#Llama3#Llama3Ko#Llama3OpenKo
I’ve just uploaded the first version of the Llama-3-Ko series, the Llama-3-Open-Ko-8B model, to Hugging Face! You can check it out here: https://t.co/01r6TRVKAP.
Why aren’t Diffusion Language Model smart yet? Lacking stable post training is a major bottleneck!
Meet DiPOD: the tripod for diffusion model post-training.
DiPOD boosts accuracy across reasoning tasks, with Sudoku jumping from 22% to 97%, through a one-line code change.
🧵1/5
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
Solid 1M Context: A solid 1M-token context that stably sustains long-horizon work
Advanced Coding with Flexible Effort: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
Improved Architecture: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
Pure Open: An MIT open-source license — no regional limits, technical access without borders
Supporting long-horizon tasks starts with making long context engineering-usable: the model must maintain quality across long, messy coding-agent trajectories, not just accept more tokens. A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure. To this end, we substantially expanded 1M-context training for coding-agent scenarios, covering large-scale implementation, automated research, performance optimization, and complex debugging. The result is a long-context system that is not only wide in scope, but solid in execution: a practical substrate for sustained engineering work.
This capability is reflected in GLM-5.2's performance on three long-horizon coding benchmarks. FrontierSWE measures whether an agent can complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. On this benchmark, GLM-5.2 trails Opus 4.8 by only 1%, while edging out GPT-5.5 by 1% and Opus 4.7 by 11%. On PostTrainBench, where each agent is given an H100 GPU and evaluated by how much it can improve small models through post-training, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8. On SWE-Marathon, an ultra-long-horizon software engineering benchmark covering tasks such as building compilers, optimizing kernels, and developing production-grade services, GLM-5.2 still has room to grow, trailing Opus 4.8 by 13% while remaining second only to the Opus series. Across all three benchmarks, GLM-5.2 is the highest-ranked open-source model, showing that its 1M context has translated into practical long-horizon delivery capability.
Introducing GLM-5.2: Frontier Intelligence, Open Weights
- Significant improvements in coding and agentic tasks
- Strong long-horizon capabilities with a 1M context window
- Two levels of reasoning effort: GLM-5.2 (max) pushes the limits, while GLM-5.2 (high) strikes a strong balance between performance and token efficiency
- MIT-licensed open weights
- Same API pricing as GLM-5.1
Tech Blog: https://t.co/LAsxUdN0JZ
Weights: https://t.co/g0A1C4UWx4
API: https://t.co/Kc3E22cbN7
Coding Plan: https://t.co/Nk8Y98HNhU
Chat: https://t.co/WCqWT0qCQb
Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: https://t.co/7hixC7FNg7
Paper:https://t.co/t1nHSJgGwB
Quite interesting thread on capabilities of real biological neurons (spoiler: they're way more capable than classical artificial neurons in a perceptron) . Nice work @IdoAizenbud and collaborators!
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
https://t.co/g4Ybfa2kWH
MiniMax Sparse Attention:
https://t.co/HcTlWRotG3
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
this is fascinating, they train an encoder/decoder but use LLM matching the target model's shape for each part, so the latent space is just plain language and they can detect reward hacking, unwanted behavior and more
could even see it being used as an eval to quantify how smart a model is, i love this
When people ask me what reward hacking in RL is
> here’s the simplest example I personally saw and share to explain it in 1 min:
Last year, when GRPO first came out and TRL had an implemented it, people were fine-tuning very small model such as Qwen 0.5B/llama 1b,3b on the GSM8K dataset to make these models better at solving math problems.
I took a slightly different approach. Instead of asking the LLM directly to solve math problems, I asked it to generate Python code to solve them and print the outputs.
I was experimenting with different rewards and in one of the run I gave the usual format and correctness rewards, but also added a code execution reward, giving it a between 0 to 2 reward if the code executed without errors and few other conditions
I was training on Qwen 0.5B, and things were doing okay. The format reward improved, and correctness was on and off. But suddenly, at some point, the code execution reward shot up and stayed high.
When I looked at the traces, I saw that it had started adding try-except blocks so the code would execute without throwing errors.
