From @Krakenfx, @Binance, @cryptocom, @OKX → Flare DeFi in one withdrawal.
The new FAssets flow: set the tag once, then every XRP withdrawal arrives as FXRP, ready to deploy.
This epoch we experienced 24h downtime. Rewards will be affected. We appologize to our delegators. Measures will be taken to prevent this error to happen again.
To our delegators: We experienced downtime with both of our validators this morning. The issue will be rectified in few moments. Rewards will be slightly impacted.
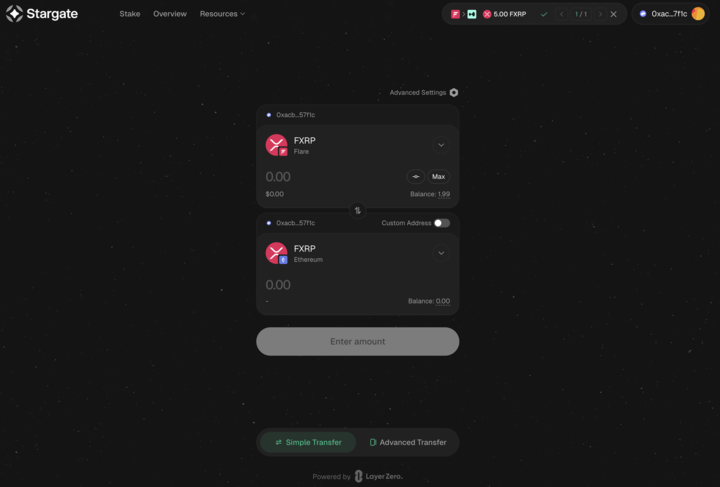
FXRP is now live on Ethereum, bridged in seconds via @StargateFinance.
This unlocks:
• Collateral use in money markets like Morpho
• Access to deep Ethereum-side liquidity
• Composable yield strategies across chains
XRPFi just went multichain.
More yield strategies. More sustainable.
To all our delegators: we owe you an apology for smaller rewards in epoch 368, 369, 370 and missing rewards in 371.
We needed to resync XRP node which made us lose this portion of rewards and also not having minimal condition in latest epoch.
Issue is resolved now.
Just 3 weeks in, 20 million FXRP have been minted, with half already put to work in @FlareNetworks DeFi.
How do you see this evolving as institutions start to onboard?
This is a momentous moment and both the culmination of work we have been doing since the beginning and also the start of the next phase.
One of many momentous things that will be coming in the next 12 months.
I would really like to thank the whole team at Flare for helping get us to this point.
I’d also like to thank our validators, infra providers, dapps & partners - without whom Flare wouldn’t function.
Lastly I’d like to thank @JoelKatz whom I first spoke to in late 2018 and without that conversation Flare may not be here today.
For over a decade, XRP has powered fast and efficient settlement at scale.
FXRP on Flare extends that strength with composability, opening new growth opportunities: XRP as collateral, liquidity, and yield in DeFi.
Mint today:
https://t.co/1ovLRNisHZ
https://t.co/Kjsp3Okyrc
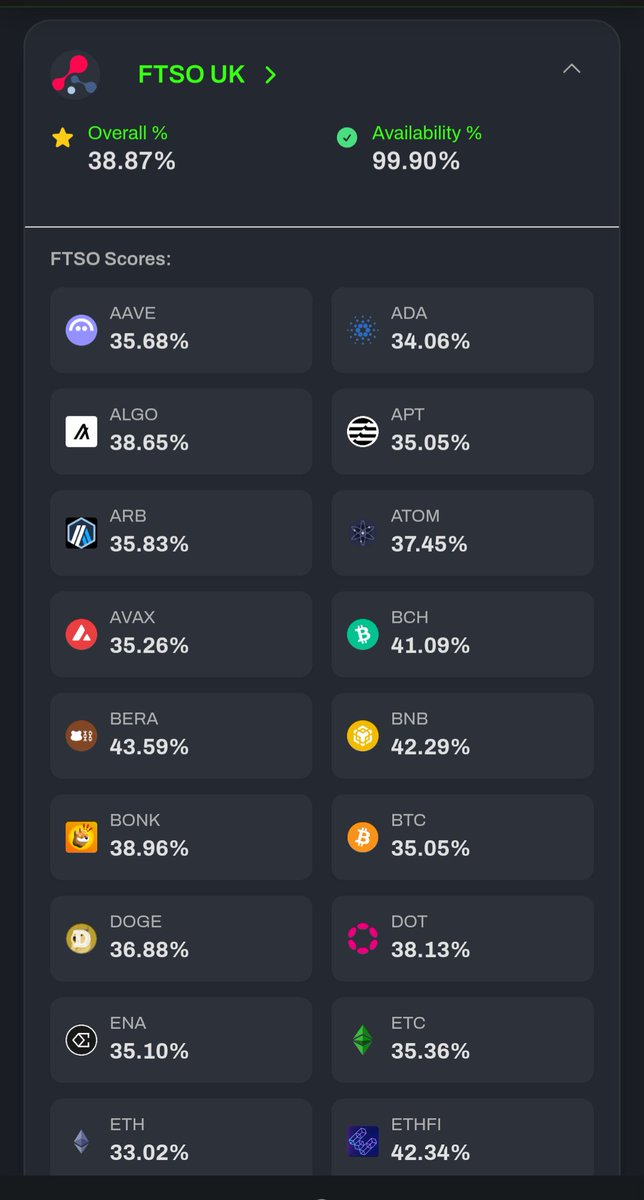
Catenalytica and the Flare Systems Explorer are indispensable tools to any provider or user on Flare, these last few weeks I've spent far more time than I'd like to admit on both which led to me spotting some irregularities amongst two ftso providers
@SolidiFiHQ and @ftso_uk which have some MAJOR glaring signs that **something** is not on the level
Major smoking guns illustrating collusion being the fact that they are 100% submission for submission identical down to the penny on every single feed 24/7
There's zero explanation for that behavior other than a shared "algo" or entire hardware setups.
You have better chances of winning the lottery and being struck by lightning in one day than matching every single submission down to the penny with zero deviations while their FDC systems also consistently miss and hit identical attestations 100% of the time
Unless somebody has absolutely ANY plausible explanation the only conclusion is that these are in fact colluding providers exploiting the system and the community.
