GPT-5.2 derived a new result in theoretical physics.
We’re releasing the result in a preprint with researchers from @the_IAS, @VanderbiltU, @Cambridge_Uni, and @Harvard. It shows that a gluon interaction many physicists expected would not occur can arise under specific conditions.
https://t.co/EAZhKWacsG
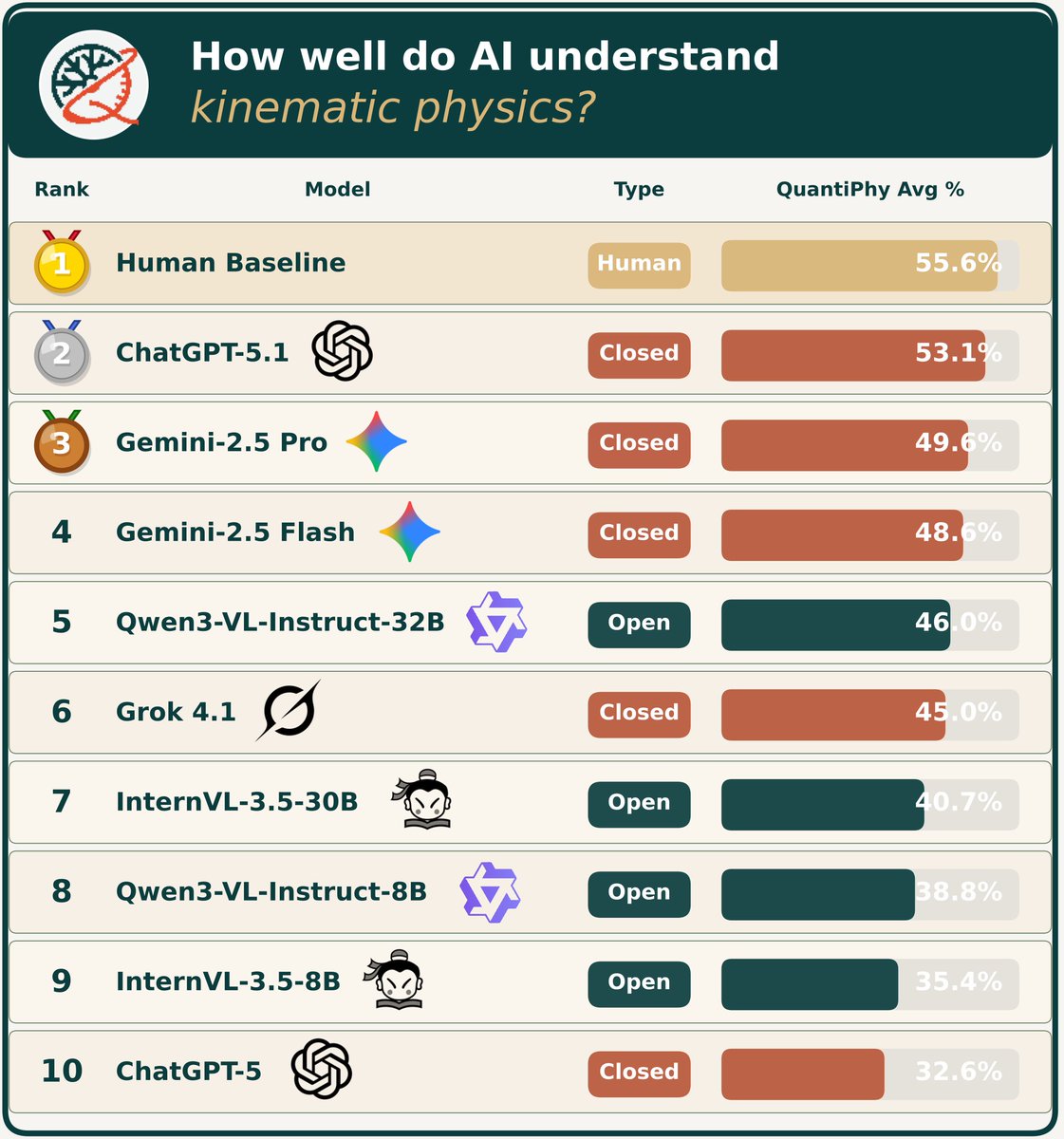
‼️VLMs/MLLMs do NOT yet understand the physical world from videos‼️
In our recent work, we found that even the most advanced AI models still lag behind humans in one key aspect: reasoning about the kinematic properties of objects from videos.
