Stanford CS25 Talk TOMORROW (Thurs, 5/21) at 4:30pm PST 🤖
Victoria Lin (@VictoriaLinML) from Thinking Machines Lab (@thinkymachines) on: From Language Models to Native Multimodal Intelligence
What comes after LLMs? AI that natively understands the multimodal world! 👇(1/6)
Stanford CS25 Talk TODAY (Thurs, 5/14) at 4:30pm PST 🤖
Vivek Natarajan (@vivnat) from @GoogleDeepMind on: Advancing science and medicine with collaborative AI agents
AI co-scientists. AI co-physicians. This is one of the most futuristic CS25 talks yet 👀👇 (1/6)
Stanford CS25 Talk TOMORROW (Thurs, 5/7) at 4:30pm PST 🤖
Andrew Lampinen (@AndrewLampinen) from @AnthropicAI on: How models generalize from parameters vs. context
Turns out they behave very differently! 👇 (1/6)
This is the type of slop blowing up the number of submissions to conferences, screwing up the review process and wasting reviewers' time, and furthering the stochasticity of acceptances.
Our @Stanford CS25 lectures are getting a lot of engagement! Thanks to @hazel_heejeong and @lucasmaes_ for the great talk about JEPA and world models, as proposed by @ylecun. Check our course website for recordings, slides, and more info: https://t.co/69V2qLqBHm
Also, CS25 is open to everyone! We feature talks from top researchers each week. Lectures are Thursdays at 4:30pm PDT at Skilling Auditorium (Stanford) and on Zoom: https://t.co/qr9TAz2d3S
@_KaranPS_@StanfordOnline@stanfordaiclub@stanfordnlp@StanfordAILab@agihouse_org@MongoDB@modal
Stanford CS25 Talk TODAY (Thurs, 4/30) at 4:30pm PST🤖
Shrimai Prabhumoye (@shrimai_) from @MistralAI (prev. @nvidia) on: The Future of Pretraining
What comes after next-token prediction?👇(1/6)
Stanford CS25 Talk TODAY (Thurs, 4/23) at 4:30pm PST🤖
Nouamane Tazi (@Nouamanetazi) from @huggingface on: Scaling training to thousands of GPUs
If you care about how frontier LLMs are actually trained - don’t miss this👇(1/6)
Stanford CS25 Talk TOMORROW (Thurs, 4/16) at 4:30pm PST🤖
Albert Gu (@_albertgu) [CMU, Cartesia AI] on: Transformer alternatives - SSMs, Mamba, and beyond
If you care about the future of sequence models, you won't want to miss this!👇(1/5)
Stanford CS25 Talk Today: Hazel Nam & Lucas Maes, Brown University & Mila [JEPA and World Models]
Today (Thurs, 4/9) at 4:30pm PDT, @hazel_heejeong & @lucasmaes_ will be giving a talk for CS25 (https://t.co/Yvq4AcLiBV) at Skilling Auditorium (Stanford). The talk will also be livestreamed on Zoom at https://t.co/qr9TAz2d3S. As always, we are *open to everybody*, so drop by!
Presentation Title: From Representation Learning to World Modeling through Joint Embedding Predictive Architectures
Presentation Abstract: World models are increasingly moving away from reconstruction and toward prediction in latent space. In this talk, we will present two recent JEPA-based approaches that illustrate this shift from complementary angles.
Causal-JEPA induces object-level relational bias to promote representations that capture entities, and interactions, leading to stronger reasoning and more efficient planning. LeWorldModel shows that such predictive world models can also be trained stably end-to-end from raw pixels using a minimal objective and a clean architectural recipe, while remaining competitive on control tasks. Taken together, these works argue for a unified view of world modeling: predictive latent learning becomes most powerful when combined with both structural bias and architectural simplicity. This perspective suggests a promising path toward robust world models that support abstraction, reasoning, and control.
Speaker Bios: Heejeong (Hazel) Nam (@hazel_heejeong) is a Master's student at Brown University, working on representation learning, causality, and self-supervised learning. Lucas Maes (@lucasmaes_) is a PhD student at Mila and the University of Montreal, working on JEPA and planning.
Recordings, Slides, & More Info: The recordings will be released approx. 3 weeks after each talk on our YouTube playlist: https://t.co/ZNGVJxyk4f. Slides and more info are posted on our Discord server (https://t.co/vlDVm30x5F) and course website (https://t.co/Yvq4AcLiBV). Looking forward to seeing you all later today!
