Hello everyone!
We are organizing a human review process for papers generated by FARS and are now recruiting volunteer reviewers to participate in evaluating these research outputs. If you are interested in taking part, please fill out the application form: https://t.co/eJskTAMIzs
If your application is a good fit, we will contact you via email with instructions on how to participate in the review process. For volunteer reviewers who complete the full review process, we will offer the following in appreciation of your contribution:
📝You will be listed as an author of the FARS Review Report (in alphabetical order by name).
✨$500 in non-expiring credits, granted after FARS launches as a product feature.
Thank you for your support. We look forward to working with you to help reshape the future of scientific discovery.
Update on the End of the FARS Live Deployment
The first public live deployment of FARS (Fully Automated Research System) has successfully concluded. We sincerely thank everyone for the attention, feedback, and support given to FARS.
Key updates:
1. On March 3, 2026, the FARS livestream ended. All papers and code generated during the deployment remain available on https://t.co/Doz2ERClQo.
2. Some FARS papers have been reviewed using Stanford Agentic Reviewer (https://t.co/KKXIQfLeLe). These results are available on the website but do not represent Analemma’s official evaluation. We are organizing a systematic human review, and will soon invite external reviewers to participate and oversee the process. A quality assessment report will be released afterward.
3. Due to arXiv policy restrictions, generative AI cannot be listed as paper authors. We are exploring other indexable channels to distribute selected FARS papers that pass human review, so their citations and impact can be tracked.
4. Later this month, we will launch a product, providing research assistance features and automated research capabilities as FARS demonstrated.
We will continue iterating as we aim to turn scientific discovery from a human-limited craft into scalable industrial production.
Analemma Team
#AI #LLM #Research
@linkangd@AnalemmaAI Thanks for the review! Current version of FARS targets on focused contribution that aligned with "short papers". And yes, AI Scientist (v2) are awesome works.
Milestone update: FARS has been live for 39:33:37 — and has already produced 10 research papers.
Check details of the produced papers:
🔴 FARS research runs - https://t.co/Wqq8Z6WoR3
📦 Github - https://t.co/8HkrGYnyIG
Today, we’re introducing FARS — a Fully Automated Research System.
Tomorrow at 10:00 PM Eastern Time, we’ll begin its first public deployment as a live experiment.
During the deployment, FARS will run continuously and autonomously, aiming to produce 100 complete research papers.
This deployment is intended to study what automated research looks like at scale.
🔴 Live: https://t.co/v72yQVd0oB
📃 Blog: https://t.co/gh4Nc2Ufaj
📦 GitHub: https://t.co/a9vN1QIbK4
👾 Discord: https://t.co/dwRD3ijoBK
#AI #LLMs #research
🚨 New release: MegaScience
The largest & highest-quality post-training dataset for scientific reasoning is now open-sourced (1.25M QA pairs)!
📈 Trained models outperform official Instruct baselines
🔬 Covers 7+ disciplines with university-level textbook-grade QA
📄 Paper: https://t.co/tW6Qjv54L5
🤖 Data & Models : https://t.co/TS0wyk7QbF
💻 Code: https://t.co/Q5ydfeIgKQ
🎯Evaluation System: https://t.co/YIRzG2tzKk
Details 🧵👇
1. Why MegaScience?
While LLMs like o1 and DeepSeek-R1 excel at math & code, they still struggle with science reasoning — largely due to the lack of large-scale, high-quality datasets.
