AI is compute-hungry. While it has generally relied on a single hardware vendor in the past, AMD GPUs now offer competitive memory and compute throughput. Yet, the software stack is brittle.
So we ask: can the same DSL principles that simplified NVIDIA kernel dev translate to AMD? We’re excited to introduce the newest addition to the ThunderKittens cinematic universe of kernel DSLs: HipKittens (HK) 🚀for Fast and Furious AMD kernels.
Fresh blog post!
@modal partnered with @ScalingIntelLab, @HazyResearch, and @chelseabfinn's IRIS Lab to speed up research on speeding up AI research.
Read how scientists at the cutting edge are building the machines that build the machines with Modal.
https://t.co/FDbnp8DOuC
Announcing Flapping Airplanes!
We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet.
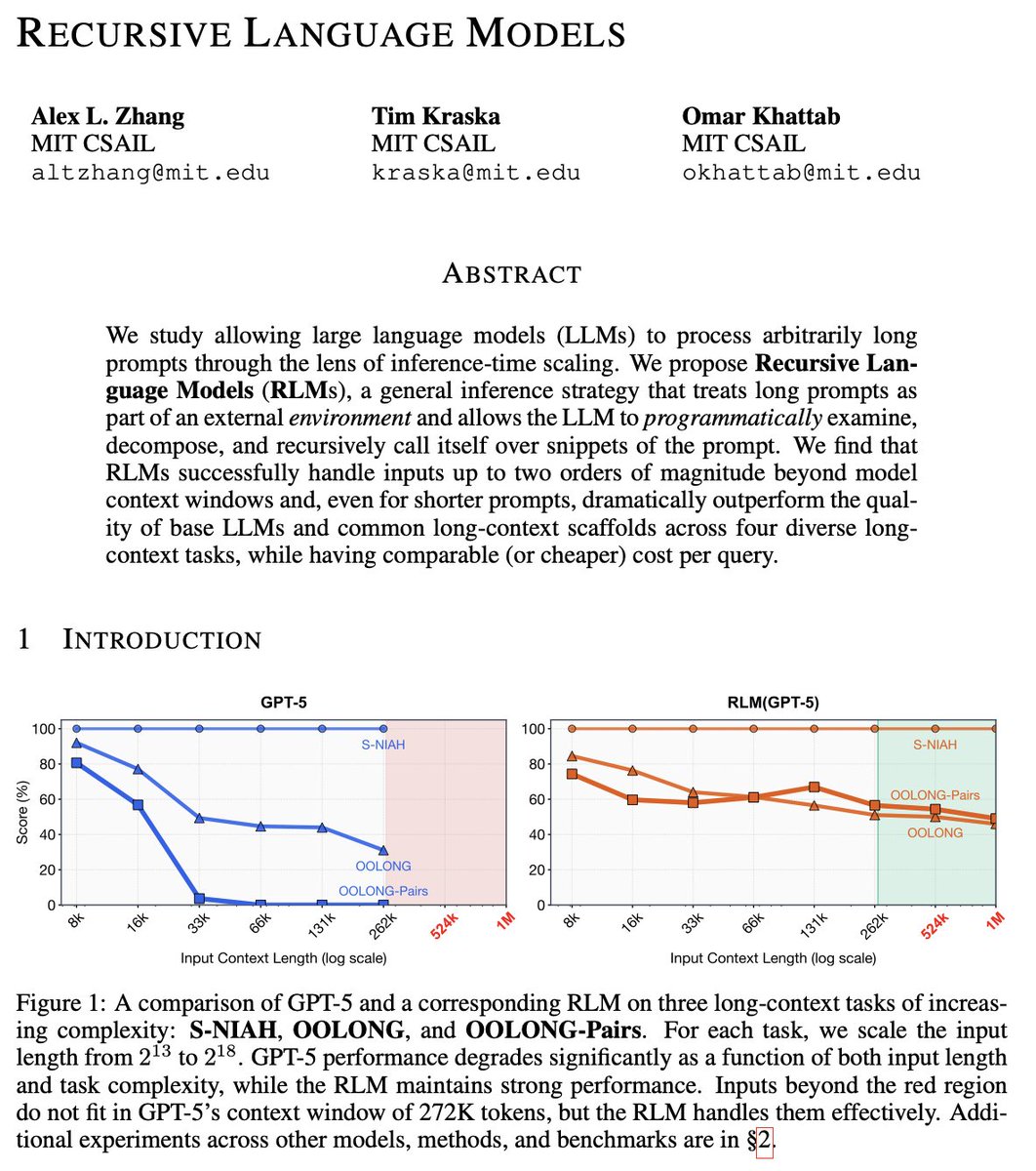
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb
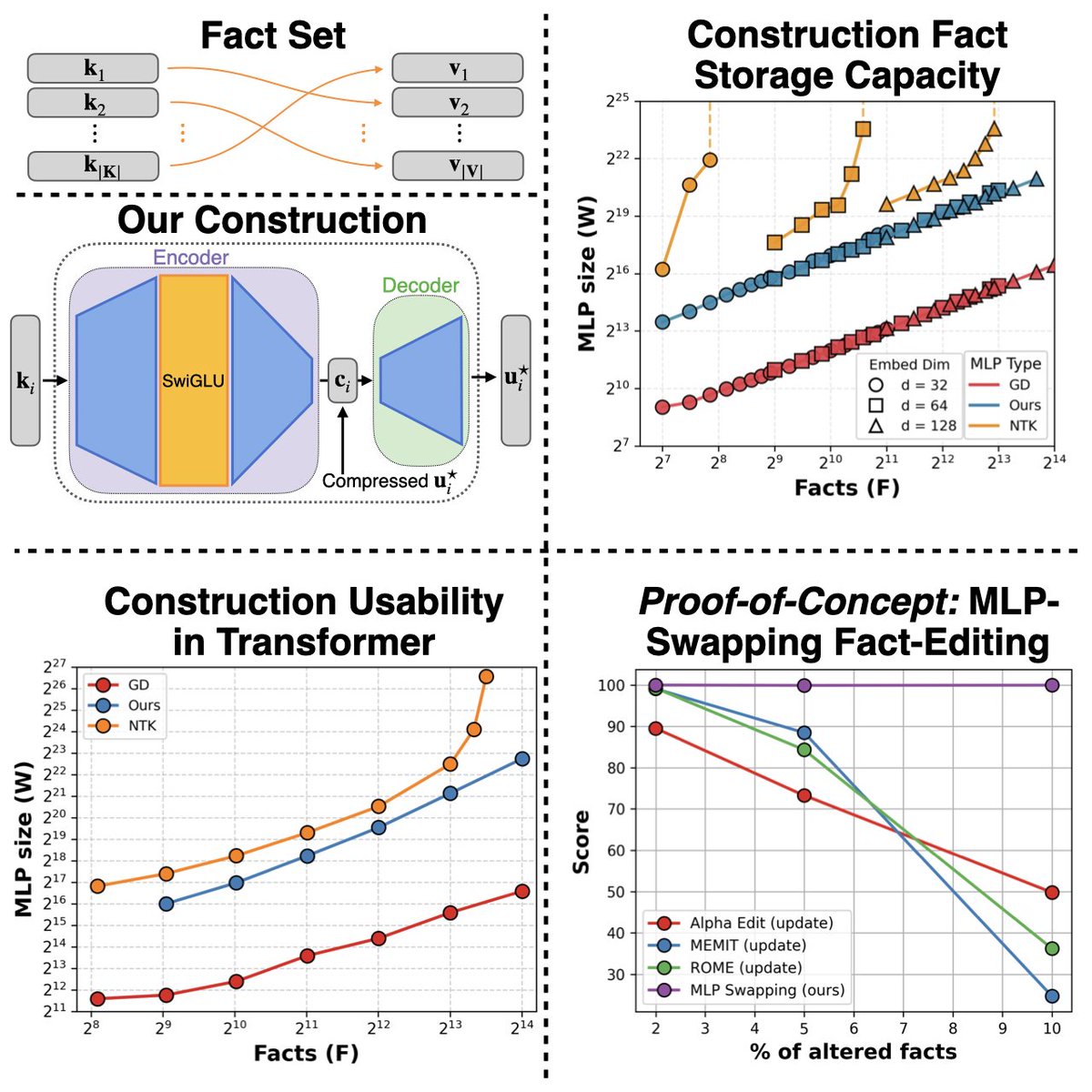
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔
Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩
New work with @garctrob@ronnygjunkins@jerrywliu@dylan_zinsley@EyubogluSabri Atri Rudra @HazyResearch!
🧵👇
