Dietician: "Congratulations. Your diet is almost perfect. Whole grains, legumes, seasonal vegetables. Very heart-healthy."
Medieval English Peasant: "I have scurvy."
Dietician: "The fibre content alone..."
Peasant: "My teeth fell out last winter."
Dietician: "The complex carbohydrates..."
Peasant: "I have not eaten meat in four months. I dream about it."
Dietician: "Red meat is not necessary."
Peasant: "My children are small. They do not grow."
Dietician: "They're getting excellent plant protein."
Peasant: "They are getting rye bread and pottage. The lord ate beef last night. We could smell it."
Dietician: "His diet is actually worse for him."
Peasant: "He is six feet tall and has all his teeth."
Dietician: "But his cholesterol..."
Peasant: "I do not know what that is. I know that I am dying correctly."
Almost every AI power user I know is MORE stressed and busier after using AI, not less
What people thought AI would do: 10x productivity so that we can finish work earlier & relax more
What it’s actually doing: 10x productivity so that we end up with 20x more things to do cos of the sheer possibilities
The ability to quickly reset and recover. From a bad interaction. From a bad day. From a missed workout. From a poor decision. You can start over whenever you want. You can't always control what happened, but you can control how long you carry it.
People get high on abstraction too early. They want the system before they’ve earned the insight.
But the good abstractions are never designed. They’re discovered. You do the stupid manual thing enough times and the real bottleneck just emerges. Your initial agency might be driven by a hunch you had in the shower, but that moment won’t get you all the way to making something people want. The right way to make anything is forced on you by reality: what are the real jobs to be done? And what sequence?
This is why “do things that don’t scale” still hits, especially now when AI makes it trivially easy to scale things that probably shouldn’t be scaled yet. PG’s point was never about suffering. It was about contact. When you’re the one manually doing the loop, you see the edge cases. The weird user behavior. The failure modes nobody designed for. The hidden dependencies that only show up at 2am when some flow or intermediate step breaks in a way you didn’t anticipate. If you automate before you have that contact, you just scale your misunderstanding faster.
When the machines can help you vibe code perfection it gives you a false sense of power. I love that feeling as much as you do. But fuck perfection. Do it live. Be the loop.
Feel every friction point. Notice what’s actually true every single time versus what just looked true because you hadn’t seen enough cases yet. Formalize that. Build the recursive version. Then keep checking that your abstraction is still attached to real humans and their needs. Because reality drifts. Your users drift. The ground truth changes under you. You may think you understand but no plan survives contact with the real users and what they want. You find those body blows in analytics and user feedback and we call them the roadmap.
Humans left with not enough data hallucinate too. But just like the LLMs with enough data you unlock real transcendence. Real utility. Prosperity for humans in real life.
The abstraction is a tool, not a destination. The moment you forget that, you’re cooked.
3/ Test results
1. ChatGPT screws up basic shapes.
2. Claude sticks to rectangles and colours. Aesthetic is simple and clean.
3. Gemini has the best results so far.
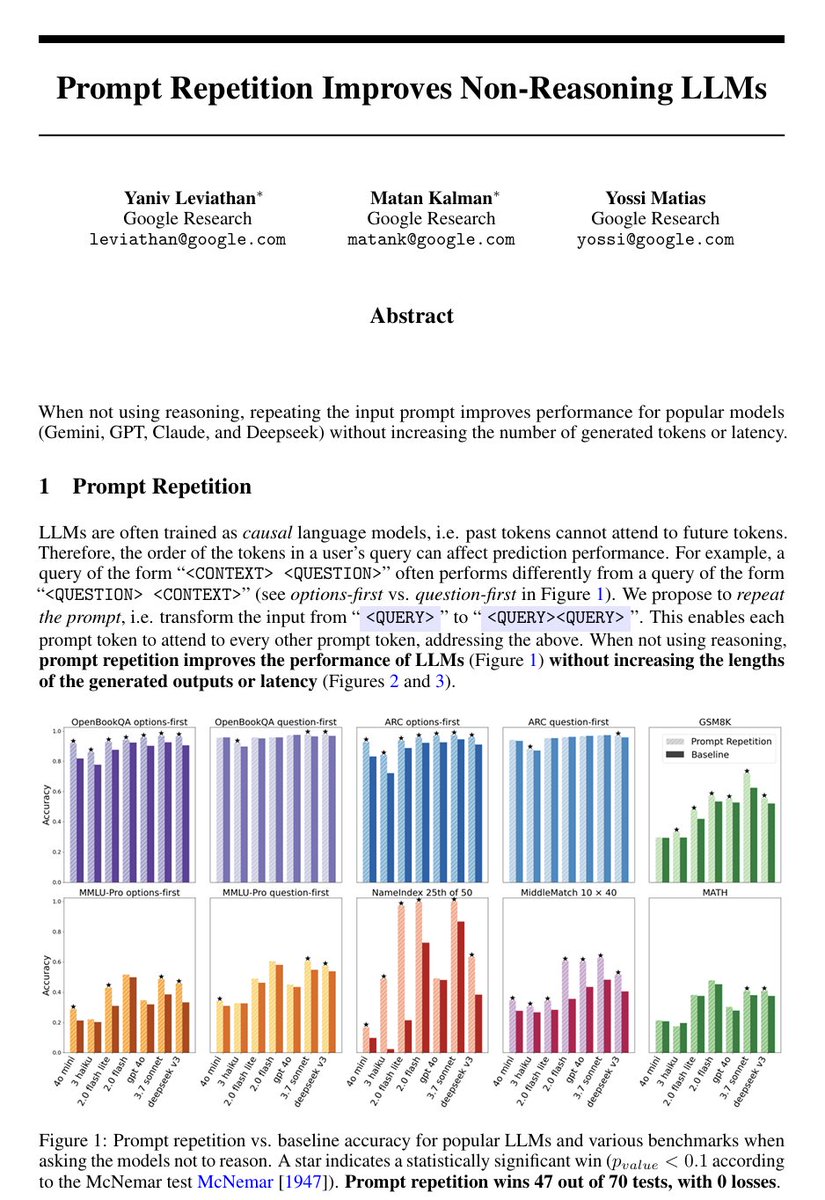
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: https://t.co/MipHHO6rjX
Get the PDF: https://t.co/XQrqiaGwIO
One of the things I’ve been grappling with is the idea that clear feedback produces students who can’t sensemake from their own experiences.
That hobbles them somewhat in life.
Reflecting on your own experiences is a skill, like any other.