2. What makes MegaScience different?
We address 4 core challenges:
🧪 Unreliable benchmark evaluation
☢️ Less rigorous decontamination
❌ Low-quality reference answers
🧠 Superficial knowledge (data) distillation
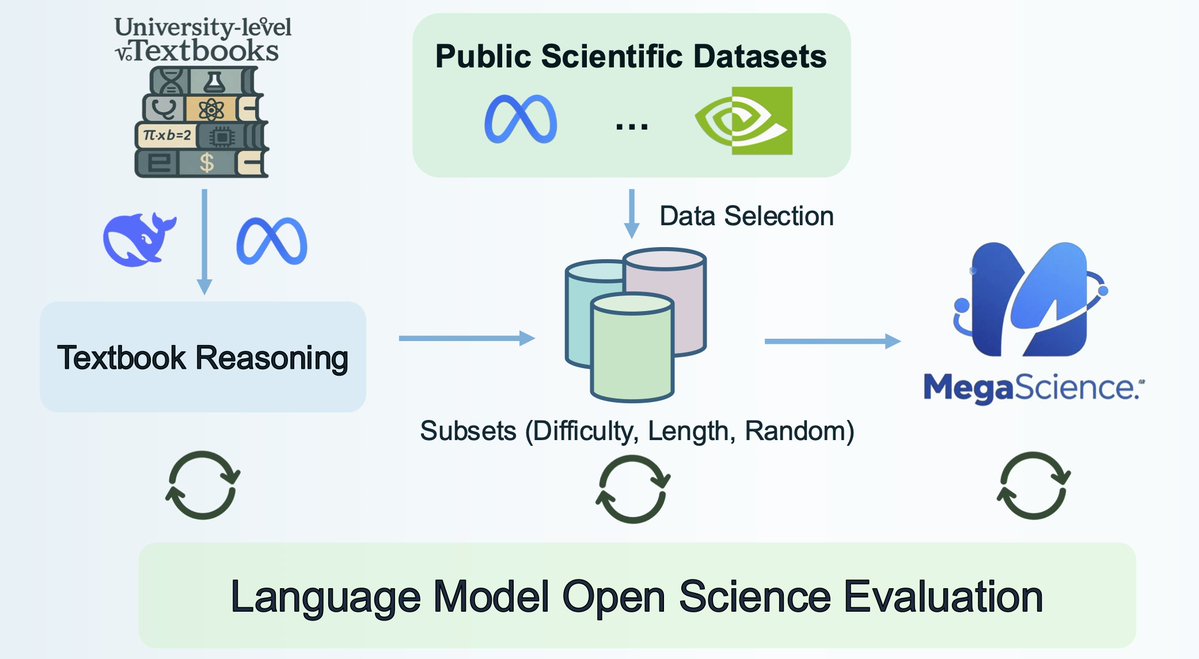
3. We tackle this from the ground up.
First, we introduce TextbookReasoning:
📘 Built from 128K+ university-level science textbooks
⚙️ Fully automated LLM-driven pipeline
