We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning?
Pretraining is for knowledge.
Finetuning (SL/RL) is for habitual behavior.
Both of these involve a change in parameters but a lot of human learning feels more like a change in system prompt. You encounter a problem, figure something out, then "remember" something in fairly explicit terms for the next time. E.g. "It seems when I encounter this and that kind of a problem, I should try this and that kind of an approach/solution". It feels more like taking notes for yourself, i.e. something like the "Memory" feature but not to store per-user random facts, but general/global problem solving knowledge and strategies. LLMs are quite literally like the guy in Memento, except we haven't given them their scratchpad yet. Note that this paradigm is also significantly more powerful and data efficient because a knowledge-guided "review" stage is a significantly higher dimensional feedback channel than a reward scaler.
I was prompted to jot down this shower of thoughts after reading through Claude's system prompt, which currently seems to be around 17,000 words, specifying not just basic behavior style/preferences (e.g. refuse various requests related to song lyrics) but also a large amount of general problem solving strategies, e.g.:
"If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step."
This is to help Claude solve 'r' in strawberry etc. Imo this is not the kind of problem solving knowledge that should be baked into weights via Reinforcement Learning, or least not immediately/exclusively. And it certainly shouldn't come from human engineers writing system prompts by hand. It should come from System Prompt learning, which resembles RL in the setup, with the exception of the learning algorithm (edits vs gradient descent). A large section of the LLM system prompt could be written via system prompt learning, it would look a bit like the LLM writing a book for itself on how to solve problems. If this works it would be a new/powerful learning paradigm. With a lot of details left to figure out (how do the edits work? can/should you learn the edit system? how do you gradually move knowledge from the explicit system text to habitual weights, as humans seem to do? etc.).
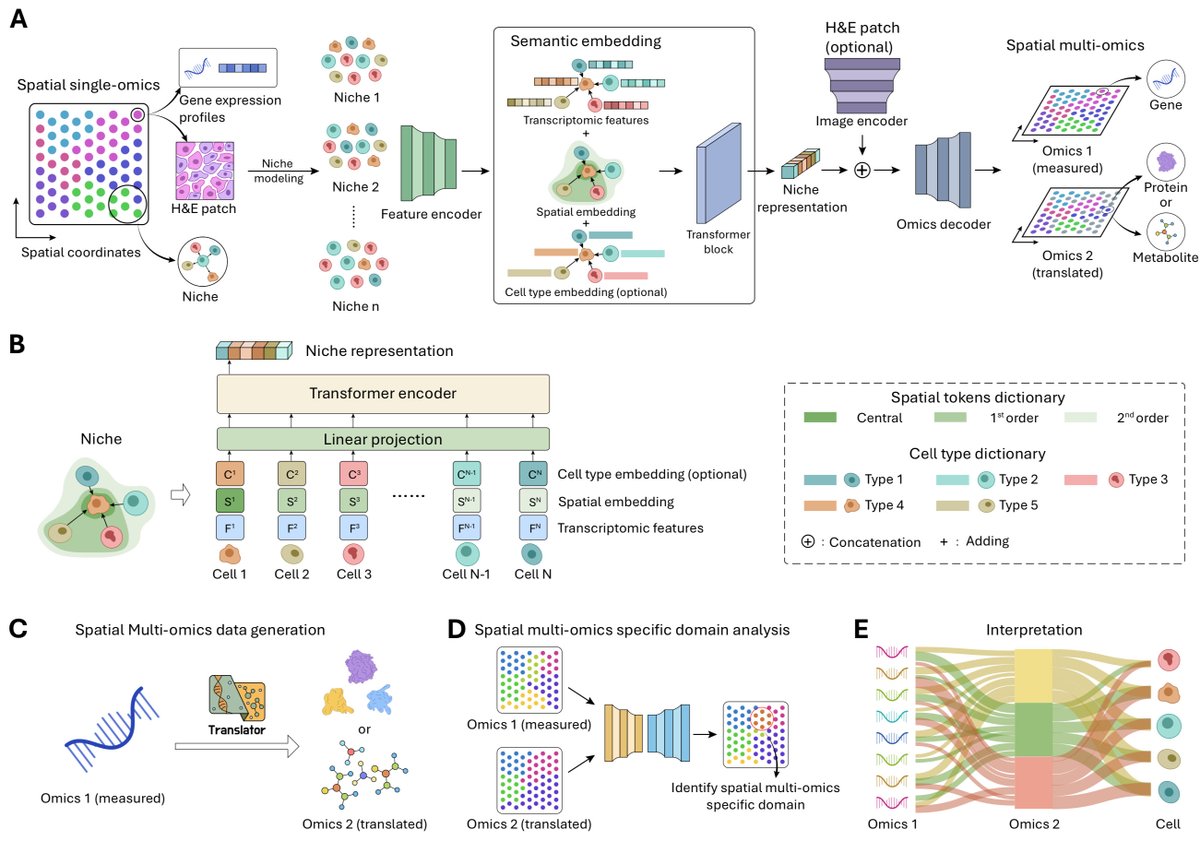
OmniCellTOSG: The First Cell Text-Omic Signaling Graphs Dataset for Joint LLM and GNN Modeling
1. OmniCellTOSG introduces the first large-scale dataset of text-omic signaling graphs (TOSGs), combining numeric transcriptomic features with rich textual annotations, enabling interpretable graph-based modeling of cell signaling systems.
