Proud of our team that makes the huge leap happen compared to last version but this is just the start. Better models are lined up and we keep improving every week. Join us towards Superhuman Multimodal Intelligence https://t.co/66VPFDgMRy !!
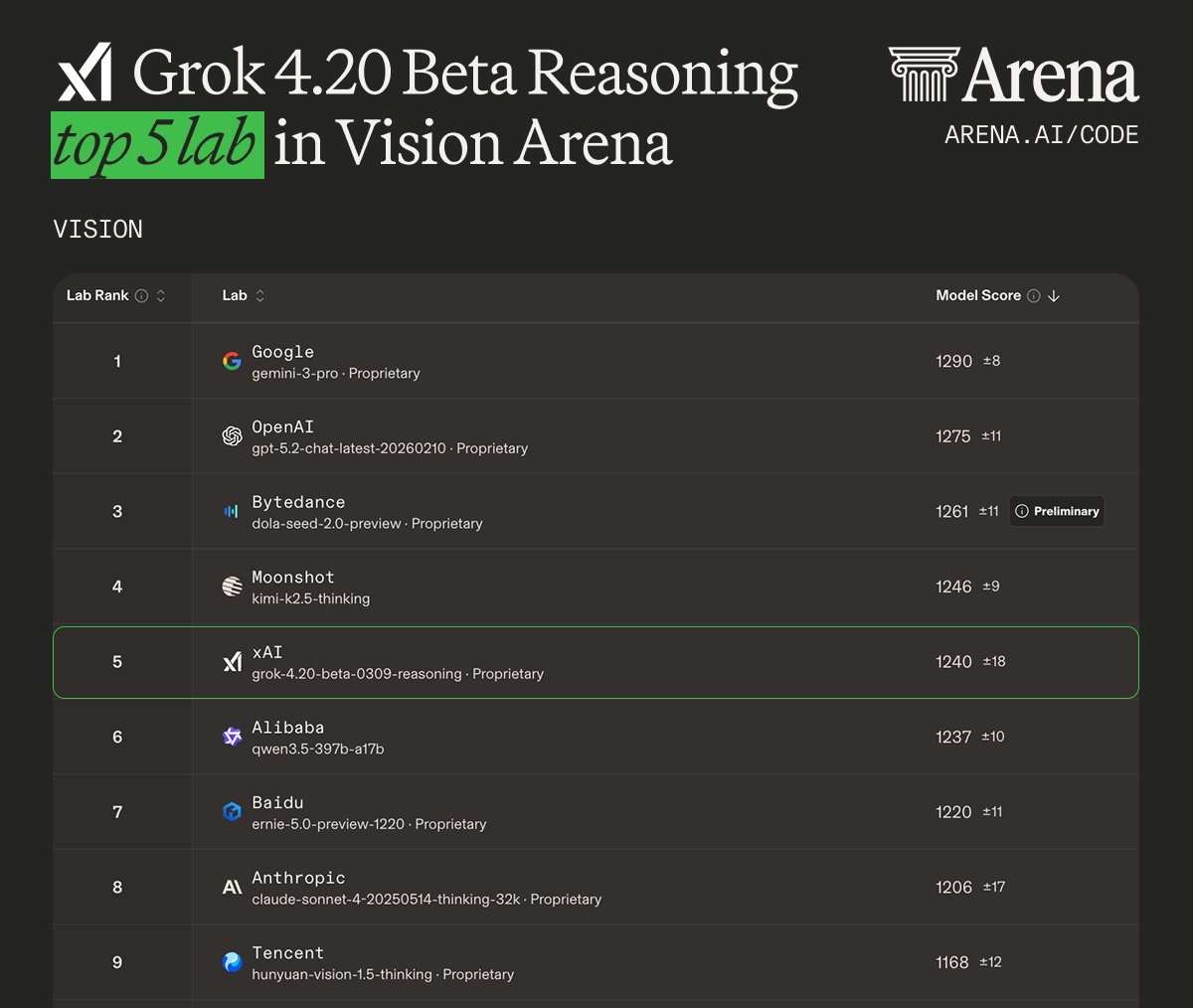
Grok 4.20 Beta Reasoning makes @xAI a top 5 lab in Vision Arena.
Scoring 1240, this model ranks #11 across all Vision models today.
Congrats to the @xAI team for this milestone!
Tip on Grok Build + Grok 4.3 VLM
One of my critical tasks is to keep Grok VLM in the loop. Throwing a default system prompt usually yields poor results due to lack of context.
Here is how to scale:
- Curate a small but diverse evaluation set that can be rapidly iterated on.
- Enter the prompt: “Make a plan to design and execute a task that a) takes input per entry from: <input>, b) generates output per entry to: <output>, c) the ground truth of output: <ground truth>. Launch sub-agents to iterate on strategy to optimize recall and precision against ground truth until both metrics reach <threshold>.”
Done. Watch your research agents do the work.
Grok foundation model V9-Medium (1.5T) has finished training. Evals look good. A lot of Cursor data was added in supplementary training and there is more to come.
Fine-tuning is underway and reinforcement learning begins in a few days. 2 to 3 weeks to public release.
This will be a major improvement over the 0.5T v8-small that currently serves all Grok production traffic, especially for difficult coding tasks.
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20
The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite.
Key Takeaways:
➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level
➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula
➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2
➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3
Congratulations to @xAI and @elonmusk on the impressive release!
SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI.
The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models.
Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
Just shipped our best “Quality” mode model with a fresh new Imagine model 💫 — live at the earliest we could make it available.
Clear quality gains already, and we’ll keep refining it fast with your feedback. All input welcome. Onward.
@xdNiBoR The future of AI is primarily video understanding and generation, because photons are by far the highest bandwidth form of communication. These are essential tools for AGI.
