Keller's approach (ultra-fast iteration) is promising because it lead to the first major innovation since Adam (Muon). CIFAR was only 2 seconds to train end-to-end which meant he could try many ideas fast. His first unoptimized Muon run was something like 30 seconds but it was clear it was onto something due to large drop in steps
Like @davidbessis and others, I think that Hinton is wrong. To explain why, let me tell you a brief story.
About a decade ago, in 2017, I developed an automated theorem-proving framework that was ultimately integrated into Mathematica (see: https://t.co/nGCIUk44TP) (1/15)
@konstmish@clashluke A while ago for many small networks (cnn, MLP) we had found that the gradient second moment, fisher and hessian tended to align pretty early in training
@tensor_rotator@F_Vaggi@TacoCohen@dwarkesh_sp We had some fun paper a while ago on it https://t.co/F4FysUVWG1 and it seems like the value function does a better job at exploring (being optimistic/having "high standards") compared to the variance reducing baseline
@tensor_rotator@F_Vaggi@TacoCohen@dwarkesh_sp Actually, the value function can be a very poor baseline for reducing the variance of the gradient: in a simple 2 arm bandit with rewards 1 and 0 and (sigmoid) proba p and 1-p the value function would be p while the variance reducing baseline is 1-p! So those are anticorrelated!
@DimitrisPapail I see it's because you don't use a baseline so the update for non valid tokens is 0 right?
Do you think you generally get rid of the baseline?
Maybe to one's surprise, taking KL estimates as `kl_loss` to minimize does *not* enforce the KL.
This implementation, however, is quite common in open source RL repos and recent research papers.
In short: grad of an unbiased KL estimate is not an unbiased estimate of KL grad.
Can neural networks learn to map from observational datasets directly onto causal effects?
YES! Introducing CausalPFN, a foundation model trained on simulated data that learns to do in-context heterogeneous causal effect estimation, based on prior-fitted networks (PFNs). Joint work with @Layer6AI & @hamid_R_kamkar
w/ @_valthomas, Jeremy Ma, Benson Li, Jesse C. Cresswell, & @rahulgk
📝ArXiv: https://t.co/jc9plTMo44
🔗Code: https://t.co/MVO8j24mR8
🗣️Oral paper @ ICML SIM workshop
🧵[1/7]
@leloykun Isn't that just a bias you can fold in the learning rate? I'm not sure it matters at all compared to having a non constant bias of the return (by using a value function for instance)
@y0b1byte And I totally forgot but it leads to an additional
-pi1 grad log pi
For the negative sample
So RL pushed down log prob of negative samples but doesn't push up as much log prob of positive
In contrast SFT pushes up/copies positives examples
@y0b1byte So you also didn't add a baseline, if you do it's value is pi(tau1)
Leading to
(1 - pi(tau1)) Nabla log pi(tau1)
For the gradient. So there's an additional saturation effect which can also help with exploration
@FSchaipp That's a very interesting question.
I had worked on second order, fisher, and some ADMM stuff a while ago. it was kind of an open secret among optimization researchers I knew that it didn't generalize as well.
Would love to see it confirmed or debunked!
