Asked a healthcare AI founder: "how do you know when your agent is drifting across sessions, not just in one conversation?"
Their setup: observer agents, Slack alerts, manual review.
The gap: dashboard shows individual flags. Nobody connecting dots automatically across hundreds of sessions.
Manual triage doesn't scale past a point.
How are you catching drift before users feel it?
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Attended YC Startup School India?
Drop your favorite moment from the event below 👇
I'll add everyone who replies to an exclusive WhatsApp group for founders who were there.
The room was special, Real connect. No Fluff!
Let's keep it going!!
Is your agent's risk management process manual or automated?
What triggers a risk re-evaluation in your team, a new model version? A new tool? An incident?
What's your current human oversight model?
- Full automation, no human review
- Human reviews outputs after the fact
- Human approves before agent acts
- We don't have agents in prod yet
EU AI Act, Article 10 explained for AI teams. 🧵
Under the EU AI Act, the data your AI agent was trained on and has access to at runtime, must meet documented quality standards.
Your RAG pipeline is now compliance infrastructure.
Which Annex III categories could your agent touch?
Drop it in the replies. Genuinely curious how teams are mapping this.
Save this thread if you're building or deploying AI agents in production.
#EUAIAct#AIAgents#AICompliance#HighRiskAI
125 days until the EU AI Act applies to your production AI agents.
If your agent touches any of these 8 categories, you're already classified as high-risk.
Most teams don't know they're in scope. 🧵
explore the ancient wisdom of the Rig Veda through an immersive 3D experience! (turn up the volume)
link: https://t.co/AFr8LR4emy
retweets appreciated!
#RigVedaHack@indiainpixels@iipmaps
An attempt to explain (current) ChatGPT versions.
I still run into many, many people who don't know that:
- o3 is the obvious best thing for important/hard things. It is a reasoning model that is much stronger than 4o and if you are using ChatGPT professionally and not using o3 you're ngmi.
- 4o is different from o4. Yes I know lol. 4o is a good "daily driver" for many easy-medium questions. o4 is only available as mini for now, and is not as good as o3, and I'm not super sure why it's out right now.
Example basic "router" in my own personal use:
- Any simple query (e.g. "what foods are high in fiber"?) => 4o (about ~40% of my use)
- Any hard/important enough query where I am willing to wait a bit (e.g. "help me understand this tax thing...") => o3 (about ~40% of my use)
- I am vibe coding (e.g. "change this code so that...") => 4.1 (about ~10% of my use)
- I want to deeply understand one topic - I want GPT to go off for 10 minutes, look at many, many links and summarize a topic for me. (e.g. "help me understand the rise and fall of Luminar"). => Deep Research (about ~10% of my use). Note that Deep Research is not a model version to be picked from the model picker (!!!), it is a toggle inside the Tools. Under the hood it is based on o3, but I believe is not fully equivalent of just asking o3 the same query, but I am not sure.
All of this is only within the ChatGPT universe of models. In practice my use is more complicated because I like to bounce between all of ChatGPT, Claude, Gemini, Grok and Perplexity depending on the task and out of research interest.
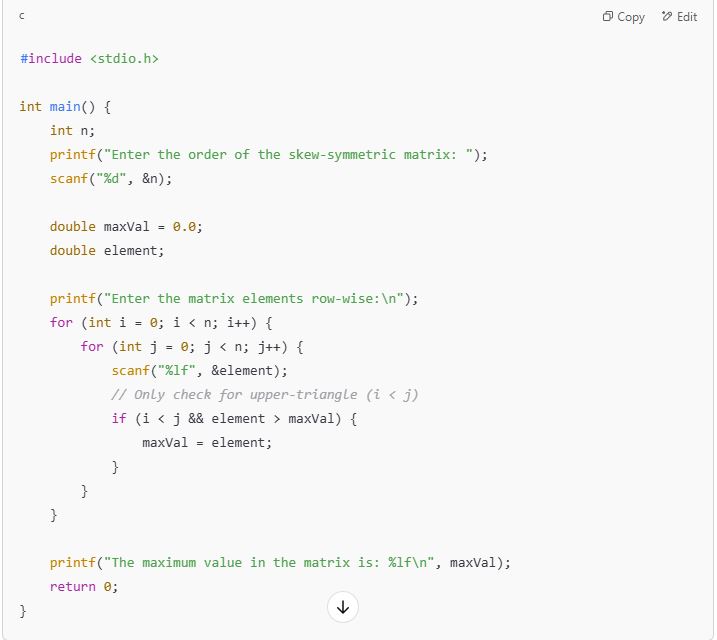
o3-mini vs Deepseek-r1: As the battle between o3-mini and Deepseek-r1 heats up, we put them to test with a simple linear algebra coding task. Prompt: Write a C program to find the maximum value in a skew-symmetric matrix. The results surprised us! Seems mini is yet to mature😅
"Build LLM in India" – Stop Lying to Yourselves and Fix VCs
It’s been almost two years since @sama said, “you can try,” and someone from Mahindra Group responded with “challenge accepted.” Where are the models competing with OpenAI, Anthropic, or DeepMind?
