@karpathy Mostly agree, except I’ve totally had Claude code suggest to add ignore comments to mypy errors after tying to fix it. So I think it does get stuck and give up. The difference is you can just say “don’t reference my other chats” and it will try again.
@sedielem I put normalizing flow, but seeing flow-based in an abstract has changed over the years what I expect the paper to be about. Early in my career I would expect Real NVP, but now I would expect flow matching.
I find deep research from @OpenAI super useful. However, I would like to see improvement in the output format. I always want it to be in markdown but it leaves out information when asked to convert it to markdown. If anyone has luck with getting the full output in a markdown file, I would appreciate any tips.
Its going viral on Reddit.
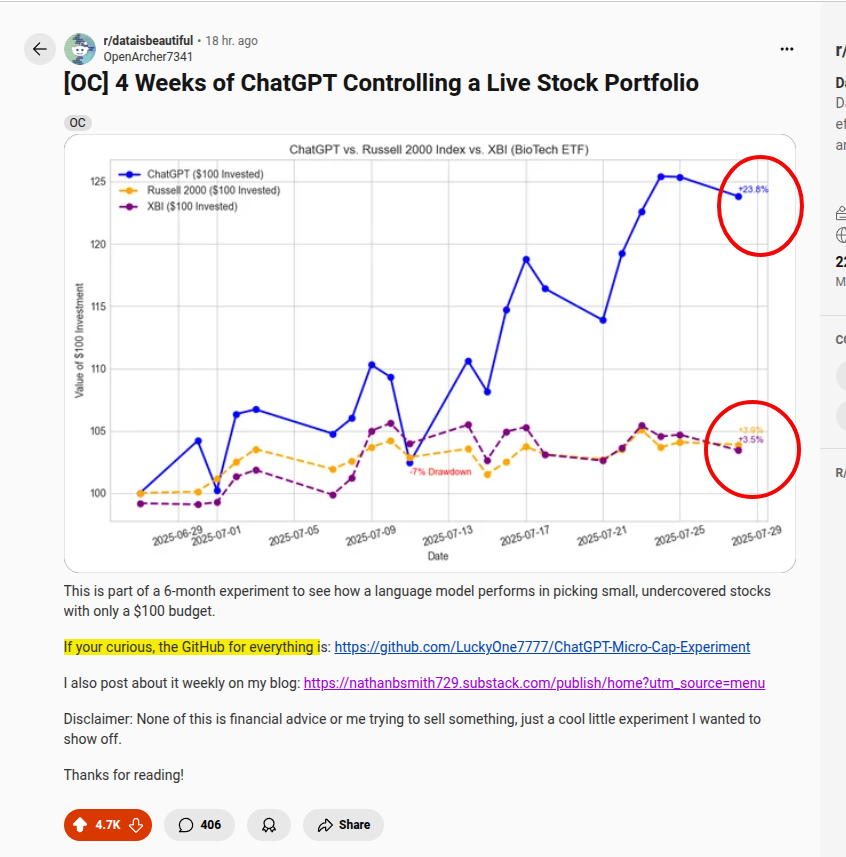
Somebody let ChatGPT run a $100 live share portfolio, restricted to U.S. micro-cap stocks.
Did an LLM really bit the market?.
- 4 weeks +23.8%
while the Russell 2000 and biotech ETF XBI rose only ~3.9% and 3.5%.
Prompt + GitHub posted
---
ofcourse its a short‑term outperformance, tiny sample size, and also micro caps are hightly volatile.
So much more exahustive analysis is needed with lots or more info (like Sharpe ratios and longer back-testing etc), to explore whether an LLM can truly beat the market.
@JeremiahDJohns It’s interesting that some of these came from sources already on the internet that are obviously trolls/satire. That actually might be fixable if you could rank existing answers based on truthfulness.
GPT-3’s score on the MMLU benchmark was 40%. First release of GPT-4 scored 86%, and today GPT-4o is 89%.
An increase of just 3% — that’s a full year of progress. If you plot the prior trend we were supposed to be at 100, maybe 120% by now. AI is hitting a wall.
Hot take: ML researchers are underestimating how quickly recent scaling laws may flatten out - it’s quite likely what people see as an exponential function is a sigmoid, and the harsh reality of the physics of high energy costs and power plant construction restrict the expected benefits from pretraining of ever larger models.