This is a simple example of reward hacking: the model learned to maximize the reward without actually solving the task correctly.
ps: this experiment was a year ago, and have mentioned to couple of folks offline as well, there is a lot more to reward hacking than this and this example is over simplification but easy to understand and relate to hope it helps
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️
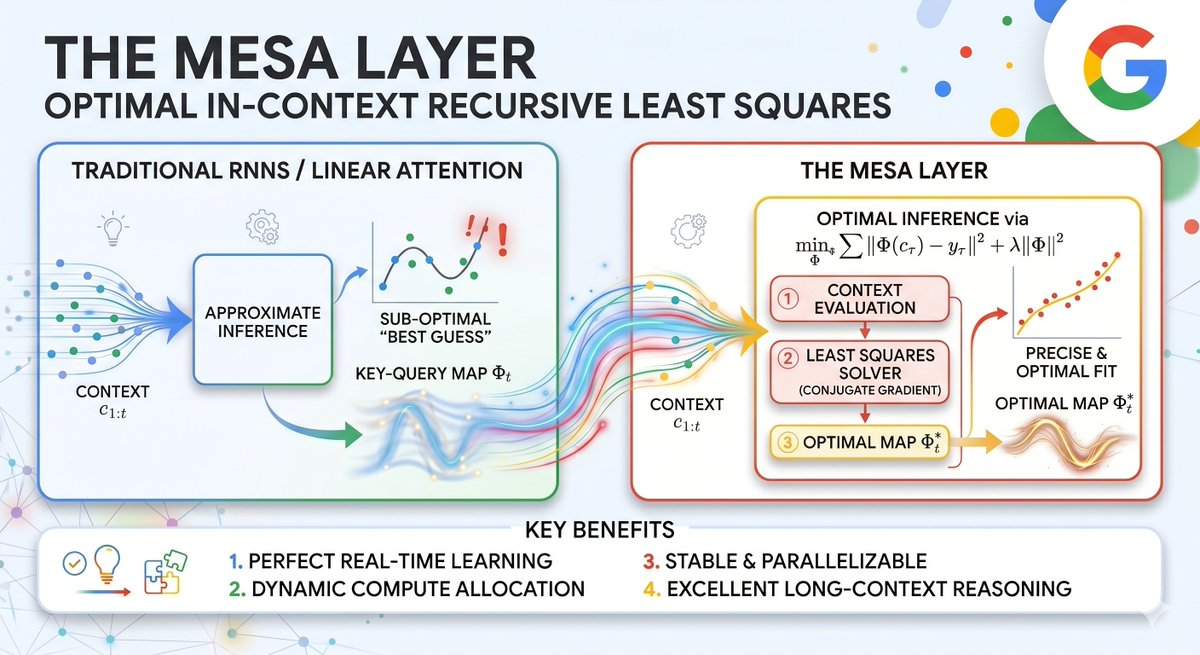
Google presents a new Transformer alternative at #ICLR2026! Join Nino Scherrer & Yanick Schimpf at the Google booth (#411) at 10AM to learn about MesaNet, proposing a new linear sequence layer that optimally learns in-context given a fixed memory budget.
Introducing Decoupled DiLoCo, a breakthrough in large scale distributed training
Low bandwidth way of training globally in a distributed setup. DiLoCo and follow-up works can be quite game changing in the industry and I'm very excited to see how they evolve
It's been a delight to provide small amounts of advice and suggestions to people working on the Decoupled DiLoCo training system. This approach enables graceful handling of failures in large scale training jobs, by allowing (N-1) / N units to proceed when one fails.
Thread ⬇️
Self-play led to superhuman Go performance, why hasn’t it for LLMs?
In practice, long run self-play plateaus like RL. We study why this happens, and build a self-play algorithm that scales better. It solves as many problems with a 7B model as the pass@4 of a model 100x bigger.
GPT-5.5 is here.
It’s our smartest frontier model yet, introducing a new class of intelligence for agentic coding, computer use, knowledge work, and scientific research.
Rolling out in ChatGPT and Codex today. API is coming soon.
We're open-sourcing FlashKDA — our high-performance CUTLASS-based implementation of Kimi Delta Attention kernels. Achieves 1.72×–2.22× prefill speedup over the flash-linear-attention baseline on H20, and works as a drop-in backend for flash-linear-attention.
Explore on github: https://t.co/sf4UohXDWY