Inviting applications for English Taught MA and PhD programmes at Beijing Normal University, China with scholarships
Announcement:
https://t.co/NRiBbxS8hV
My latest chapter on the Epistemic Rights and Right to Data Access in China #China (https://t.co/67FNRPs0qZ). It is published in the book Epistemic Rights in the Era of Digital Disruption (2024) (https://t.co/AafA7DLsUm). Big thanks to the editors!
🧵 The historic NYT v. @OpenAI lawsuit filed this morning, as broken down by me, an IP and AI lawyer, general counsel, and longtime tech person and enthusiast.
Tl;dr - It's the best case yet alleging that generative AI is copyright infringement. Thread. 👇
Well, proofs are here of an exciting new @OUPPhilosophy book “AI Morality” edited by the indefatigable @DavidEdmonds100, with strong representation of @EthicsInAI colleagues among the contributors. #AIethics
In this new #OnlineFirst article, @couldrynick argues that #JesúsMartínBarbero's insistence on a hermeneutic approach to understanding culture is of huge relevance today.
https://t.co/wxNB2NUBbX
🚨 BREAKING: The @nytimes vs. @OpenAI lawsuit signs massive AI-led changes to the internet as we know it. Here's what's happening:
Large language model-based AI applications need huge amounts of data to be developed, and so far, most of the data has been extracted for free from the internet (scrapping).
To get free data, AI companies rely on two main arguments:
a) that their unlicensed use of copyrighted content (such as NYT articles) to train their AI models represents a new “transformative” purpose and thus "fair use";
b) that their collection and processing of personal data from social networks and other platforms where users post content is a form of "legitimate interest" (EU) or legal unless it's against a website's Terms of Use (US);
-
On item "a," the NYT, in its lawsuit against OpenAI, brought clear arguments against fair use. A quote from the lawsuit:
"Because the outputs of Defendants’GenAI models compete with and closely mimic the inputs used to train them, copying Times works for that purpose is not fair use." (page 4)
After reading the lawsuit, I doubt OpenAI will manage to avoid the NYT's copyright fees. Hopefully, these fees will help compensate the people behind high-quality journalism, and this is good.
-
On item "b" above (EU): according to the GDPR, legitimate interest has its own requisites. Besides complying with a 3-part test, controllers have to follow data protection principles such as transparency and its specific rules.
According to Article 14 of the GDPR, data subjects (all of us) should be warned when their data is being processed by third parties and receive details about the entities processing the data.
Have any of you been warned about OpenAI and other companies using your posts to train AI systems? I wasn't.
For now, my take is that most companies developing LLMs have not complied with GDPR requirements to process data lawfully, and this processing (and any product built with this data) is illegal (at least in the EU).
To change that, as I've been advocating, they must be proactively transparent about their practices, and personal data should be taken seriously.
On item "b" above (US): websites are building code-based and Terms of Service-based barriers against scrapping. With these new walls, the only way to get access to the data would be through individual agreements with the platforms.
My opinion is that these individual agreements are a positive development, as they will end up forcing the platforms to notify people when there are AI companies using the content to train AI models (and people can decide if they continue posting or not).
-
There is so much going on, and even more to come. To keep up with emerging privacy, tech & AI challenges:
- Sign up for my weekly newsletter to receive my analyses, live conversations with experts, resources, job opportunities, and more;
- Join our 4-week privacy, tech & AI Bootcamp and dive deeper into these topics
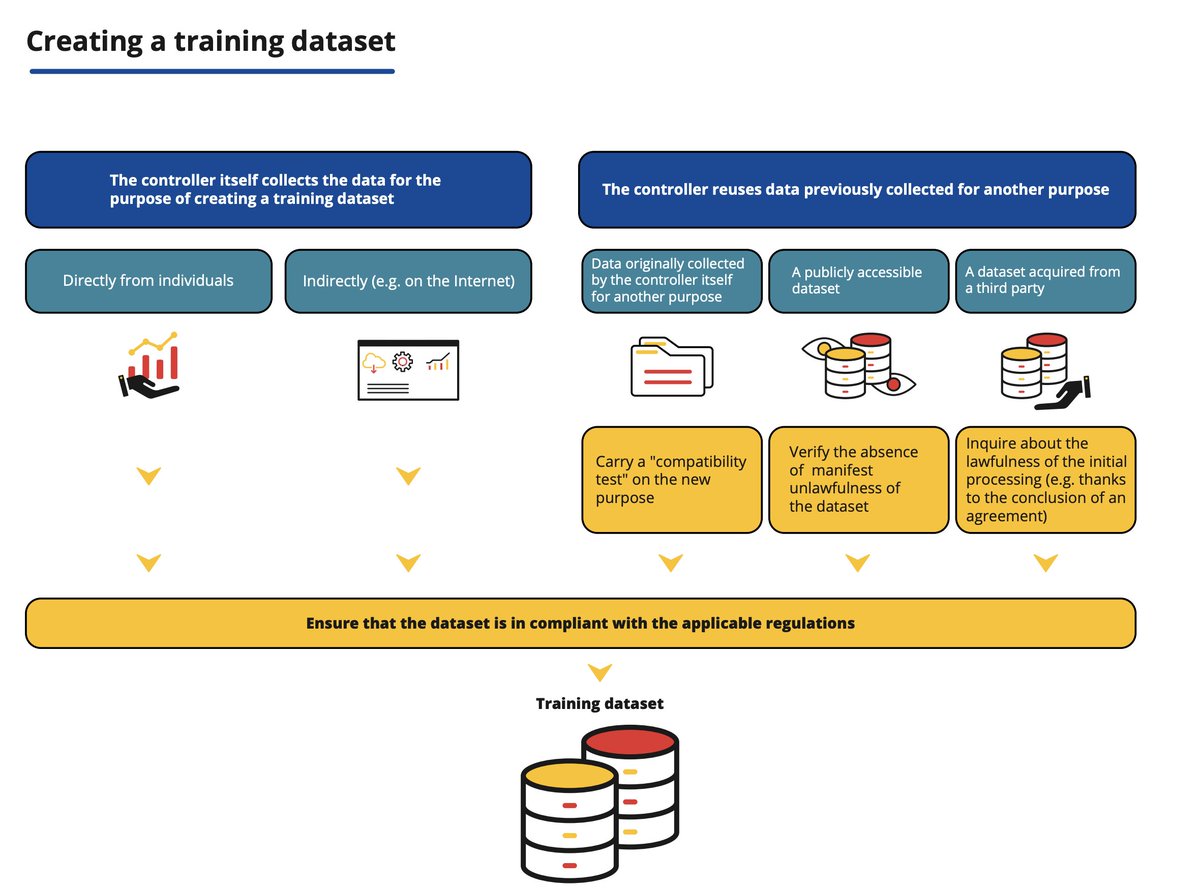
🔵 UNPOPULAR OPINION: the GDPR also applies when creating and training AI datasets - and most tech companies ignore it. This must change. Read this:
As the @CNIL's infographic below shows, regardless of the data source, data protection law must be observed when creating a training dataset.