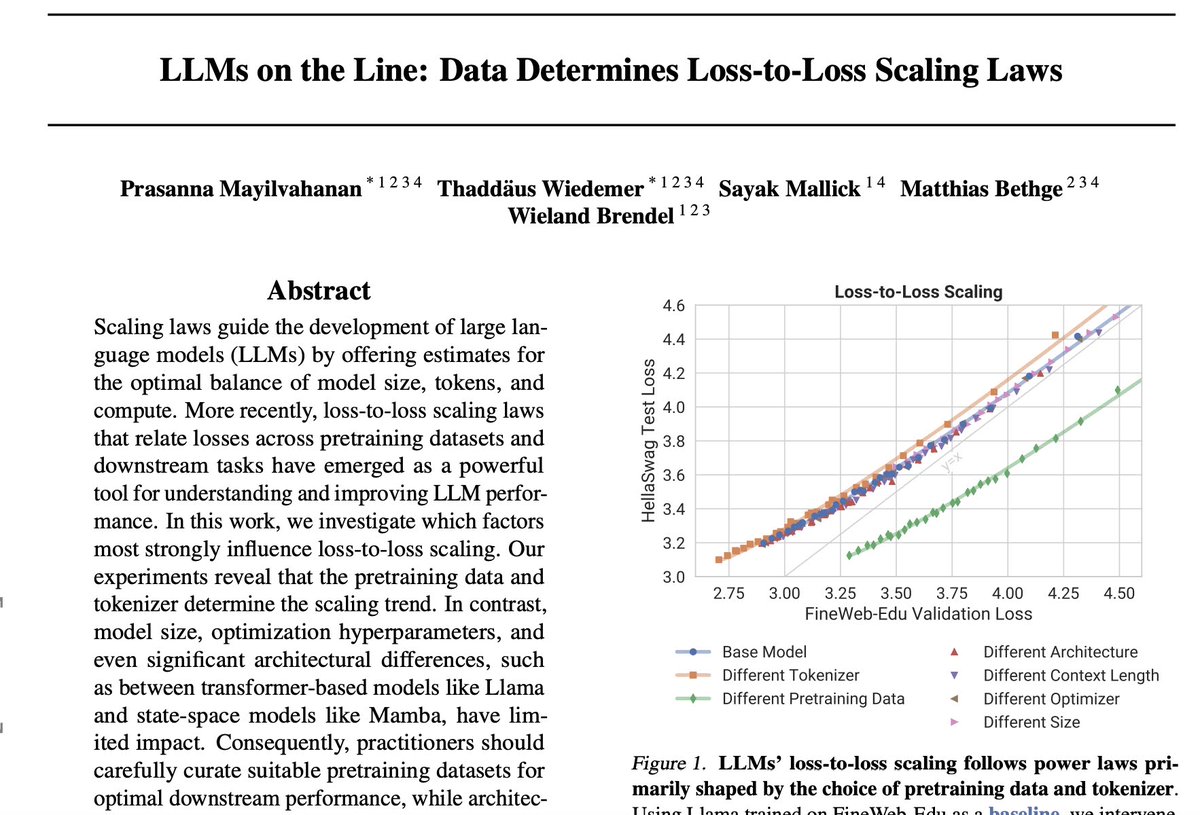
Optimization hyperparameters (LR, schedule, weight decay) do not affect loss-to-loss scaling of LLMs (which could be seen as a proxy for generalization). ☄️
Unclear: how about different optimizers (Shampoo, ScheduleFree...)?
Plots from this paper: https://t.co/h7F6yafLaA
*Every single* cure for a disease ultimately flowed from basic exploratory research. Stopping basic research is like stopping the mountain rains and expecting rivers of cures to still flow. Examples:
1) studying saliva of Gila monster -> GLP1's
2) studying funghi -> first statins
3) mRNA biology -> gene therapy for spinal atrophy
4) studying bacterial genetics -> CRISPR gene therapies
5) studies of nuclear magnetic resonance -> MRI scans
this list can go on and on. Not only in biology but all aspects of technology.... e.g.
6) curvature of spacetime -> GPS
7) quantum mechanics -> semiconductors
8) electromagnetism -> fiber optics -> internet
...















![vahidbalazadeh's tweet photo. Can neural networks learn to map from observational datasets directly onto causal effects?
YES! Introducing CausalPFN, a foundation model trained on simulated data that learns to do in-context heterogeneous causal effect estimation, based on prior-fitted networks (PFNs). Joint work with @Layer6AI & @hamid_R_kamkar
w/ @_valthomas, Jeremy Ma, Benson Li, Jesse C. Cresswell, & @rahulgk
📝ArXiv: https://t.co/jc9plTMo44
🔗Code: https://t.co/MVO8j24mR8
🗣️Oral paper @ ICML SIM workshop
🧵[1/7]](https://pbs.twimg.com/media/GtHitrKXkAEl_vS.jpg)