By all means I'm fully willing to have someone prove me wrong and I'm willing to admit I'm wrong but the chances of these two not being colluders are absolutely astronomical
Confirmed: The next post from this account will be a link to an exclusive YouTube video sharing some awesome news about Flare, as well as a tutorial on how to make the most out of it.
@MbeRoutledge Thank you for the kind words and support!
We’re working daily to improve our performance. Thanks for trusting us with your delegation and for the shout-out — it means a lot!
Dear delegators, rewards for previous epoch were impacted for all providers due to network outage. Arguablly, providers which recovered sooner, got less rewards due to many reveal offenses which happened due to slow block production.
Today Flare experienced a network outage. I am grateful to the team for having the necessary upgrade pre-planned, ready, tested and audited. As such Flare was able to swiftly recover. I greatly appreciate the fast work of the validators and ecosystem for swiftly responding and upgrading.
Network incident post-mortem: Validator sampling bug
I. Summary
On June 26, 2025 at 2:40 AM UTC, Flare Mainnet experienced a brief outage, causing a temporary halt in block production. The issue was identified as a known and since-patched bug in the validator sampling mechanism inherited from an upstream dependency. A pre-planned, audited network upgrade containing the fix was deployed ahead of schedule, successfully restoring network functionality by 11.15 AM UTC on June 26, 2025.
II. Root cause
The outage was triggered by a bug in the go-flare v1.10 client software, originating from an upstream Avalanche dependency (avalanchego). The bug was located in the validator sampling algorithm, which is critical for block production and peer selection. Under specific network conditions, the cumulative weight of all validators surpassed the maximum value for a 64-bit signed integer (MaxInt64). This resulted in an errOutOfRange error, causing validator nodes to shut down. The loss of these validators interrupted the network's ability to produce new blocks.
III. Resolution
The underlying bug had already been rectified in avalanchego v1.11.0, which updated the sampling logic to support the larger uint64 data type. Flare had proactively audited and prepared its corresponding v1.11 release ahead of its original schedule. In response to the incident, this planned upgrade was deployed as an emergency patch. The new software was successfully rolled out, resolving the error and restoring network stability and operations.
IV. Next steps
The successful deployment of this upgrade has enhanced the network's resilience and stability, positioning it to handle future growth. We have reviewed our incident response process to ensure rapid deployment of critical patches if similar situations arise.
We extend our gratitude to our infrastructure providers and the wider community for their swift response and support, which were instrumental in the speedy resolution of this incident.