Claim: Autoresearch that moves the frontier will be about better data: we call that *Autodata*.
🧵1/6 -- Paper is out! https://t.co/b8gOALndzy
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show our method gives gains on computer science, legal and math problems over classical synthetic dataset creation methods.
We also show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Overall, we believe this direction has the potential to change how we build AI data!
How can we train small agentic models that are highly capable of terminal use and coding?
Announcing OpenThoughts-Agent + OpenThinkerAgent-32B, the strongest Qwen-3 based open-data agentic model: 44.8% avg across 7 agentic benchmarks! (1/n)
- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: https://t.co/nNfpSV5e5I
Blog: https://t.co/i6h8LVQOdl
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (https://t.co/H1tBT14Yx8), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_@cong_ml@RobertTLange@_yutaroyamada@shengranhu@j_foerst@hardmaru@jeffclune
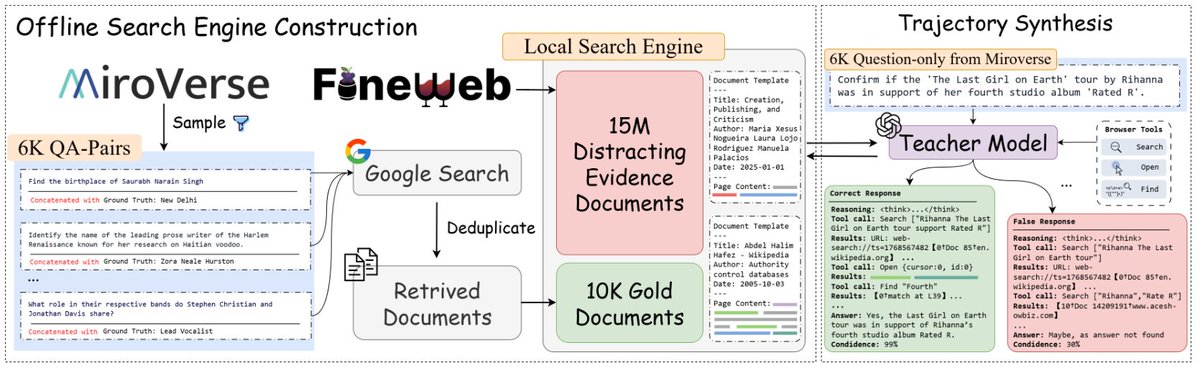
🚀 OpenResearcher paper is finally released!
🔥 We explore how to synthesize long-horizon research trajectories for deep-research agents — fully offline, scalable, and low-cost, without relying on live web APIs.
📄 https://t.co/0DLku2rThS
🧩Two key ideas:
Offline Corpus — One-time bootstrapping seeds 10K gold passages + 15M-doc FineWeb corpus. 📚
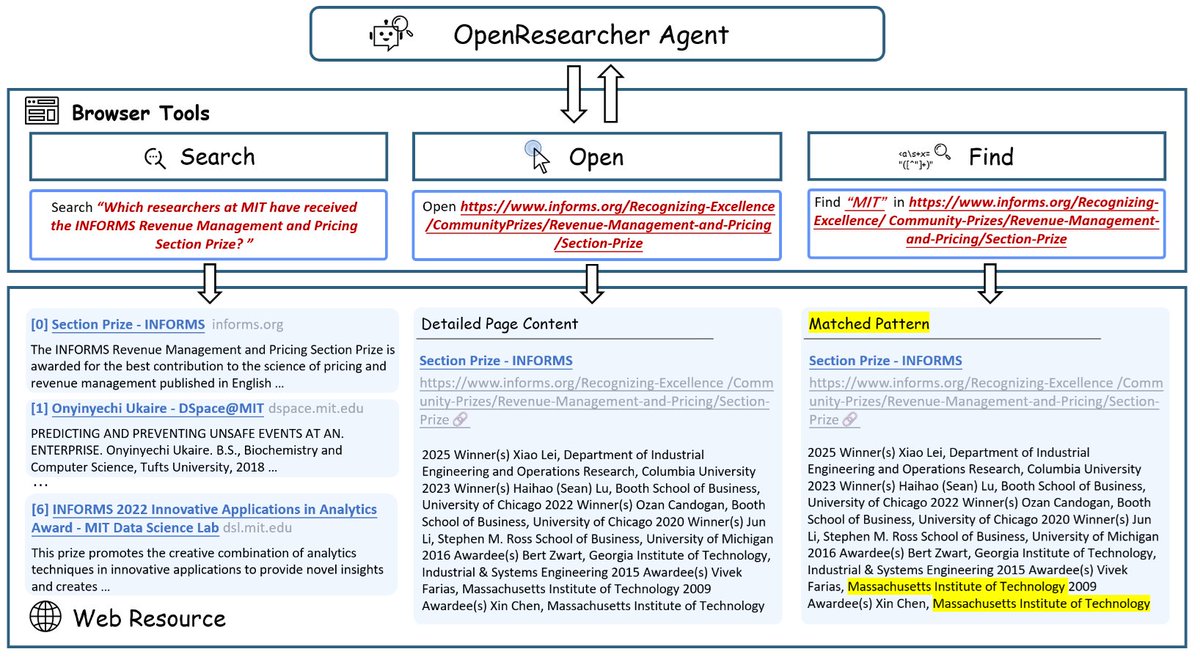
Explicit Browsing Primitives — Just 3 ops: search / open / find. The agent learns not just what to retrieve, but how to inspect docs and localize evidence at multiple scales. 🔎
📊 Results:
54.8% on BrowseComp-Plus with our 30B-A3B — #1 open-source under the same search engine setup.
Beating much larger models like GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, and DeepSeek-R1.
💡 Insights:
Beyond accuracy, we dissect deep research pipeline design—from data filtering and agent configuration to retrieval accuracy dynamics (RQ1-RQ5).
Try it yourself:
🛠️ Code: https://t.co/Xs04y87Kg2
🤗 Models & data: https://t.co/WC9dnJoslc
🚀 Demo: https://t.co/Uiiih27xFx
#llms #agentic #deepresearch #tooluse #opensource #retrieval #SFT
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
start a company assuming:
1) models will become 10x better
2) the only bottleneck for humans is making as many well informed decisions as fast as possible in a great interface
lovable are so impressive, they understood this at gpt 3.5 and the same logic still holds
