Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
Livermore
@_eustace65
Investor
Sydney
Joined November 2021
7.5K
Following
164
Followers
167
Posts
_eustace65
retweeted
fin
@fi56622380
about 2 months ago
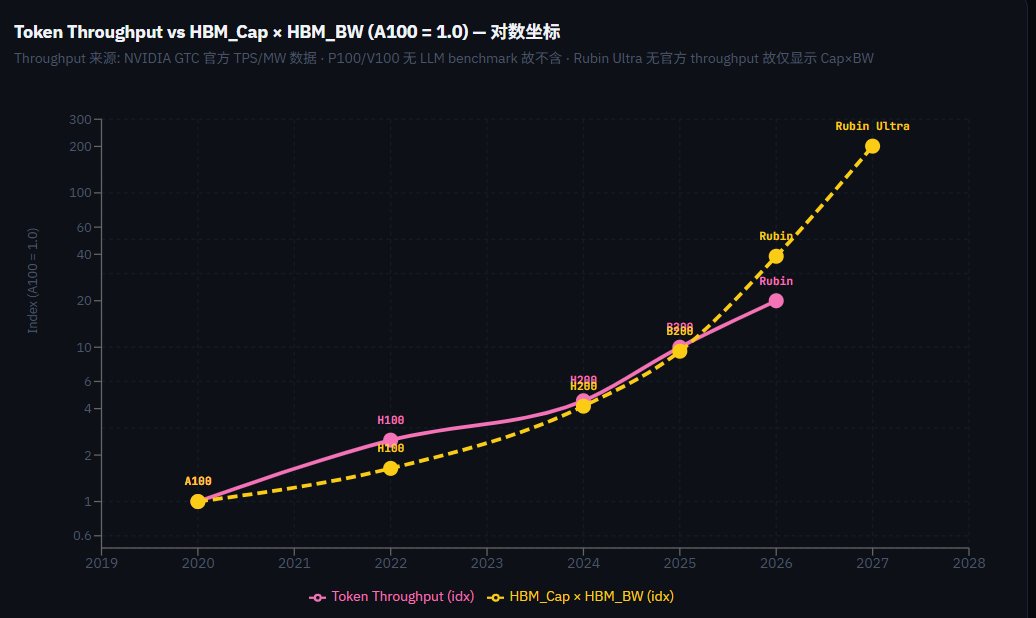
AI半导体终局推演2026(I) 当新token经济学范式从GPU算力转移到HBM 本文从从GPU架构进化路线本质出发,解释这个市场长久以来担心的问题: 每个GPU的HBM内存需求为什么一定会是指数增长,为什么HBM需求指数增长不会停滞? 并推导token经济学在当前架构下��一性原理:token吞吐 = HBM size X HBM BW带宽 同时讨论了,为什么GPU的天花板被HBM的两个发展维度所决定 HBM周期性这个话题争议一直很大,乐观派认为AI带来的需求比以前要大的多,但市场主流仍然认为前几次上升周期也有需求每年20%+增长,这次又有什么不一样呢?AI不影响HBM和传统DRAM一样有commodity属性,一旦在需求顶峰扩产遇上需求下行又会重蹈覆辙。 我们可以从算力芯片架构视角,从第一性原理出发,来拆解和推演一下这个问题:为什么这次真的不一样 ------------------------------- 历史:CPU算力时代 很久以来,我们都处在CPU主导算力的时代,CPU的最高级KPI就是performance,跑的更快,所以每一代的CPU都用各种方法来提高跑分,最开始是频率上升,后来是架构演进superscaler等等 这个时候为什么DDR不需要很快的技术进步速度?比如DDR3到DDR5竟然经历了15年之久 因为这个时期的DDR的角色是纯粹的辅助,而且辅助功能极弱,以业界经验,DDR的速度即便是提高一倍,CPU的performance一般只能提高不到20%这个量级 为什么DDR带宽速度提高了用处不大?两个原因 1. CPU设计了各种架构去隐藏 DDR延迟,比如superscaler,加大发射宽度,用海量的ROB和register renaming来提高并行度隐藏延迟,一级缓存cache,二级缓存cache,削弱了DDR的带宽速度需求 2. CPU workload对DDR带宽要求并不高,大部分日常负载比如打开网页,DDR带宽是严重过剩的,甚至云端负载 也就是说,在CPU时代,DDR的带宽速度是不太有所谓的,DDR4和DDR5除了少数游戏就没啥差别,甚至JEDEC标准也进步缓慢。 另外,绝大部分app需要一直停留在DDR上的部分并不多,需要的时候从硬盘上调度到DDR即可,app的size增长没那么快,导致对DDR的容量需求也较为缓慢。 所以最近十年来,平均每台电脑上的DDR容量大概从7~8GB变成了23GB,十年只增长了3倍。 而这部分升级缓慢直接影响了营收,size容量计价是赚钱的主要方式,速度的提高只是技术升级,提高size的单价,这两个的升级需求都不大,需求主要是随着电脑/手机数量增长而增长 所以DRAM在带宽速度和容量这两个维度上,一直是都是芯片产业锦上添花性质的附属品,DDR升级带来的边际效用是很低的,跟CPU时代的最高KPI几乎没什么直接联系 -------------------------------------------- 而到了genAI 大模型为主导的新时代,计算范式转移让最高级KPI起了根本变化 GPU发展到AI推理的时代,不再像CPU那样只看跑分,最高级的KPI不再是算力TOPS/FLOPS,而是token的成本,特别是单位成本/单位电力下的overall token throuput 其次是token吞吐速度,因为在agent时代,很多任务变成了串行,token吞吐速度成了用户体验的重要瓶颈。 