2. Each TOSG represents a single cell or meta-cell and integrates gene/protein expression levels with textual knowledge on function, localization, and disease associations, facilitating joint training of LLM-GNN foundation models.
3. Built from over 117 million single-cell RNA-seq profiles across 22 organs and 21 disease types, the dataset was distilled into 547,168 high-quality meta-cells using the SEACells algorithm for noise reduction and interpretability.
4. Textual annotations were sourced from BioMedGraphica, and include HGNC symbols, UniProt descriptions, and biochemical data like IChIKeys, providing a multimodal node feature space for enhanced reasoning.
5. TOSGs are composed of transcript and virtual protein nodes, connected by edges derived from internal signaling and protein-protein interactions, yielding a graph structure that reflects biological regulatory networks.
6. The dataset supports downstream tasks like cell type classification, disease status prediction, and signaling graph reconstruction, with benchmark results showing that OmniCellTOSG-trained models outperform standard GNNs like GCN and GIN.
7. A unified foundation model architecture is proposed, where omic and textual encoders feed into a cross-modality encoder and GNNs to pretrain signaling-aware embeddings via masked protein-protein interaction edge prediction.
8. Extensive preprocessing included harmonizing datasets from CellxGene, GEO, SEA-AD, and Brain Cell Atlas, with cell types annotated via CellTypist and grouped into 135 major categories for consistent analysis.
9. The dataset is accessible via a PyTorch-compatible API (CellTOSGDataset), with flexible sampling, label selection, and control-normal balancing—enabling reproducible and memory-efficient downstream analyses.
10. OmniCellTOSG represents a paradigm shift in single-cell data modeling: from purely numeric gene expression to multimodal graph-based representations with LLM-injected biological knowledge.
11. This resource paves the way for next-generation models in systems biology and precision medicine—ones that can reason about signaling, context, and cell identity through language and structure.
💻Code: https://t.co/3w1OCRDWQ4
📜Paper: https://t.co/9io23VaN7a
#SingleCell #GNN #LLM #MultiOmics #CellAtlas #Bioinformatics #GraphAI #PrecisionMedicine #CellSignaling #TextOmics #DeepLearning #ComputationalBiology
GraphSeqLM: A Unified Graph Language Framework for Omic Graph Learning
1. Introducing GraphSeqLM, an innovative framework that combines graph neural networks (GNNs) with embeddings derived from biological sequences (DNA, RNA, and proteins) via large language models (LLMs) to revolutionize multi-omic data integration.
2. GraphSeqLM addresses the expressivity limitations of traditional GNNs by fusing topological, biological, and sequence-derived information, enabling precise predictions of patient outcomes in precision medicine.
3. Key innovation: The use of LLM-generated embeddings enriches GNNs, capturing structural and biological properties of omic data, significantly enhancing predictive accuracy across six cancer types.
4. Experimental results demonstrate GraphSeqLM consistently outperforms baseline models like GAT, GCN, and UniMP in prediction accuracy and F1 scores for cancer survival analysis.
5. The framework integrates multi-omic features into a multi-omic signaling knowledge graph (MOS-KG), facilitating a cross-modality fusion of data that surpasses existing approaches in capturing intricate biological patterns.
6. By leveraging advanced embeddings from tools like DNAGPT and ProtGPT2, GraphSeqLM ensures robust representation of biological sequence features and their interactions within signaling networks.
7. This work marks a significant step forward in computational biology, offering a scalable, interpretable, and effective solution for multi-omic data analysis in complex disease research.