Takeaways:
1. ChatGPT 5.1 leads overall among 21 advanced VLMs, followed by Gemini 2.5 Pro/Flash.
2. Grok 4.1 delivers impressive performance at the lowest API cost.
3. Qwen3-VL is the top-performing open-source model.
Read here: https://t.co/5lagvLNE37
🧵1/N
This is the shift people keep missing.
LLMs aren’t just tools or personalities — they’re population simulators.
Once you stop forcing them into a single voice, entirely new classes of work open up.
Congrats on the launch @simile_ai ! (and I am excited to be involved as a small angel.)
Simile is working on a really interesting, imo under-explored dimension of LLMs. Usually, the LLMs you talk to have a single, specific, crafted personality. But in principle, the native, primordial form of a pretrained LLM is that it is a simulation engine trained over the text of a highly diverse population of people on the internet. Why not lean into that statistical power: Why simulate one "person" when you could try to simulate a population? How do you build such a simulator? How do you manage its entropy? How faithful is it? How can it be useful? What emergent properties might arise of similes in loops?
Imo these are very interesting, promising and under-explored topics and the team here is great. All the best!
@karpathy The core of GPT fits in a few hundred lines.
Everything else is scale, optimization, reliability, and distribution.
That’s where almost all the real difficulty lives.
The core of GPT fits in a few hundred lines.
Everything else is scale, optimization, reliability, and distribution.
That’s where almost all the real difficulty lives.
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
AI isn’t one big trade anymore — it’s a structure play.
Capital is flowing into memory, chips, and infra, while traditional software gets repriced.
The signal is clear: inputs beat layers that can be internalized.
GPT-2 going from “too dangerous to release”
to “new MNIST” is a reminder that capability isn’t static —
it’s a function of cost curves and tooling maturity.
Enabled fp8 training for +4.3% improvement to "time to GPT-2", down to 2.91 hours now. Also worth noting that if you use 8XH100 spot instance prices, this GPT-2 repro really only costs ~$20. So this is exciting -
GPT-2 (7 years ago): too dangerous to release.
GPT-2 (today): new MNIST! :)
Surely this can go well below 1 hr.
A few more words on fp8, it was a little bit more tricky than I anticipated and it took me a while to reach for it and even now I'm not 100% sure if it's a great idea because of less overall support for it. On paper, fp8 on H100 is 2X the FLOPS, but in practice it's a lot less. We're not 100% compute bound in the actual training run, there is extra overhead from added scale conversions, the GEMMs are not large enough on GPT-2 scale to make the overhead clearly worth it, and of course - at lower precision the quality of each step is smaller. For rowwise scaling recipe the fp8 vs bf16 loss curves were quite close but it was stepping net slower. For tensorwise scaling the loss curves separated more (i.e. each step is of worse quality), but we now at least do get a speedup (~7.3%). You can naively recover the performance by bumping the training horizon (you train for more steps, but each step is faster) and hope that on net you come out ahead. In this case and overall, playing with these recipes and training horizons a bit, so far I ended up with ~5% speedup. torchao in their paper reports Llama3-8B fp8 training speedup of 25% (vs my ~7.3% without taking into account capability), which is closer to what I was hoping for initially, though Llama3-8B is a lot bigger model. This is probably not the end of the fp8 saga. it should be possible to improve things by picking and choosing which layers to apply it on exactly, and being more careful with the numerics across the network.
This paper is kinda crazy but there's a big caveat imo.
"We are able to train the 8B parameter size of Qwen2.5
to 91% accuracy on GSM8K with only 13 trained parameters in bf16 (26 total bytes)." --> wild!!
"in this low-parameter setting LLAMA is
less responsive than Qwen and reaches 85% with an update size of 1KB (500 parameters trained in bf16)."
"Unlike Qwen, when we train fewer than five parameters, LLAMA barely improves performance above baseline."
So once again, Qwen is likely a bit of an outlier in its behavior, and unclear how well other regular LLMs can learn reasoning with limited params. Would love to see more thorough experiments on this.
