaves differently across codebases, contexts, and session histories.
"As AI agents become the labor layer, every enterprise will need an independent control room to decide which agents are trusted, routed, governed, and funded. Worldline is that control room."
- @_sumeetc
Before your next PR review: open the session trace, not the diff. Count files the agent touched that weren't in the task. Most teams never look.
Two instances of the same model will have different counts. Most engineers treat the diff as the receipt. It is not.
#DYOR
Most engineering teams describe their coding agent problem as a quality problem.
The model hallucinated. The review was shallow. The commit message lied about what changed.
None of that is a quality problem. It is a trust problem. And the two have different solutions.
@emollick Every firm getting value from AI today is shipping agent output no one at the firm could reconstruct.
The real challenge tho, is what happens when you have 50 engineers doing that instead of 5.
@leerob Lee, you had me at verify! 😄
Devs also need to verify the agent. A test suite catches bad output, but doesn't tell you whether instance A reasoned through the auth refactor or just pattern matched its way to a passing test.
The replacement is not a better benchmark. It's a session-level record: what the agent actually did, scored per run, accumulated as a trust profile for each instance.
Reasoning. Compliance. Efficiency. Collaboration. Initiative. That is the evidence. Not the rank.