这也是为什么老黄发明AI工厂概念的原因:最低成本的输出最多token,同时尽量提高token吞吐速度 AI训练时代,老黄的经济学是TCO(total cost ownership),买的GPU越多,省的越多 而老黄在推理时代的token经济学是: AI推理的毛利润很可观,所以逻辑已经转换成:Nvidia GPU是这个世界上让token单价最便宜的GPU,买的GPU越多,赚的越多 最高的KPI变成了Pareto frontier曲线,在提高token 吞吐throughput和提高token速度两个维度上尽量优化 (见图一) NVIDIA 的 token factory 代际进步,其实是在把整条 Pareto frontier 往右上推,这就是是AI推理这个时代最重要的KPI ---------------------------------- 接下来是本文最重要的逻辑链,如何从token吞吐量指数型增长的本质出发,推导出天花板瓶颈在HBM size和HBM 带宽的指数型增长 单卡GPU推理单线程batch size = 1的时代,token吞吐只有一个维度,就是HBM的带宽速度,带宽速度越高,token吞吐越大 但进入NVL72的年代,推理不再是单卡GPU时代,而是72个GPU + 36个CPU整个系统级别的token工厂,把HBM带宽和算力用满,获得极致的token吞吐量 Token 吞吐throughput的增长,依赖两个东西:同时批处理的请求数 X 每个user请求的平均token速度 也就是batch size X per user token 速度 以Rubin NVL72为例,在平均token速度是100 token/s的情况下,同时批处理1920个请求,得到token吞吐量是19.2万token/s 一个Rubin NVL72大概是120KW(0.12MW)的功率,所以得���单位MW能处理1.6M token/s (见图一) 所以,我们需要想方设法提高这两个参数:批处理数量batch size和per user token的平均速度,这两者相乘就是我们的最高KPI,也就是token的吞吐量 ------- 第一个参数:batch size的增长,瓶颈在HBM size 批处理量里的每一个请求req,都会自带kv cache,这部分kv cache是需要存在HBM里的,大小大概在几个GB到数十GB不等 因为hot kv cache是随时需要高频高速读取,所以必须放在HBM里,比如一个大模型的层数是80层,那么每一个token的生成阶段,都需要读取80次HBM里的kv cache 随着批处理数量batch size的增长,会带来hot kv cache的线性增长 又因为这个批处理量的所有请求的hot kv cache,都要放在HBM上,这也就带来了HBM size必须要随着批处理量batch size线性增长 就像是机场接驳车,登机口尽量快的接旅客到飞机,HBM size小了,相当于接驳车size小了,就得多接一趟 结论是:批处理量的数量batch size,瓶颈依赖于HBM size的增长 --------- 第二个参数:每个user请求的平均token速度,瓶颈在HBM带宽 大模���decode阶段的速度,瓶颈取决于HBM的带宽速度,因为每生成一个 token,都要把激活的权重和kv cache 读很多遍 LPU的出现,在batch不那么大的情况下,把激活权重这个部分搬到了SRAM上,但是每生成一个 token仍然要从HBM读很多次KV cache。HBM带宽越高,生成每一个token的速度也就越快,基本上是线性对应的 就像是机场接驳车,登机口尽量快的接旅客到飞机,hbm本身带宽速度就像是接驳车的车门有多宽,门越宽,旅客上接驳车越快 GPU的其他配置,都是在适配batch的增长以及要让token compute的速度配平HBM的增长,甚至会用多余的算力来获得部分的带宽(比如部分带宽压缩技术) —----- 在那个接驳车的比喻例子里 接驳车的车厢大小 = HBM Size(容量): 决定了一次能装下多少名旅客(也就是能同时装下多少个请求的 KV Cache)。