Worth mentioning that Imagine is positive gross margin for @xAI, not a money loser.
Proud of our team that makes the huge leap happen compared to last version but this is just the start. Better models are lined up and we keep improving every week. Join us towards Superhuman Multimodal Intelligence https://t.co/66VPFDgMRy !!
Grok 4.20 Beta Reasoning makes @xAI a top 5 lab in Vision Arena.
Scoring 1240, this model ranks #11 across all Vision models today.
Congrats to the @xAI team for this milestone!
BREAKING: Grok Imagine by @xai takes 1st overall on Video Editing Arena, with an overall Elo of 1290.
The team's debut video editing model establishes a new Pareto frontier for Preference vs. Speed with an average generation time of 1 min 5 sec.
Congrats to the @xai team for this achievement!
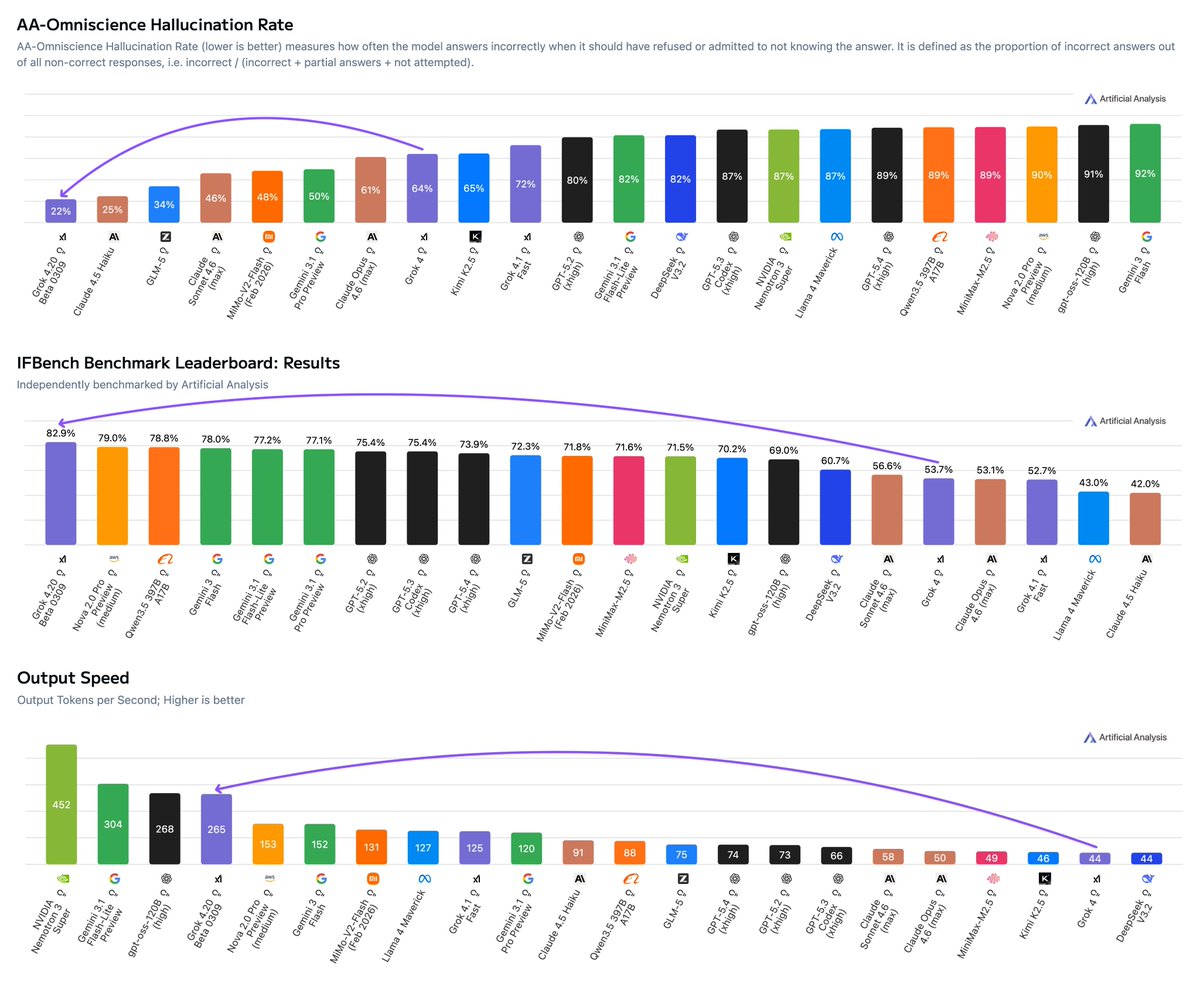
The Grok 4.20 Beta shows three major improvements over Grok 4:
➤ Our lowest ever hallucination rate on the AA-Omniscience evaluation. When Grok did not know the answer, it hallucinated an incorrect answer 22% of the time - this is the lowest hallucination rate of any model we have tested, topping Claude Haiku 4.5 (25%)
➤ Top scores for instruction following and prompt adherence. On IFBench, Grok 4.20 takes the #1 spot with 82.9% - a +29.2 point increase on Grok 4
➤ Leading speed for its intelligence. At 265 tokens per second output speed on xAI’s API, Grok 4.20 is significantly faster than its peer and over 2x the output speed seen from Grok 4.1 Fast
Congratulations to @xai and @elonmusk on the 4.20 Beta 0309 launch!
BREAKING: 🚀 Grok Imagine is #1
Grok Imagine now ranks #1 in the Image-to-Video Arena, beating major AI models and leading the next wave of AI video generation.
xAI continues to push the boundaries of creative AI.