In Nandan Nilekani's recent podcast with Nikhil Kamath, the tech lead at the government level bluntly admitted, "building LLMs is not for us." That’s a pathetic, defeatist mindset.
@AravSrinivas is right. Look at the U.S.—their top tech companies and government work in tandem, nullifying benchmarks with every release. Here, all we do is talk. India seems content with the reputation of doing things cheaply while China leads the way in execution. Somehow only China can trigger us.
@paraschopra, @championswimmer, @waitin4agi_—all on point. Talent isn’t the issue; it’s the lack of courage. We’re stuck hyping 10-minute deliveries and obsessing over tangible commodities. Most universities don’t even offer decent AI curricula. Mediocre college placements churn out graduates who’ve never seen money, so their only goal is stability. Ambition comes later—if at all. I can’t convince one friend to quit their job and build something meaningful because they draw the line at financial risk. It’s a vicious cycle.
How do we fix this?
Break the VC/investor trap. They won’t back ambitious founders unless they see "differentiators." What differentiators do OpenAI, Anthropic, or DeepMind have? They’re all chasing benchmarks and mining the same gold. Meanwhile, our VCs keep betting on "build for India" garbage—e-com, UPI fintech, quick commerce. Enough! Start funding "build for the world."
Indian Founders don’t need massive funding to start. $30-50k (₹25-40L) is enough for most ambitious founders to prove their commitment. But no one funds pre-seed at that scale. Show us you’re willing to disproportionately back talent. Stop forcing them to move to the U.S. just to get funded. Then, when they succeed, you call them "Indian founders" as if you had their back all along.
We don’t lack ambition; we lack support. Back small, ambitious companies with compounding potential. That’s how you win.
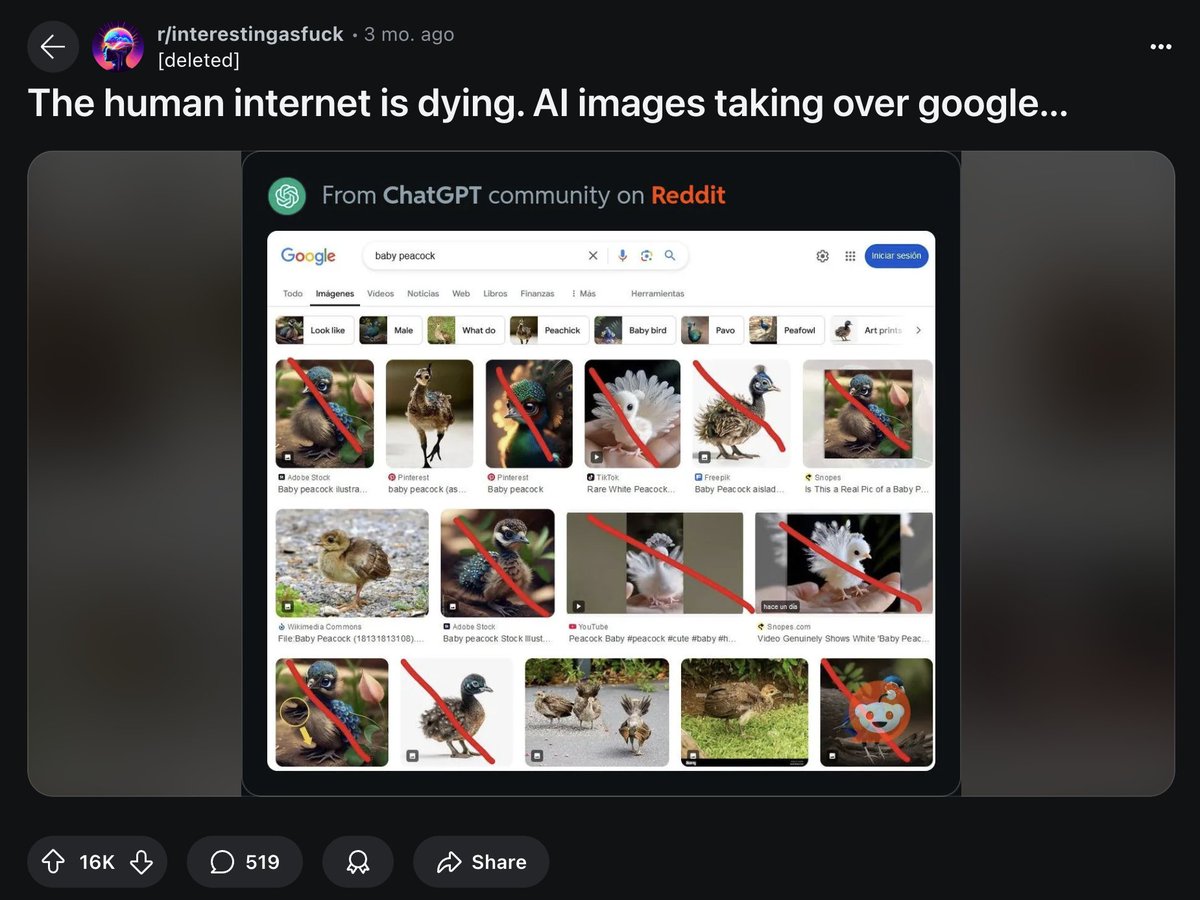
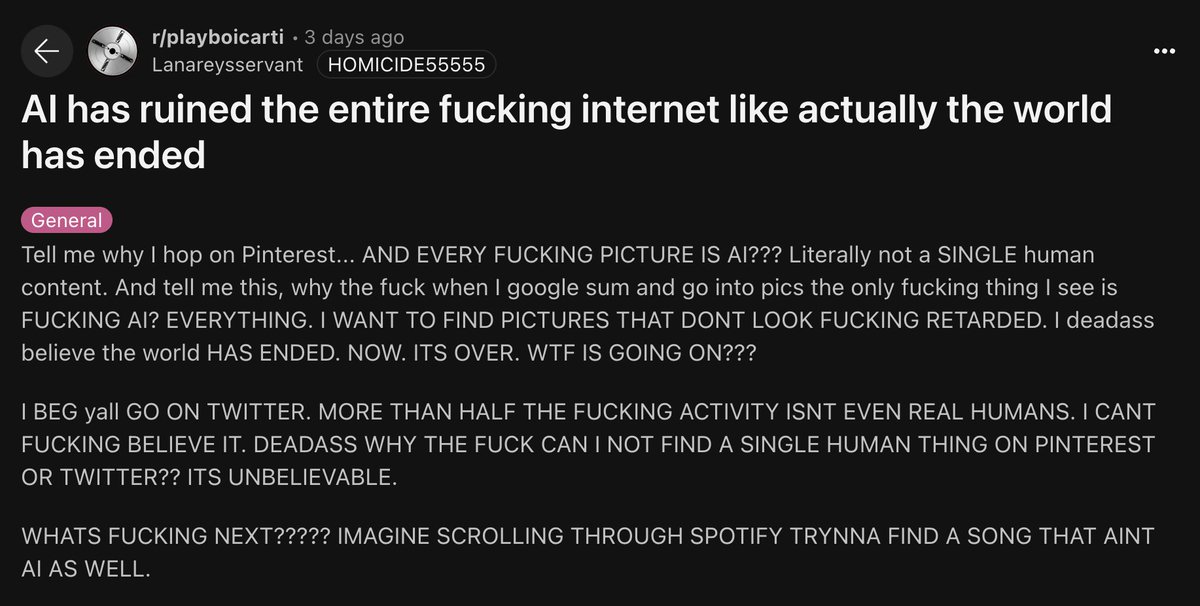
Dead Internet Theory, the conspiracy that the internet is mostly bots, is happening.