This isn’t about better agents.
It’s about enterprises standardizing how work itself is delegated.
Frontier looks less like a product, more like an operating layer for labor.
Introducing OpenAI Frontier—a new platform that helps enterprises build, deploy, and manage AI coworkers that can do real work. https://t.co/4W0adQzSZ1
@OpenAIDevs This is Apple making agentic coding a default workflow, not a side experiment.
When agents ship inside Xcode, “AI-assisted coding” quietly becomes just “coding.”
This is Apple making agentic coding a default workflow, not a side experiment.
When agents ship inside Xcode, “AI-assisted coding” quietly becomes just “coding.”
@karpathy This is the real scaling story.
Frontier models grab headlines, but capability is quietly becoming cheap, reproducible, and local.
When GPT-2 is <$100, the floor for experimentation disappears.
This is the real scaling story.
Frontier models grab headlines, but capability is quietly becoming cheap, reproducible, and local.
When GPT-2 is <$100, the floor for experimentation disappears.
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node).
GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100.
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try.
A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here:
https://t.co/vhnK0d3L7B
Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning.
The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up.
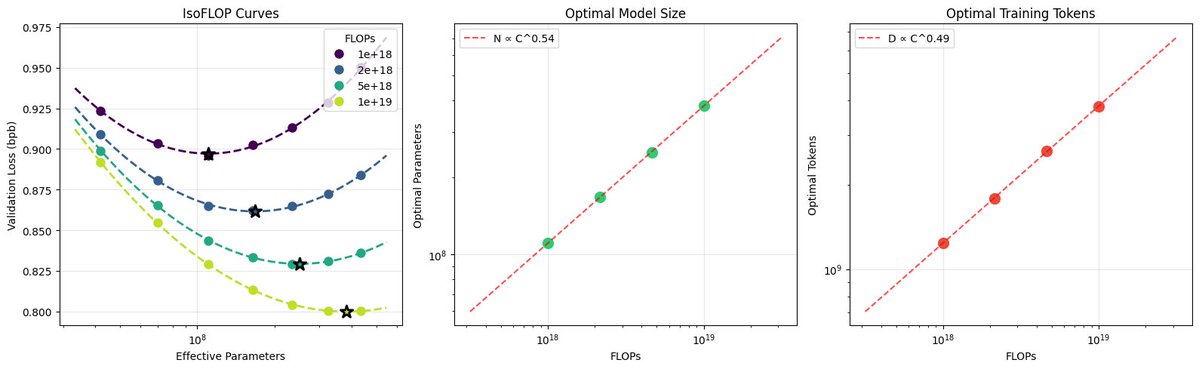
Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
This isn’t really about ads vs no ads.
It’s about which AI companies believe the assistant is a product surface — and which believe it’s infrastructure.
Those lead to very different incentives over time.
Anthropic just took a big swipe at OpenAI's decision to put ads in ChatGPT. Anthropic is airing ads mocking ChatGPT ads during the Super Bowl, and they're hilarious 😅 Anthropic is also committing to no ads in Claude https://t.co/LR1v4xz9ds
This feels like a real shift in alignment thinking.
Instead of cleaning up models after pretraining, safety and factuality are being baked into what the model learns from day one.
Long-term, this matters more than any single post-training trick.
Paper:https://t.co/KpizSDDgSI
@nickfloats This isn’t an identity crisis — it’s a role transition.
When execution becomes cheap, value shifts to framing problems, setting constraints, and deciding what should be built.
Builders aren’t disappearing. The definition of building is changing.
This isn’t an identity crisis — it’s a role transition.
When execution becomes cheap, value shifts to framing problems, setting constraints, and deciding what should be built.
Builders aren’t disappearing. The definition of building is changing.
Big identity crisis in many engineering circles rn.
People who've historically considered themselves "builders" now realizing they aren't the ones building shit anymore, AI is.
The moral superiority of the "I build things, you just talk" mentality is irrelevant now that the coding language is english and anyone can build things by talking.
The skills that made them so economically valuable are almost fully commoditized, and they're being forced to adopt a new identity.
An identity most of them despise and have mocked their entire careers.
To remain relevant, they must become the "idea guy"