Super excited for ParallelKittens led by @stuart_sul! From the Nvidia A100 to the B200, BF16 tensor core performance improved by 7.2× and High Bandwidth Memory bandwidth by 5.1×, while intra-node communication (NVLink) improved by only 3× and inter-node (PCIe/InfiniBand) by just 2×. PK helps with multi-gpu kernels!
(1/6) GPU networking is the remaining AI efficiency bottleneck, and the underlying hardware is changing fast! We’re happy to release ParallelKittens, an update to ThunderKittens that lets you easily write fast computation-communication overlapped multi-GPU kernels, along with new kernels for data, tensor, sequence, and expert parallelism!
Here’s a photo of overlapped kittens, along with things you should care about when optimizing multi-GPU kernels.
(With @simran_s_arora, @bfspector, and @hazyresearch. Generously supported by @cursor_ai and @togethercompute)
AI is compute-hungry. While it has generally relied on a single hardware vendor in the past, AMD GPUs now offer competitive memory and compute throughput. Yet, the software stack is brittle.
So we ask: can the same DSL principles that simplified NVIDIA kernel dev translate to AMD? We’re excited to introduce the newest addition to the ThunderKittens cinematic universe of kernel DSLs: HipKittens (HK) 🚀for Fast and Furious AMD kernels.