车厢越大,一次能拉载的旅客(Batch Size)就越多。如果车太小,想拉100个人就得分两趟,系统整体的吞吐量就上不去。 接驳车的车门宽度 = HBM Bandwidth(带宽): 决定了旅客上下车的速度。门越宽,大家呼啦啦一下全上去了(Decode/生成Token的速度极快)。如果门很窄,哪怕车厢巨大能装200人,大家也得排着队一个一个挤上去,全耗在上下车的时间里了。 旅客的吞吐量 = 接驳车车厢容量 x 接驳车旅客上车速度(车门宽度) —--------------------------- 至此,我们从逻辑上推演出了token经济学的硬件需求第一性原理: Token throughput = HBM size X HBM Bandwidth AI推理这个时代的最高KPI,实际上是高度依赖于HBM的两个维度的进步的 如果要维持token throuput每一代两倍的增长,实际上意味着,每一代的单GPU上,HBM size X HBM BW带宽之积要增长两倍! 这也是历史上第一次,HBM内存的size可以影响最高的KPI token throughput! 要验证这个理论,可以把Nvidia从A100到Rubin Ultra这几代的token 吞吐throughput,和HBM size X HBM BW 放在同一个图里比较 (见图二) 可以发现,这两个曲线的走势在对数轴上惊人的一致 HBM size x HBM带宽增长的甚至要比token吞吐量更快,毕竟HBM决定的是天花板,实际上这个天花板增长的利用率utilization是很难达到100%的,也就是说,HBM size x HBM 带宽就算增长1000倍,其他算力和架构的配合下,很难把这1000倍的天花板潜力全部榨干 这条曲线不是巧合,而是系统最优化的必然解 throughput = batch × Bandwidth,这就是token factory 经济学最绕不开的第一性原理 —-------- 软件的影响呢?软件的优化会不会降低带宽的需求?降低HBM的需求? 这跟硬件是独立两个维度的,这好像在问,如果CPU上的软件优化了之后跑的更快,是不是CPU就十年不用发展了?反正软件跑的更快了嘛 这样的话,CPU厂还能赚得到钱吗?CPU想要存活下去,只有一条路可走,在标准benchmark,不考虑软件优化,每一代CPU必须要跑分更高,不然就卖不出去 GPU也是一样,软件优化如何,和自己的token吞吐量KPI每年都要大幅进步,是两回事 只要token的需求继续增长,对token throuput的追求就绝不会停止,那么对HBM size X HBM 带宽的追求也不会停止 如果HBM size和HBM 带宽发展慢了,老黄一定会亲自到御三家逼着他们技术升级,因为这就是老黄gpu的天花板,天花板要是钉死了不进步,老黄的GPU还能卖出去吗? 当然了,Nvidia需要绞尽脑汁去从异构计算的架构角度榨取HBM天花板之外的部分,比如LPU就是一个很好的尝试,把Pareto frontier从另一个角度改善了很多 (右半边高token速度的部分) —-------------------------------------- HBM内存已然告别了那个随波逐流的旧时代,在这条由指数级需求铺就的单行道上,以一种近乎宿命的方式走到了产业史诗的主舞台中央 推理范式第一性原理演化到这一步,只要老黄还要卖GPU,HBM就必须翻倍,而且必须代代翻倍。这是supply side的内生压力,与AI需求无关,与宏观周期无关,与hyperscaler的心情也无关 剩下的问题,只有一个: 当需求被物理锁定为指数增长的时候,供给侧的三个玩家,会不会还像过去三十年那样,亲手把自己再拖回一次周期的泥潭?