AI generated content is killing the internet slowly.
Reddit posts.
Pinterest.
Google results.
Facebook videos.
Spotify music.
And most people don't even know it's happening.
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet.
Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context window and improved support for 8 languages among other improvements. Llama 3.1 405B rivals leading closed source models on state-of-the-art capabilities across a range of tasks in general knowledge, steerability, math, tool use and multilingual translation.
The models are available to download now directly from Meta or @huggingface. With today’s release the ecosystem is also ready to go with 25+ partners rolling out our latest models — including @awscloud, @nvidia, @databricks, @groqinc, @dell, @azure and @googlecloud ready on day one.
More details in the full announcement ➡️ https://t.co/hhJoLm5eLV
Download Llama 3.1 models ➡️ https://t.co/rRjvmxqCTC
With these releases we’re setting the stage for unprecedented new opportunities and we can’t wait to see the innovation our newest models will unlock across all levels of the AI community.
There's a viral video going around about an MIT neurosurgeon who quit to spend time alone in the mountains.
It's such a great perspective on our broken healthcare system (and getting healthy) that I thought I'd share the key excerpt here:
Meta's PyTorch teams published their actual roadmap documents publicly for the first time: https://t.co/Gp4C3i9D6j
Our engineers' incentives and objectives are laid bare for folks to read 🙂
While all PyTorch development happens publicly on github, the actual planning and roadmap documents that teams at various PyTorch-affiliated companies write out weren't public, so we decided to change that for increased transparency.
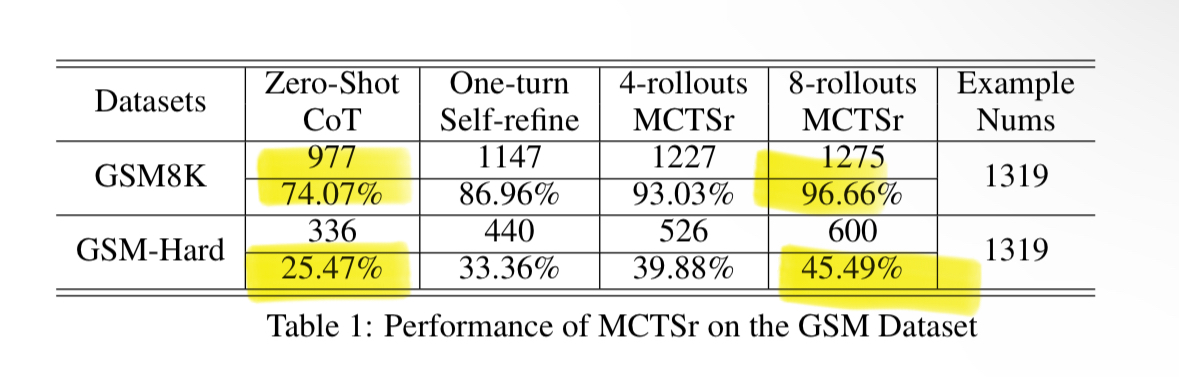
It's finally here. Q* rings true. Tiny LLMs are as good at math as a frontier model.
By using the same techniques Google used to solve Go (MTCS and backprop), Llama8B gets 96.7% on math benchmark GSM8K!
That’s better than GPT-4, Claude and Gemini, with 200x less parameters!
Introducing Samba 3.8B, a simple Mamba+Sliding Window Attention architecture that outperforms Phi3-mini on major benchmarks (e.g., MMLU, GSM8K and HumanEval) by a large margin.😮 And it has an infinite context length with linear complexity.🤯
Paper: https://t.co/KwMpeyaDxc
(1/6)