💻Code: https://t.co/FLNL4sQMsB
📜Paper: https://t.co/MlAKCI5OD6
#GraphLearning #Bioinformatics #PrecisionMedicine #MultiOmicData #ArtificialIntelligence #LargeLanguageModels
🧬GWAS is fundamental in drug discovery, linking disease to genetic variants. However, studying rare and uncommon diseases with GWAS is hard due to the huge sample sizes required. How can we use AI to help GWAS with small cohorts?
In a multi-year collaboration @GSK@StanfordAILab@StanfordMed@SCSatCMU, we are thrilled to share Knowledge Graph GWAS (KGWAS), the largest AI model that integrates >10 millions of multi-modal and multi-scale functional genomics data to improve GWAS power by 100% while discovering novel disease-critical variants, genes, cells, and networks!
A huge shoutout to our stellar team of AI, statistics, and human genetics scientists: @tkyzeng Soner Koc, Alexandra Pettet @zhou_jingtian@MikaSarkinJain Dongbo @_camiloruiz@ren_hongyu@laurencejmshowe Tom Richardson, Adrián Cortés, Katie Aiello, Kim Branson, @apfenning@jengreitz@martinjzhang@jure
Paper: https://t.co/t0tAratBZI
1/15🧵
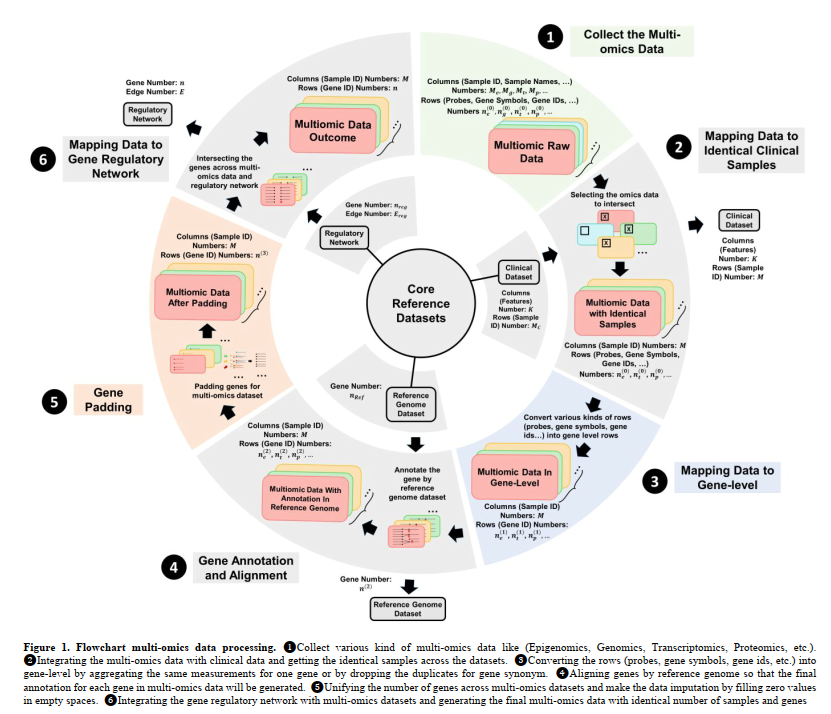
📊 "mosGraphGen: A novel tool to generate multi-omics signaling graphs to facilitate integrative and interpretable graph AI model development" enhances multi-omics data integration for AI models using cancer & Alzheimer's datasets. https://t.co/ZECFJ4Sndt #CancerResearch #AlzheimersResearch @_HemingZhang_@ccrugom@prpayne5
A wonderful camping experience! Never had I ever seen so many stars in the sky! Thanks for all my friends who made the efforts for this impressive camping! @ Ray Behrens Recreation Area https://t.co/zqteuRgq3s
Hua Chenyu 《 小镇里的花 Flower in a Small Town 》Ace vs Ace S7
🌸: "i'm hoping my mother would always be that gorgeous and beautiful flower, always blooming in my heart"
a song written in the last days of huahua's ailing mother, and the flower symbolizes her
🥺😭
#HuaChenyu
The moment we've all been waiting for: graph representation learning and geometric deep learning now have a targeted top-tier venue, starting this year!
It's been a pleasure to support and advise the efforts by the fantastic organising team!
Be sure to submit your best work :)
Introducing the 540 billion parameter Pathways Language Model. Trained on two Cloud #TPU v4 pods, it achieves state-of-the-art performance on benchmarks and shows exciting capabilities like mathematical reasoning, code writing, and even explaining jokes. https://t.co/NFHFAHgUkB