AI safety can't happen behind closed doors! Super cool to see that the @AISecurityInst is releasing its evals, datasets, and models in the open on @huggingface, so researchers everywhere can scrutinize, reproduce, and build on them: https://t.co/pLaKgl0oH1
let us know if there's interest to pick a free course / tutorial on agents (build, deploy, eval) + work through it in 2-3 study group sessions -- these are some free resources that we found very interesting and useful https://t.co/KZBcChPJWp
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
Most people know Hugging Face from its public models and datasets but few realize that 50% of the models and datasets stored on HF are private.
This number has been increasing with buckets (our S3 alternative for AI) and enable companies to build AI more efficiently and collaboratively within their organizations, even when they don't share publicly!
Excited to see more of that in the coming months as more companies start building AI themselves instead of outsourcing to APIs!
Anthropic's self-reported run-rate revenue growth is wild - Axios @JimVandeHei said he could not find "any company — in any industry, in any era — that has scaled organic revenue this quickly at this level as Anthropic" when they were at $30B, and now they're at $47B! https://t.co/t38Cl7HTvC
SHIPPED. Mistral Vibe is now the AI agent for long-horizon productivity and coding, and the home for Work mode, Code mode, the CLI, and a brand new VS Code extension. Let's go... 🧵
Very exciting times for scientific discovery! Multi-agent orchestration + a knowledge graph that spans 40M+ abstracts, 550K+ clinical trials, 1.6M+ patents, 550M+ biomedical facts, and 100K+ drug-target and indication relationships, all unified into a single evidence substrate that workflows retrieve from and reason across at every step. https://t.co/xFxnHLTQap
The HF science team just made async RL weight sync ~100x cheaper on bandwidth, and you don't need a shared cluster anymore.
The problem: every RL step, the trainer typically has to sync fresh weights to the inference engine. for a 7B in bf16 that's ~14GB. for a frontier 1T fp8 checkpoint, that's ~1TB; in bf16 it would be ~2TB. per sync.
The insight: between two RL steps, ~99% of bf16 weights are bit-identical. at RL learning rates, the optimizer is whispering and bf16 literally cannot hear most of it. the stored bf16 bits don't change.
What they shipped in TRL: only the changed elements get encoded as a sparse safetensors file, dropped into a Hugging Face Bucket, and fetched by vLLM. on Qwen3-0.6B, per-step payload goes from 1.2 GB to 20 to 35 MB. This is exactly what we built Buckets for: S3-like object storage on the Hub, Xet-backed (so even full snapshots only transfer the changed chunks).
The cherry on top: we ran a FULL disaggregated training where:
- the trainer lived on one box
- vLLM ran inside a Hugging Face Space
- the Wordle environment ran in another Space
- weights flowed through one Hub bucket
no shared cluster. no RDMA. no VPN. no NCCL across clouds. just HTTPS and a bucket.
one GPU + a Hugging Face account is now enough to do real disaggregated RL. multi-replica inference fleets across regions become a small devops exercise, not a research project.
Full write-up: https://t.co/CG115IjT0q
Open source RL keeps eating the moat!
We've raised $65 billion in Series H funding at a $965 billion post-money valuation, led by @AltimeterCap, Dragoneer, @Greenoaks, and @sequoia.
This investment will help us advance our research and expand our capacity to meet growing demand for Claude.