🧠 650K QA pairs with reliable reference answers
🌍 Covers 7 major disciplines
4. But we didn’t stop there.
We then construct MegaScience — a diverse, hybrid dataset of 1.25M QA pairs, using:
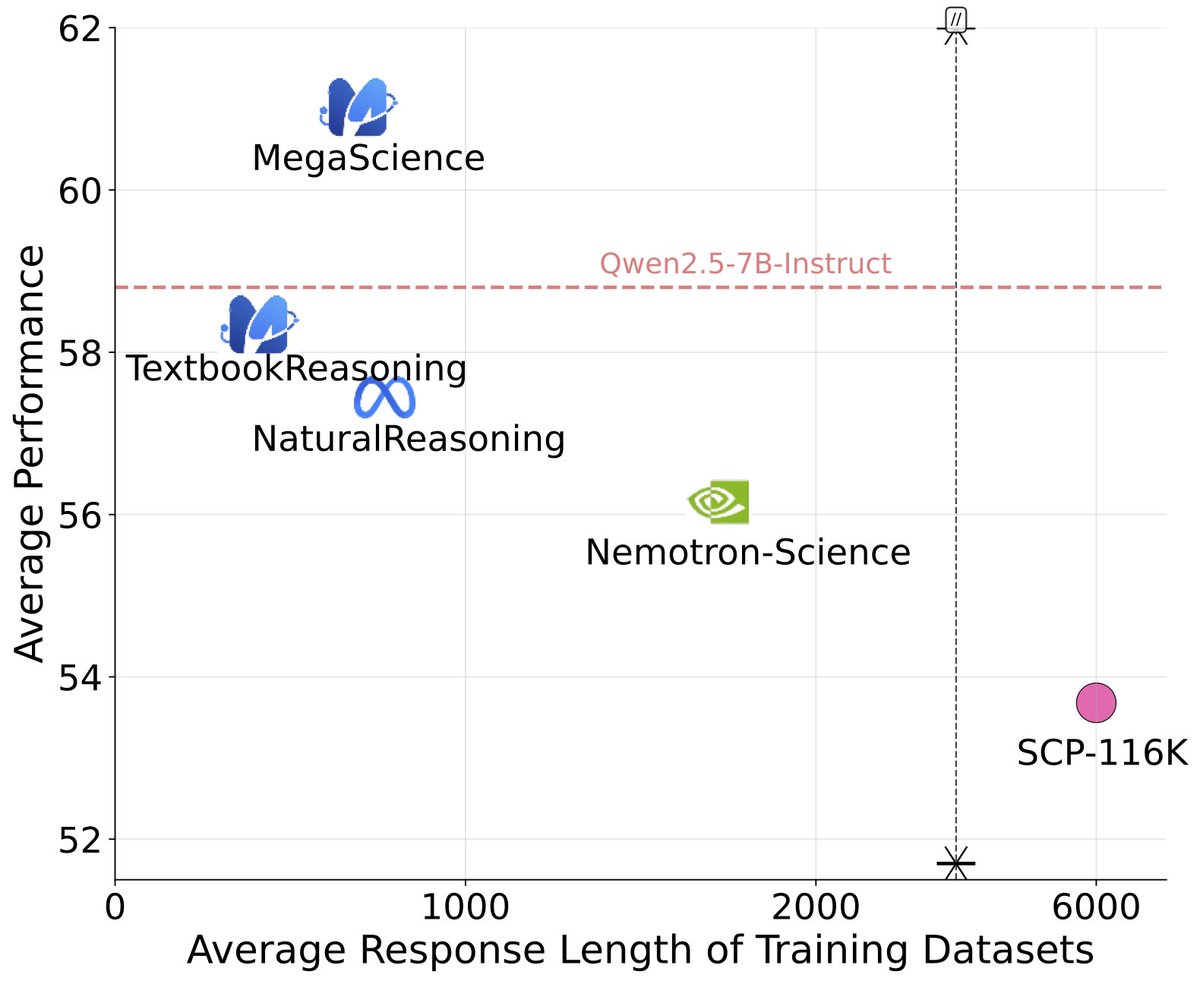
* TextbookReasoning
* NaturalReasoning
* Nemotron-Science
We conduct comprehensive ablation studies across different data selection methods to identify the optimal approach for each dataset, thereby contributing high-quality subsets.