@_KaranPS_@Stanford@StanfordAILab@stanfordnlp@StanfordHAI@StanfordOnline@stanfordaiclub@agihouse_org@MongoDB@modal
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing
[CL] To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
K Singh, M Yu, V Gangal, Z Tao… [Stanford University & Patronus AI] (2026)
https://t.co/NXfOpLenr8
To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
Introduces a three-dimensional scaling framework modeling performance as a function of model size, pretraining tokens, and retrieval corpus size.
📝 https://t.co/Jh5hrZIqFg
👨🏽💻 https://t.co/I9gsetdu3v
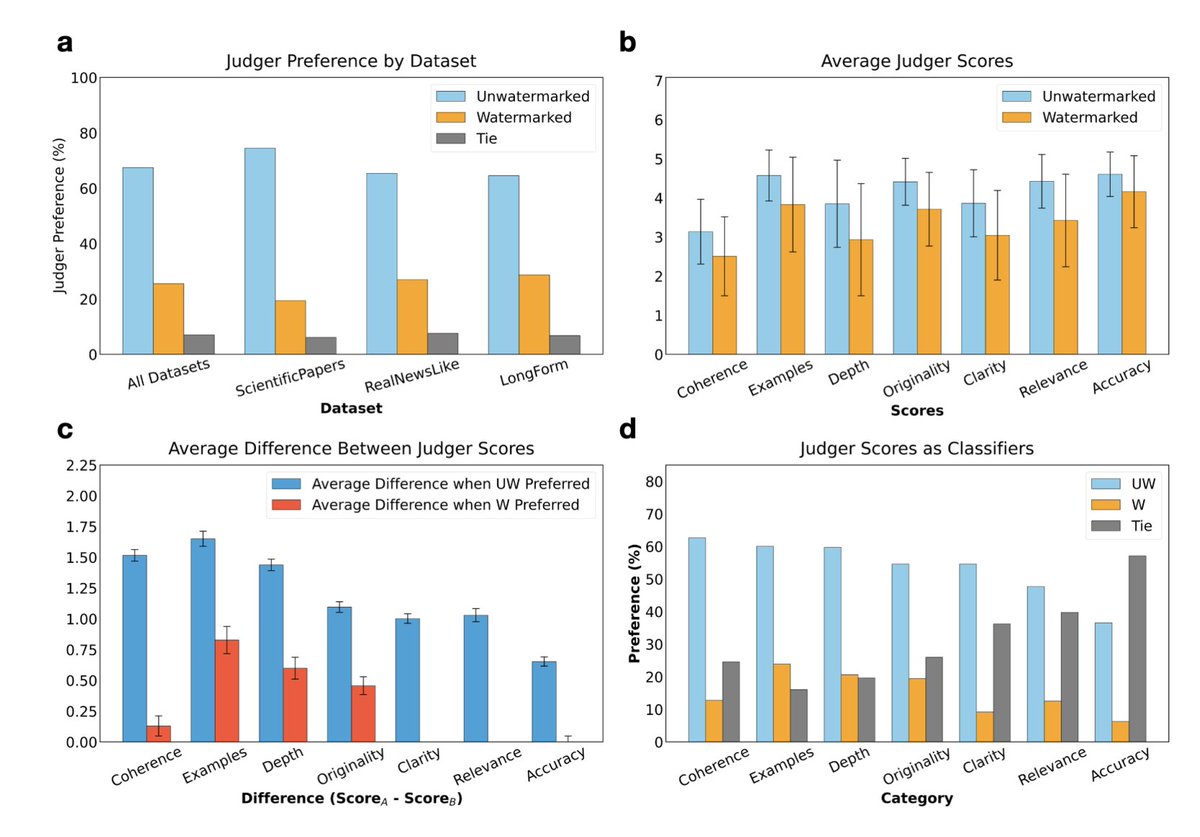
#watermarking helps to identify #AI-generated text. But how does it affect #LLM quality?🤔
Our new @TmlrOrg paper develops fine-grained tools to evaluate watermarks: popular watermarking methods can reduce coherence and depth of generations https://t.co/c9keI6m4qU
Great work by @_KaranPS_👏
As a Xmas present 🎄🎁, super excited to announce the public release of the lectures for CS 25: Transformers United V3 (https://t.co/cJn7UnKS1e) held
@Stanford
See the course preview below 👇:
Our first two lectures are live on Youtube and the rest to follow after the breaks 🔥
https://t.co/31JVTvqtC6
#AI #Transformers


![fly51fly's tweet photo. [CL] To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
K Singh, M Yu, V Gangal, Z Tao… [Stanford University & Patronus AI] (2026)
https://t.co/NXfOpLenr8 https://t.co/xiMI5AZSyF](https://pbs.twimg.com/media/HE7hLZIakAEFbMP.jpg)
![fly51fly's tweet photo. [CL] To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
K Singh, M Yu, V Gangal, Z Tao… [Stanford University & Patronus AI] (2026)
https://t.co/NXfOpLenr8 https://t.co/xiMI5AZSyF](https://pbs.twimg.com/media/HE7hLMtaoAAm2b8.jpg)
![fly51fly's tweet photo. [CL] To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
K Singh, M Yu, V Gangal, Z Tao… [Stanford University & Patronus AI] (2026)
https://t.co/NXfOpLenr8 https://t.co/xiMI5AZSyF](https://pbs.twimg.com/media/HE7hKvwbAAAfEnv.png)








![stevenyfeng's tweet photo. Stanford CS25 Talk TOMORROW (Thurs, 4/16) at 4:30pm PST🤖
Albert Gu (@_albertgu) [CMU, Cartesia AI] on: Transformer alternatives - SSMs, Mamba, and beyond
If you care about the future of sequence models, you won't want to miss this!👇(1/5) https://t.co/SwTp94GDxc](https://pbs.twimg.com/media/HGABbaTbEAABDAB.png)
![stevenyfeng's tweet photo. Stanford CS25 Talk Today: Hazel Nam & Lucas Maes, Brown University & Mila [JEPA and World Models]