See More
Livermore
@_eustace65
5 months ago
@Rumoreconomy
怎么老是能刷到你个谣棍
Livermore
@_eustace65
5 months ago
@wufantouzi
柚子厨
Livermore
@_eustace65
6 months ago
@Polymarket
@grok
fact check
Who to follow
MIKOK
@MIKOkig
杂鱼
Show Yunhe
@Vanessa18237665
Let's visit colorful China!
よみですよ〜ん
@y0m1_y
💕@__nyon72⭐️@uxoex_ @yu_nono03
Livermore
@_eustace65
8 months ago
@horizon_tem 比特币比特币比特币比特币比特币比特币比特币比特币比特币
Livermore
@_eustace65
about 1 year ago
@Supercali2023 劳动并不光荣,因为劳动的目的是生存,如果不是为了生存可以不劳动,劳动的终极目的就是不劳动,人人都想不劳动。 劳动是被迫的,不是主动的,不存在光不光荣的问题,只有鼓吹人民劳动,有些人才可以不劳动。 一切的劳动在资本面前,都是没有意义的,就像你无论怎么努力,在房价面前都是徒劳的
Livermore
@_eustace65
about 1 year ago
@daimajia
人生的智慧,穷查理宝典
Livermore
@_eustace65
about 1 year ago
@alifarhat79
@grok
which movie is this video from?
Livermore
@_eustace65
about 1 year ago
@PandaTalk8
穷��理宝典
Livermore
@_eustace65
about 1 year ago
@FurinaDF
救盘 放鸽 美债 川普 主要
Livermore
@_eustace65
about 1 year ago
@rickawsb
@grok
分析
_eustace65
retweeted
逍遥XTony(恩师张雪峰)
@xtony1314
about 1 year ago
行业两大现象: 打工者容易把公司的实力当成自己的实力, 交易者容易把时代的红利当成自己的实力。
Livermore
@_eustace65
about 1 year ago
@TradingThomas3
@grok
true?
Livermore
@_eustace65
about 1 year ago
@joecarlsonshow
SQQQ
Livermore
@_eustace65
about 1 year ago
@tj_research
逃总怎么看中国反制关税
Livermore
@_eustace65
about 1 year ago
@grok
@mranti
detailed analysis
Livermore
@_eustace65
over 1 year ago
@skaas777
@didengshengwu
我开上路虎了
Livermore
@_eustace65
over 1 year ago
@bboczeng
@grok
评论一下
Livermore
@_eustace65
over 1 year ago
@maitian99
@tj_research
急了😄
Last Seen Users on Sotwe
Czu
Seen from
Japan
Pamela Alexandra
Seen from
Mexico
Levi North
Seen from
Sweden
mamajhoe_part2
Seen from
Malaysia
Manyak RUHBAN +18
Seen from
Turkey
titipsebarmantanasli
Seen from
Indonesia
Cuck_hubby
Seen from
United States
Harley Quinn
Seen from
United Kingdom
Elena
Seen from
United States
Mariee13
Seen from
Oman
Trends for you
1
Colombia
Under 10K tweets
2
Ghana
Under 10K tweets
3
#AEWDynamite
Under 10K tweets
4
Versailles
Under 10K tweets
5
Azzi
Under 10K tweets
6
Olivia Miles
Under 10K tweets
7
Trae
Under 10K tweets
8
He is 21
Under 10K tweets
9
Hazuki
Under 10K tweets
10
Sydney Taylor
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.3M followers
2
Barack Obama
@barackobama
119.2M followers
3
Donald J. Trump
@realdonaldtrump
111.6M followers
4
Cristiano Ronaldo
@cristiano
109.7M followers
5
Narendra Modi
@narendramodi
106.9M followers
6
Rihanna
@rihanna
97.5M followers
7
NASA
@nasa
92.1M followers
8
Justin Bieber
@justinbieber
90.7M followers
9
KATY PERRY
@katyperry
87.2M followers
10
Taylor Swift
@taylorswift13
81M followers
11
Lady Gaga
@ladygaga
72.6M followers
12
Kim Kardashian
@kimkardashian
69.6M followers
13
Virat Kohli
@imvkohli
69.2M followers
14
YouTube
@youtube
68.6M followers
15
Bill Gates
@billgates
63.6M followers
16
The Ellen Show
@theellenshow
62.5M followers
17
Neymar Jr
@neymarjr
61.9M followers
18
CNN
@cnn
61.9M followers
19
X
@x
60.9M followers
20
Selena Gomez
@selenagomez
60.3M followers
Olivia
Online
✨
⭐
💫