5. To evaluate properly, we also open-sourced a reproducible and flexible Scientific Reasoning Evaluation framework with:
* 15 science reasoning tasks
* Multiple question formats (MCQ, calc, open-ended)
* Multi-GPU parallelism & model-agnostic evaluation
* Comprehensive answer extraction strategies
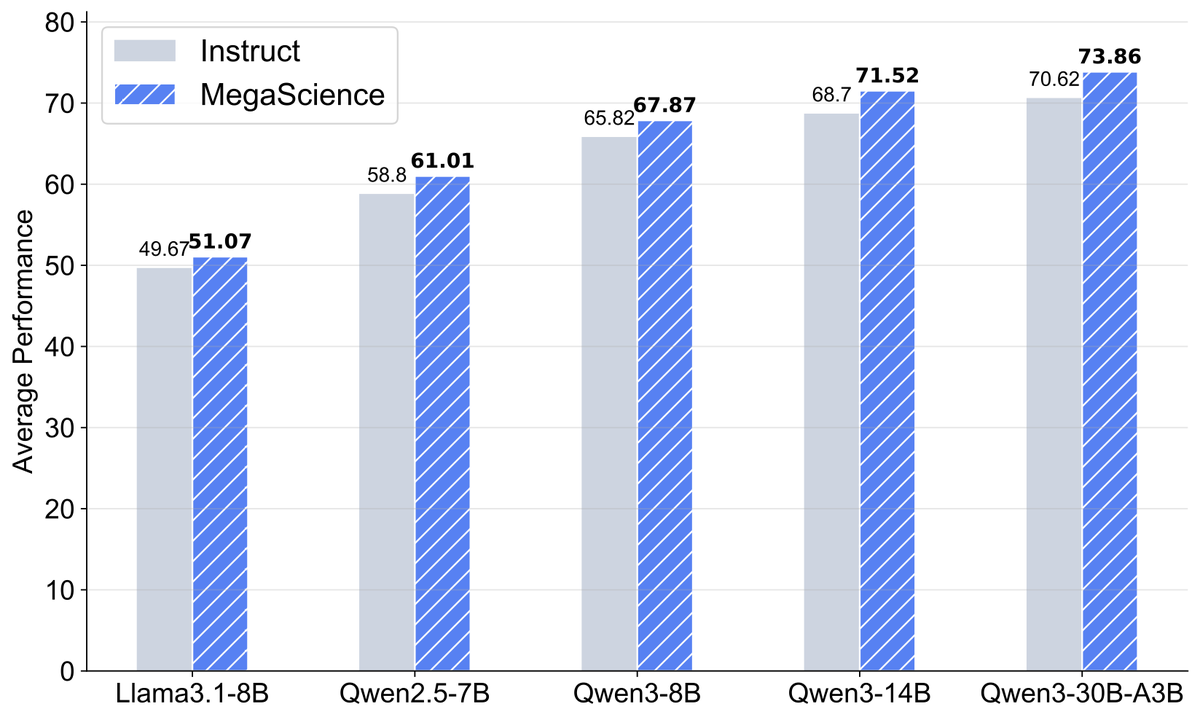
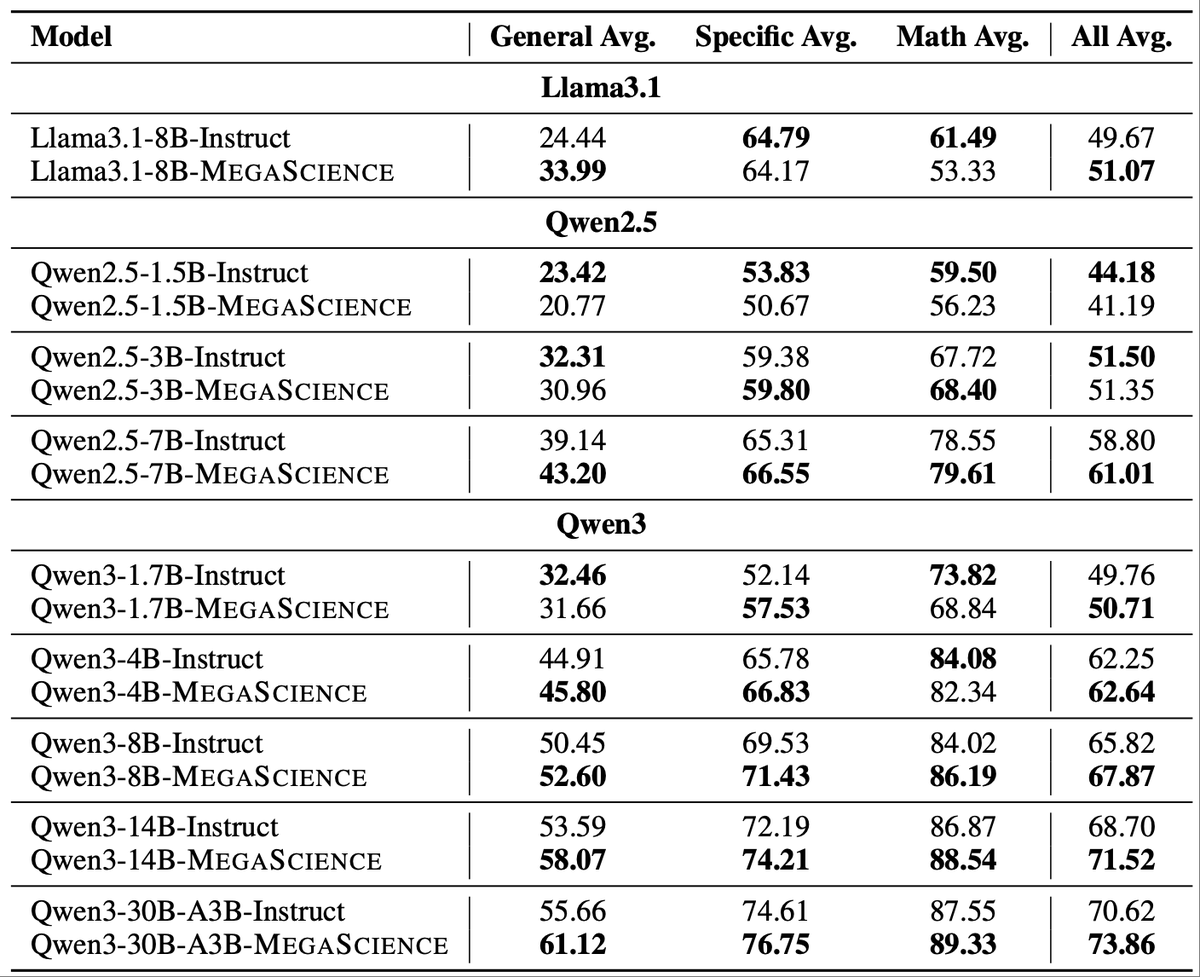
6. Results:
Models trained on MegaScience consistently outperform official Instruct versions — especially for Qwen3 series.
Bigger models see greater gains, showing strong scalability.
7. Everything is open-source:
📚 Dataset
🧪 Evaluation toolkit
🤖 Trained models
🔧 Codebase
→ Let’s build better science agents together!
This work is impossible without all the brilliant co-authors @SinclairWang1@stefan_fee
@NielsRogge@OpenAI This a very nice figure illustrating multi-turn reinforcement learning with tool use 👍
You might be interested in DeepResearcher we released early this month, which applies RL training with real-world web search.
Paper: https://t.co/7dDU1uiHsO
Code: https://t.co/uyGLGWRT1H
🔍Exciting to introduce DeepResearcher, the first end-to-end trained #DeepResearch model with #RL scaling in real-world environments!
✨No more controlled simulations - this is RL in the wild with authentic search interactions!
Paper: https://t.co/7dDU1uiHsO
1/7
🚀 Try our model yourself or contribute to the project! Let's advance the frontier of AI-assisted research together!
Code: https://t.co/uyGLGWRT1H
Model: https://t.co/uImh9VPeu2
6/7
🤔Can LMs learn to skip steps to improve reasoning efficiency while maintaining accuracy?
✅The answer is Yes! In our #NeurIPS 2024 work, we show this behavior boosts efficiency, maintains accuracy, and even enhances generalization in OOD scenarios!
🚀https://t.co/U3gwUg228Y
🧵⬇️
Amazon has publicly released RefChecker, a combination tool and dataset that detects hallucinations in #LLMs. To characterize factual claims, RefChecker uses knowledge triplets rather than natural language, enabling finer-grained judgments. #GenerativeAI https://t.co/uP1bi3hmMk