Today (Thurs, 4/9) at 4:30pm PDT, @hazel_heejeong & @lucasmaes_ will be giving a talk for CS25 (https://t.co/Yvq4AcLiBV) at Skilling Auditorium (Stanford). The talk will also be livestreamed on Zoom at https://t.co/qr9TAz2d3S. As always, we are *open to everybody*, so drop by!
Presentation Title: From Representation Learning to World Modeling through Joint Embedding Predictive Architectures
Presentation Abstract: World models are increasingly moving away from reconstruction and toward prediction in latent space. In this talk, we will present two recent JEPA-based approaches that illustrate this shift from complementary angles.
Causal-JEPA induces object-level relational bias to promote representations that capture entities, and interactions, leading to stronger reasoning and more efficient planning. LeWorldModel shows that such predictive world models can also be trained stably end-to-end from raw pixels using a minimal objective and a clean architectural recipe, while remaining competitive on control tasks. Taken together, these works argue for a unified view of world modeling: predictive latent learning becomes most powerful when combined with both structural bias and architectural simplicity. This perspective suggests a promising path toward robust world models that support abstraction, reasoning, and control.
Speaker Bios: Heejeong (Hazel) Nam (@hazel_heejeong) is a Master's student at Brown University, working on representation learning, causality, and self-supervised learning. Lucas Maes (@lucasmaes_) is a PhD student at Mila and the University of Montreal, working on JEPA and planning.
Recordings, Slides, & More Info: The recordings will be released approx. 3 weeks after each talk on our YouTube playlist: https://t.co/ZNGVJxyk4f. Slides and more info are posted on our Discord server (https://t.co/vlDVm30x5F) and course website (https://t.co/Yvq4AcLiBV). Looking forward to seeing you all later today!
@_KaranPS_ @Stanford @StanfordAILab @stanfordnlp @StanfordHAI @StanfordOnline @stanfordaiclub @agihouse_org @MongoDB @modal
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing](https://pbs.twimg.com/media/HFe8MXfaYAAQKSA.png)
![fly51fly's tweet photo. [CL] To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
K Singh, M Yu, V Gangal, Z Tao… [Stanford University & Patronus AI] (2026)
https://t.co/NXfOpLenr8 https://t.co/xiMI5AZSyF](https://pbs.twimg.com/media/HE7hLnMbEAAUYLq.jpg)