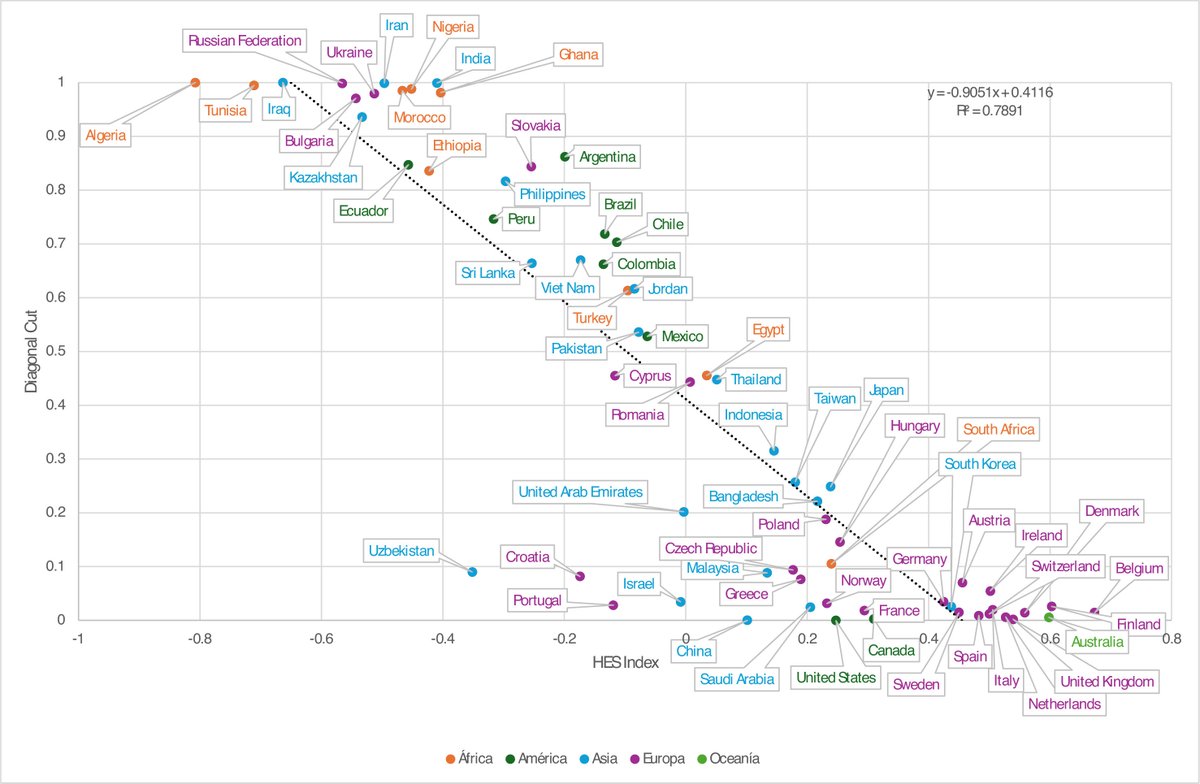
#HESIndex measures the performance of thousands of universities and defines national capacity Our analysis identified 4 models
Distributed excellence
Elite leaders with strong depth
Strong Middle-Performing Systems
Expansion lower performance concentration
https://t.co/duJ4QB4gFZ
The role of altmetrics in citation emergence: a temporal approach is our new preprint available on @socarxiv. Tracking the appearance of altmetric through the time, we have found that social media trigger the appearance of citations and shorten the time it takes for them to occur
Our research introduces the #HESIndex, a new metric that captures how institutional performance is distributed across national higher education systems, offering a broader view than traditional rankings. 👇https://t.co/ha0Q6ImIwz
A national Higher Education System should not be judged only by its flagship institutions.
The #HESIndex measures the distribution of performance across thousands of universities, providing
a more complete picture of national capacity.
➡️https://t.co/duJ4QB4gFZ
#EducationPolicy
#SCImagoIRIS | Identifying structural risk is the first step toward fostering a culture of integrity and transparency.
Scientometrics is not punitive; it is actionable intelligence to protect institutional reputation.
Explore our tool here ➡️https://t.co/RknpdsQbqI
#SCimagoResearch Open infrastructures are a landmark achievement for making science findable, but this is not the same as reliability. As open data scales, how do we balance volume and quality? Read more on our blog and access the full report👉https://t.co/0S15h1pdyN
Feliz de que la obra "Cibermetría: midiendo el espacio red", escrita junto a mi colega @isidroaguillo y parte de mi trabajo doctoral, esté finalmente disponible en abierto en O2 Repository UOC:
https://t.co/vHSKow27GE
How inclusive are open research infrastructures in practice?
Our study shows that OpenAlex indexes only 37% of China's core journals and 24% of their articles, revealing important metadata gaps that may affect the global visibility of Chinese research.
https://t.co/dylMaBeeOt
Y si una persona es capaz de conseguir los mismos méritos sin estancia que otra con ella, no veo motivo para puntuarla menos. Es tan sencillo como valorar los resultados, no los medios para conseguirlos, y de paso nos quitamos la discriminación. (2/2)
https://t.co/cJx7qz218r generates summaries of studies posted on Arxiv to facilitate their understanding for a wide range of users. For example, https://t.co/tSiv6kktP7 includes an explanation of https://t.co/oM1NtGJ0F9
Results are really good...
📊#ChartOfTheWeek | Four distinct models of HES Performance.
Our analysis of national performance curves revealed 4 distinct models of HES development, each reflecting a different balance between excellence concentration and system-wide performance. 👉 https://t.co/duJ4QB3IQr
How do we measure the performance of an entire HES—not just top universities? Our research introduces #HESIndex, a metric capturing how performance is distributed across national systems, offering a broader view than traditional rankings 👉 https://t.co/duJ4QB3IQr
Більшість рейтингів університетів переймаються Гарвардами та Оксфордами, але майже нічого не говорять про стан університетської системи загалом. Нова стаття пропонує оцінювати не окремі університети, а цілі національні системи. Знайдіть Україну? 😉 https://t.co/ptV1vusGdf
I’ve officially resigned as Associate Editor for Frontiers in Systems Neuroscience (part of @FrontNeurosci). It used to be a reputable journal, but became a case study in how forced automation destroys academic integrity. 👇
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.
Who is the greatest scientist of all time (in terms of Google Scholar citations)? Is it Einstein? Or Bengio or Hinton?
No.
It is a humble servant of knowledge, Mr. Rachmad of Indonesia, who has had a rather productive publishing period after the launch of ChatGPT
Buenos días :) Traigo una crónica que quizá os pueda resultar útil: "S.O.S. Me han hackeado el perfil de Google Scholar. Qué hacer y cómo afrontarlo" https://t.co/ejKYWbzd5e