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
very cool work
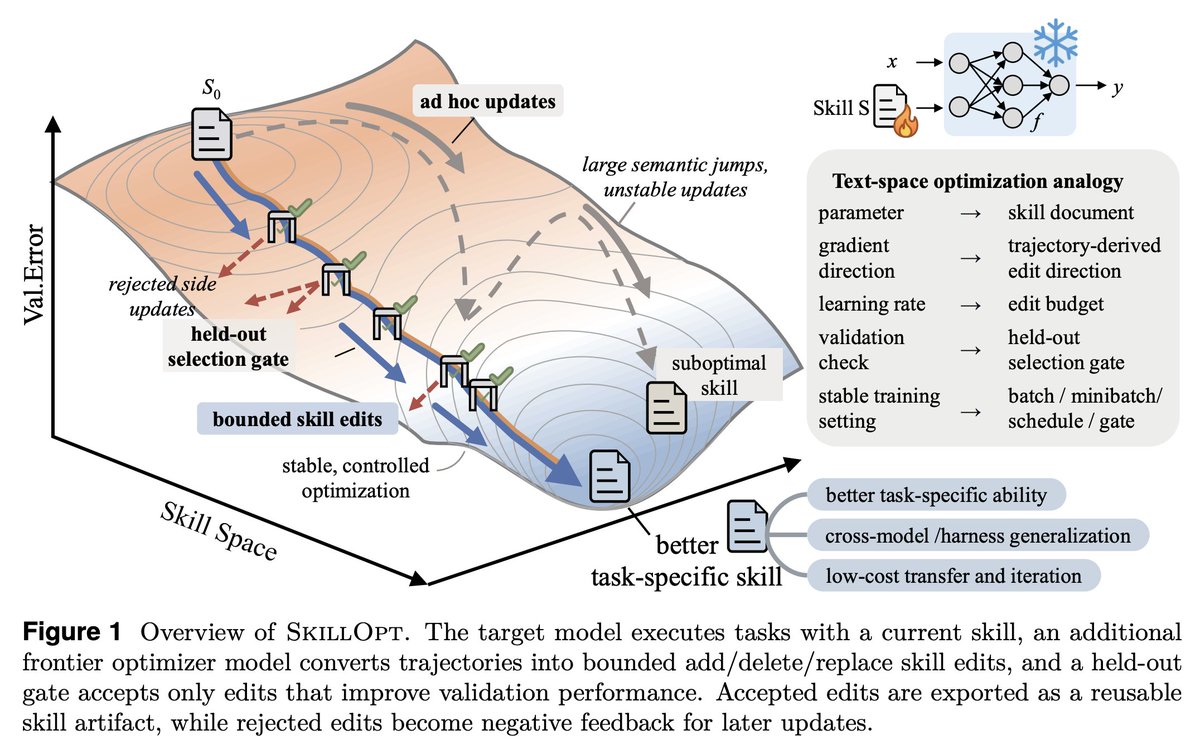
"the first systematic controllable text-space optimizer for agent skills: a separate optimizer model turns scored rollouts into bounded add/delete/replace edits on a single skill document, and an edit is accepted only when it strictly improves a held-out validation score." https://t.co/HYLUBkCy0o
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. Now, we got a technical report with some interesting tidbits. I summarized some of them below:
1. Full attention as an anti-trend?:
They tried hybrid sliding-window attention variants (like so many others, like Xiaomi MiMo, Laguna, Gemma 4, Arcee, Olmo 3, etc.). But even though there were efficiency gains, they said that the production-quality tradeoffs were not worth it for M2.
2. Linear and sparse attention deployment issues:
They found that linear and sparse attention are attractive on paper because they reduce the cost of long-context attention, but they are harder to make work well in a production agent system.
In particular, they found that these efficient attention variants may be more fragile when KV-like state or intermediate memory is stored in lower precision.
Also, they have worse prefix caching support, which matters a lot when using coding agents (which reuse a lot of the context).
3. Fine-grained Mixture-of-Experts (MoEs) are useful:
Finally a recent MoE ablation study! It's only on the 2B-active parameter scale, but hey, better than nothing.
Concretely, they compare a baseline with 32 experts and top-2 routing against a fine-grained setup with 128 experts and top-8 routing.
The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5. That's clearly a win for more fine-grained experts (confirming what the DeepSeek MoE paper reported ~2 years ago).
4. Sophisticated agent pipeline
It's probably no surprise, but this papers confirms that training for agent-like behavior on software engineering task is now a big component of the training pipeline.
They mine GitHub pull requests, builds runnable Docker environments, extracts task-specific test rewards, etc.
5. Interleaved thinking for context management
Interestingly, they found that removing reasoning blocks from previous turns results in worse performance, especially in multi-step agent tasks. (Another point why long-context support is so important these days).
6. Speed rewards
It's common to have token usage penalties, but what's interesting is that the MiniMax team adds a task-completion-time reward that depends on wall-clock time. This is to minimize unnecessary (slow) tool calls. Also, I'm thinking that this would encourage agent parallelization (if supported by the harness)
7. Self-evolution
Looks like self-evolution is also already a big design component of open-weight LLMs. E.g., the paper says that M2.7 already handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.
We’ve shipped a security-guidance plugin for Claude Code that helps identify and fix vulnerabilities as you’re writing code.
Available for all Claude Code users. Install from the plugin marketplace (/plugins).
New on the Engineering Blog: The access and permissions we grant agents should evolve with their capabilities. In our own products, we set these parameters through sandboxing, which limits the scope of any potentially destructive actions.
Read more: https://t.co/KfBKW8O9kP
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.