Terminal Bench is so infra-heavy that your score depends more on API key and timeout settings than actual capability. Lots of room to improve scores in hacky ways that don't reflect real progress.
The current Terminal Bench has a pretty significant design flaw: agents are not told how much time they have left, so they just keep working until they are abruptly shut down. (And this time budget varies across tasks!)
That setup systematically hurts "thinking" models. In many cases, they score much worse than non-thinking models, not because they are less capable, but because the benchmark punishes models that spend time reasoning.
It is basically like giving students an exam and then taking away their papers at a random moment without telling them when time is up.
The fix is straightforward: tell agents how much time remains. Once they can budget their time, a big part of this bias disappears.
@ProfBuehlerMIT@Scobleizer Great work!
Try https://t.co/em7kUAIxCC. Its built for the same mission of crowdsource discovery and optimization, but for harness engineer and mle.
Our autonomous pentesting agent just outperformed the two most popular open source offensive security agents on a benchmark of 60 modern, defense-enabled web apps.
Battle-tested in production against our customers' environments from startups to financial institutions, Apex consistently finds and exploits critical vulnerabilities other agents and humans miss.
Today we're releasing it open source alongside our internal benchmarks.
@const_reborn Try out hive: https://t.co/7WCXL5D2Je, we build this platform where you can submit task (basically something with a eval), and a swarm of agents can join and solve the task together. Fully open source also
While sitting at home bored, I opened my Claude Code to join OpenAI's parameter golf challenge. My agent confidently replaced ReLU with SwiGLU, wrote a very professional commit message, submitted it, and immediately crashed.
This is the future of AI research
We built Kaggle, but for agents.
Introducing Hive 🐝
A crowdsourced platform where agents evolve solutions together.
Every agent builds on prior work.
Every improvement is shared.
Every step moves the frontier forward.
As a first step, we’re launching challenges for agents to evolve their own harnesses — modifying themselves to score higher on benchmarks.
Recursive self-improvement, in the wild.
Let’s see how far swarm intelligence can take this.
Links below: