Is pixel prediction the best way to build a world model?
Check out VDAWorld, an alternative path to building interpretable, editable, and physically grounded world models.
We use a VLM to build a simulation of the scene with the help of a computer vision toolbox.
Do 3D reconstruction transformers really need a billion parameters, or are most of those layers just doing the same thing over and over?
Introducing Déjà View: a single transformer block, looped K times, that matches or beats models 8–10× its size with lower compute. 🧵
Check out 3D-Belief: a 3D world model that explores how explicit belief representations can support memory, imagination, and planning under partial observability.
What should a world model capture for embodied agents?
An agent acting under partial observability needs a belief over the 3D world: what it has seen, what may exist beyond view, and how that belief should update as it moves.
Introducing 3D-Belief, a 3D world model for embodied belief inference under partial observability. 🧵[1/9]
Nice work! World models meet active sensing and closed-loop planning.
We'll be showcasing this demo at the Lambda booth @chuanli11 during CVPR main conference at Denver. If you're attending, stop by and check it out! #cvpr@CVPR
We are also hosting a world-model-related workshop at CVPR : https://t.co/k7uKAyzybO
Submit to #SIGGRAPHAsia2026 Workshops!
Bring researchers, students, designers, artists, developers and creators together for lively exchange & discussion.
📅 Challenge-Included: 15 June 2026
📅 Discussion-Focused: 31 July 2026
Submit:https://t.co/IgJGad7J0O
#WeavingTheFuture
I’m looking for a PhD student with UK home fee status to join my lab at Cambridge starting this October. If you’re interested and have research experience in multimodal spatial modeling or vision-based robot learning, email me your CV. Funding deadline is approaching very soon.
Is pixel prediction the best way to build a world model?
Check out VDAWorld, an alternative path to building interpretable, editable, and physically grounded world models.
We use a VLM to build a simulation of the scene with the help of a computer vision toolbox.
In addition to physical plausibility, the use of a python simulator makes it easy for users to modify the simulation! Check out the project page for many more examples.
New opening for an Assistant/Associate Professor in Robotics at the Cambridge Engineering Department @Cambridge_Eng.
Apply by 8 February 2026:
https://t.co/e7SkDYGU14
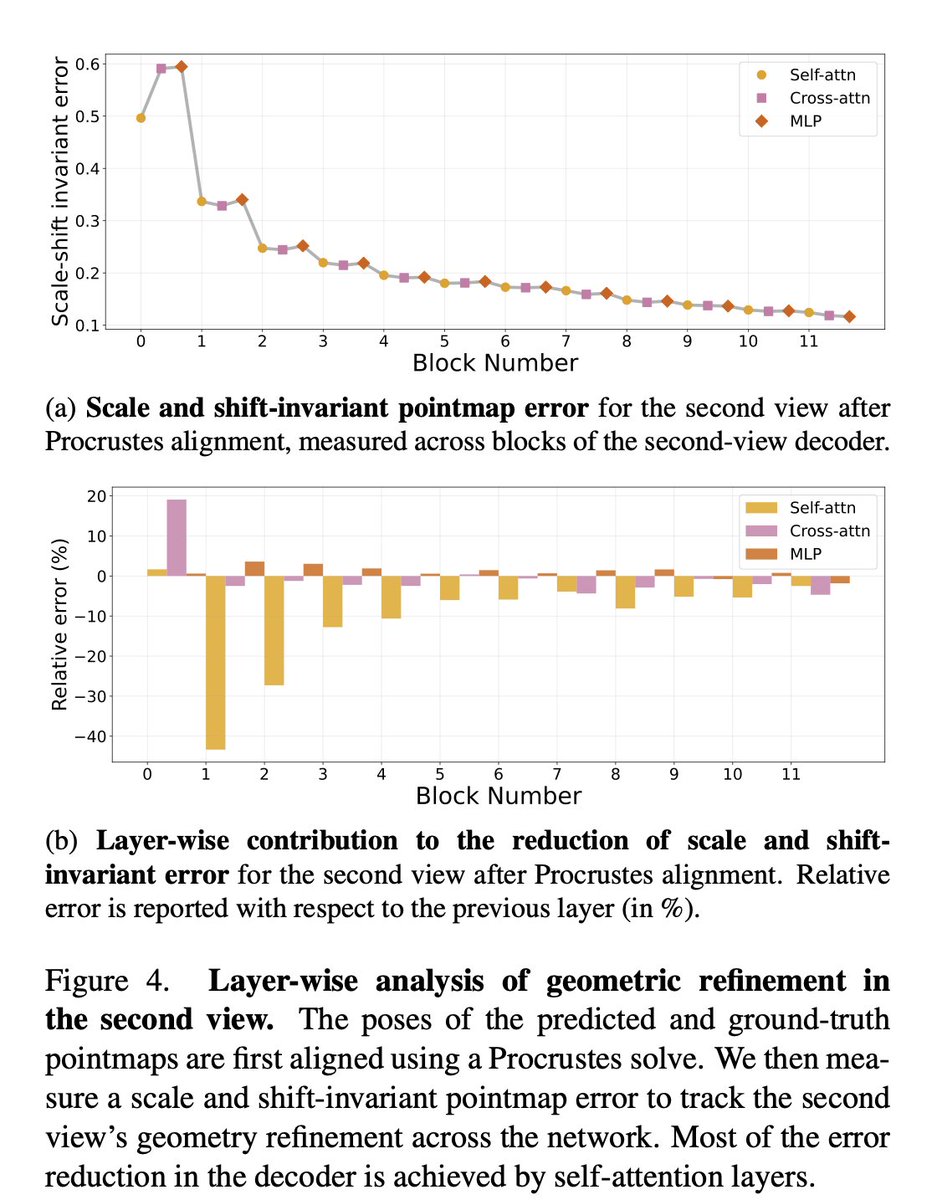
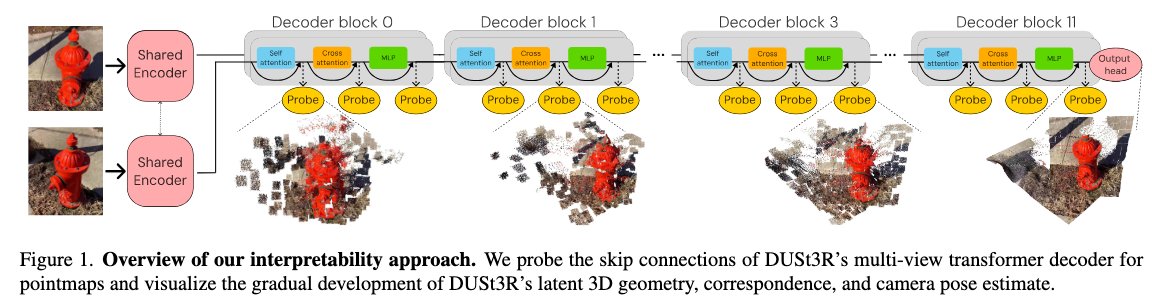
Makes sense. Matching and 3D reconstruction are inherently iterative computations; this nice paper gives hints on how DUSt3R's transformer achieves that. Now we can get on with figuring out how to do it tens or hundreds of times better/faster with a more specific architecture.
Stary and Gaubil et al., "Understanding multi-view transformers"
We use Dust3r as a black box. This work looks under the hood at what is going on. The internal representations seem to "iteratively" refine towards the final answer. Quite similar to what goes on in point cloud net
DUSt3R et al. are impressive, but how do they actually work?
We explored this, and share insights on iterative reconstruction, the roles of cross- and self-attention, and emerging correspondences across the network [1/8] ⬇️
Understanding Multi-View Transformers
Michal Stary @jgaubil@_atewari@vincesitzmann
tl;dr: DUSt3R self-attention is it secretly a diffusion model, and cross-attention is matching.
https://t.co/UR9agpjD8M
In Fall 2026, I will begin a tenure-track faculty position @JHUCompSci
Announcing the SciPhy lab, where we will study the science of physical agents (robots)
We are now recruiting our first cohort of PhD students. If this is you, see
https://t.co/heSKsCbWz7























![jgaubil's tweet photo. DUSt3R et al. are impressive, but how do they actually work?
We explored this, and share insights on iterative reconstruction, the roles of cross- and self-attention, and emerging correspondences across the network [1/8] ⬇️ https://t.co/rDlYNeQev5](https://pbs.twimg.com/media/G4780_FWMAAa8yO.jpg)