A reminder that Article 6 of the GDPR establishes that these are the possible ways to process personal data lawfully:
- consent
- contract
- legal obligation
- vital interest
- public interest
- legitimate interested
Most AI companies developing large language models today rely on legitimate interest to scrape data from the web and train their models.
However, despite seeming an "easy" alternative, legitimate interest has its own legal requisites, including the three-part test (purpose, necessity, balancing), transparency, data minimization, and storage limitation.
Most tech companies developing AI today don't comply with any of these (and I did not mention yet data subjects' rights and other data protection principles).
With the quick and ubiquitous integration of generative AI and large language models-based capabilities into daily applications, data protection law must be implemented and made effective (or privacy rights and advancements - which took so much effort and time - will be undermined).
Privacy matters, ALSO when AI is involved.
Join our 4-week Privacy & AI Bootcamp on January 31st and learn more about it.
Agreed, @GaryMarcus. This does not mean it will be a bloodbath. You've been around long enough to know that the journey of technology is frequently met with legal roadblocks, yet history shows these are often the catalysts for POSITIVE change and negotiation. Call me a Pollyanna. But, I remember Napster (had quite the 'collection' LOL) and an iPod full of free music. The digital music era faced significant copyright issues, leading to landmark cases that reshaped music distribution and rights; it didn't kill digital music. Drones brought privacy and airspace rights into the spotlight, prompting new regulations that balanced innovation with privacy and safety. We still have drones. The advent of autonomous vehicles sparked debates over liability and safety, nudging the legal system towards new standards and accountability frameworks. I just recently rode in a Waymo driverless car in San Francisco. And, platforms like Facebook and Twitter grappled with content moderation, data privacy, and free speech, evolving legal perspectives on digital expression and privacy. So, the NYT complaint is NOT an isolated event but part of a broader narrative. These legal challenges are NECESSARY steps in the dance between innovation and regulation. They force us to redefine boundaries, negotiate solutions, and, ultimately, propel technology forward for the betterment of mankind. Speculation aside, cases like these must reach the courts to establish legal reasoning and set precedents. These are just "details to work out" so that innovation can thrive responsibly. #Pollyanna #PartOfTheProcess
OpenAI is in serious trouble.
👉The excerpt below is particularly damning, because the prompts that elicited the plagiarism in no way requested that the system draw on the NYT at all.
👉@jason_kint & @CeciliaZin largely converge on the overall seriousness of the suit.
👉OpenAI had 4+ months to prepare and cut a deal: https://t.co/UXZ3ARqqxQ; may have blundered.
👉Thrive Capital & other investors proceeded anyway at 86B valuation; perhaps could be sued if valuation drops sharply because of the lawsuit?
I've studied intelligence all my long life, yet still I feel I learned important things about intelligence by reading this book.
Thank you, Max Bennett.
Answering by approximate retrieval or by understanding+reasoning are two ends of a spectrum.
Humans are at various places on this spectrum, depending on the task, experience, and depth of understanding.
We see this in physics or math students: some will study very hard, do lots of problems, learn solution templates, and get a passing grade. Others will barely study and get top grades. The difference? Mental models that enable reasoning.
The same is true for AI. Current LLMs are pretty close to the "retrieval" end of the spectrum. They don't have good mental models.
That's what we need to work on to get to the next level in AI: mental models that can be used for reasoning.
As we approach Christmas Eve 🎅, we're also celebrating a significant milestone. On December 22nd, 2023, the 78th session of the United Nations 🇺🇳 General Assembly marked a historic moment by unanimously declaring the Lunar New Year, a United Nations holiday.
This decision is a profound recognition of the cultural richness and significance of the Lunar New Year, a celebration deeply rooted in Chinese tradition and observed by millions around the world. As the UN 🇺🇳 Resident Coordinator in China 🇨🇳, I am heartened to see such an important aspect of Chinese culture being honored on the global stage.
The declaration of the Lunar New Year as a UN holiday is more than just an acknowledgment of a cultural event; it is a celebration of diversity, unity, and the shared human values that the festival embodies – renewal, family, and the coming together of communities.
As we revel in the festive spirit, let us cherish this moment of global recognition and the opportunity it brings to foster greater understanding, solidarity and appreciation of the diverse cultures that enrich our world.
Wishing everyone a happy, peaceful and healthy holiday season🏮🌏🎉