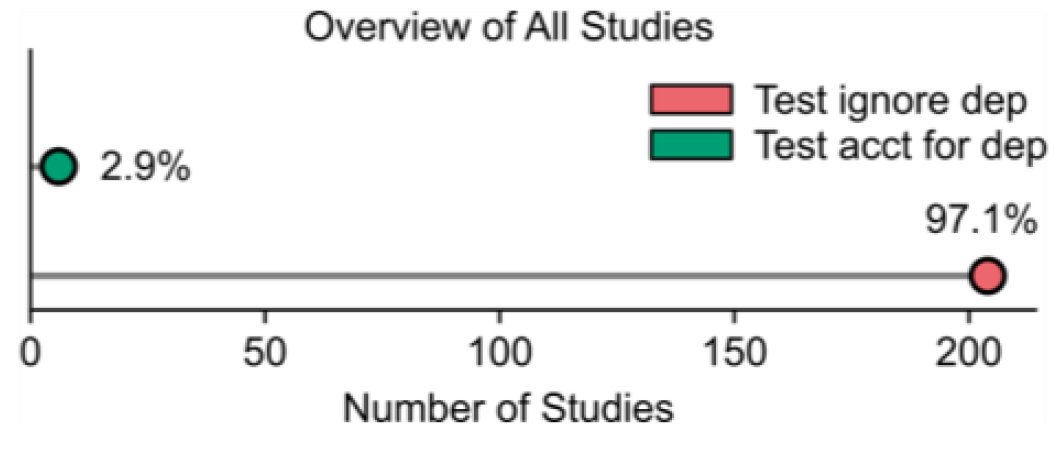
For years, we've known that running a standard t-test on cross-validation folds violates sample independence. We wanted to see how widespread this issue actually is.
The result? 97% of the studies used an invalid statistical test. 🧵👇
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint https://t.co/OG58Vkeu49 led by @tianchuzeng@kkli20111@ZShaoshi@ten_photos 1/N
The p-tau217 breakthrough blood test replicated again, predicting Alzheimer's disease in a large cohort mean age 61. The cover of the new issue is telling @TheLancet https://t.co/Qre6mCkpMV
This looks like a straightforward, highly applicable solution to the long-standing problem of valid inference for K-fold CV performance differences. The trade-off is smaller training sets from the split-half step and having to rerun K-fold CV many times.
New paper in Imaging Neuroscience by Ru Kong, B.T. Thomas Yeo, et al:
Network-based near-scalp personalized brain stimulation targets
https://t.co/86oCkw42cf
Here's bonus slides on cross-validation tests, separate from our preprint. Covering:
1. paired (sign-flip) permutation test
2. label-swap permutation test
3. sample-level vs fold-averaged stats
4. a common misapplication of the corrected t-test
5. three bootstrap variants 1/N
Biomedical AI may be headed for a replication crisis.
(This work below is not about AI-generated reports; it’s about studies of biomedicine that use ML in their methods, and how they are evaluted.)
Proud to participate in this study! We should keep rigorous in AI-Biomedical research, we also observe some concerning trends in AI+biomarker studies…
Congratulations @tianchuzeng Tian Fang and @ZShaoshi
Once again, @ten_photos came to the rescue - we prayed to him for a better statistical test for k-shot learning (since the corrected t-test is overly conservative in that scenario), and he answered our prayers with a new test that also covers classical cross-validation.
@bttyeo@tianchuzeng@kkli20111@ZShaoshi@ten_photos Can't stress this enough 👇 If you use ML to compare predictive models in your research (neuroscience, genetics, you name it), this paper is a must read! 👀
The majority of work in this space (mine included 🙋) misses critical nuances when reporting comparative stats.
My quibble: This is traditional ML *not* AI in the generative sense it means now till eternity. But yeah this is a thing. Metric chasing brought this on. Reviewers reward higher metric values & not well cross-validated results. We've been told AuC<0.8 not worth submitting. 🙄
It’s incredible to see this study come to fruition! Shout out to the amazing @tianchuzeng and @kkli20111 who spearheaded this work and huge thank you to all other coauthors!
For years, we've known that running a standard t-test on cross-validation folds violates sample independence. We wanted to see how widespread this issue actually is.
The result? 97% of the studies used an invalid statistical test. 🧵👇
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint https://t.co/OG58Vkeu49 led by @tianchuzeng@kkli20111@ZShaoshi@ten_photos 1/N
Lesion network mapping (LNM) has been powerful in linking symptoms and brain functional circuits, but ongoing debates highlight that it is still hard to isolate symptom-specific effects. We came up with a new method, robust LNM (rLNM) — a unified framework combining null models and selective specificity to reveal reliable, symptom-specific networks from background structure. https://t.co/6WHpBRNuQn
@bttyeo@foxmdphd@ndosenbach@club_scan
Function & cytoarchitecture don't overlap ... they're orthogonal. Prefrontal cortex is tiled with chains of functional patches mostly known from face processing. Multi-modal parcellations are wrong ... & other insights hidden by group-averaging fMRI data: https://t.co/WEo2Cf9N26