@TDevilfish Dynamic reg alloc will probably enable wave specialization to be more of a thing then! Curious about how the matrix layouts and memory access patterns for wave32 mode will differ too.
AI is compute hungry, so the @HazyResearch team at @Stanford asked: How do we build AI from the hardware up? How do we lead developers to do what the hardware prefers?
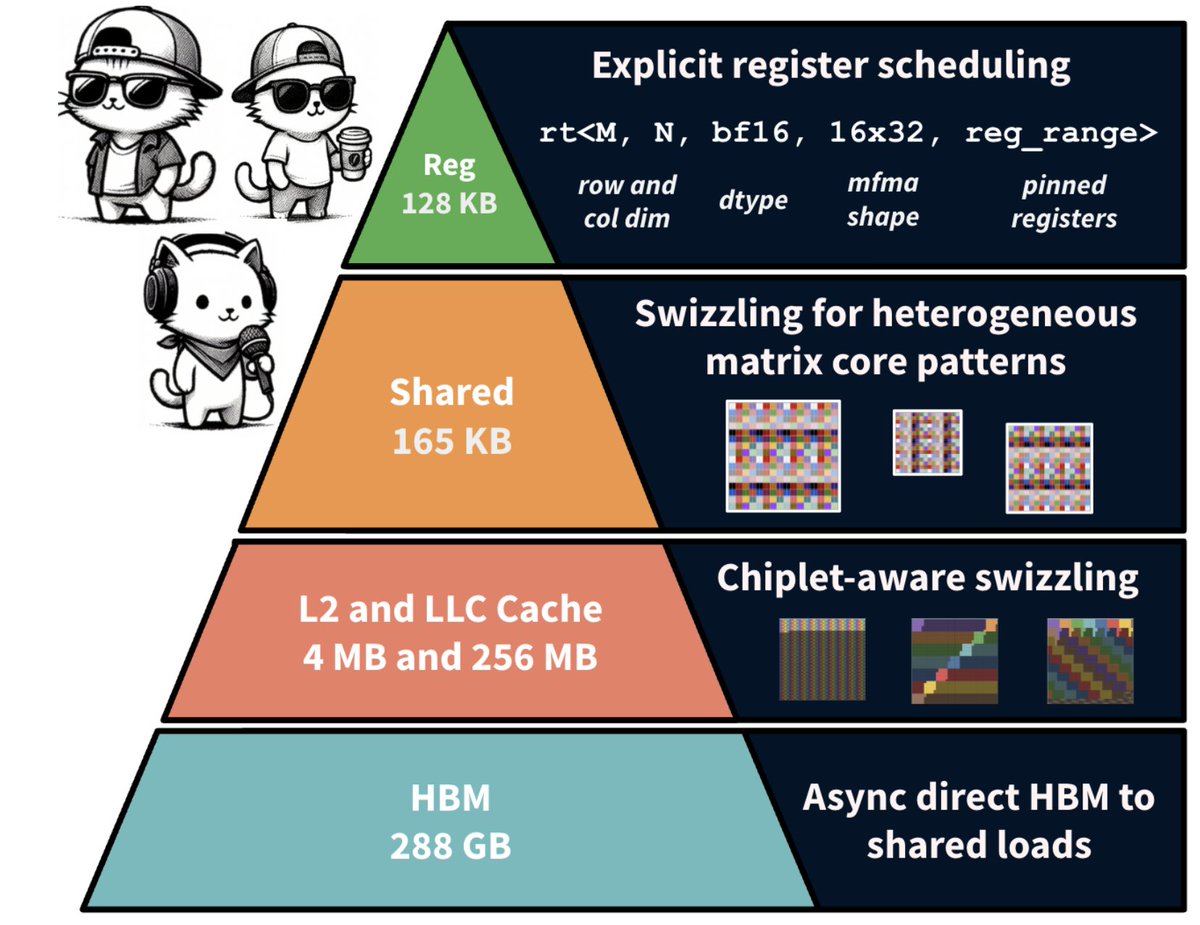
This technical deep dive on HipKittens explores how optimized register tiles, wave-level scheduling, and chiplet-aware cache reuse help unlock the full potential of AMD GPUs.
🐱 Dig into the details: https://t.co/lw4cw4YZgh
#AMDevs
HipKittens is here.
A new stack of fast, readable AMD GPU kernels built for real performance and real developer velocity.
Check it out on the @HazyResearch blog: https://t.co/zoeAB7Ujfs
#AMDevs
Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands?
The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW): intelligence delivered (capabilities) per unit of power consumed (efficiency).
Today’s Local LMs already handle 88.7% of single-turn chat and reasoning queries, with local IPW improving 5.3× in 2 years—driven by better models (3.2×) and better accelerators (1.7×).
As local IPW improves, a meaningful fraction of workloads can shift from centralized infrastructure to local compute, with IPW serving as the critical metric for tracking this transition.
(1/N)
Stanford used to be an NVIDIA stronghold, it even has a building named after Jensen, the Jen-Hsun Huang Engineering Center. But it seems AMD is starting to gain traction in Stanford’s research labs now, with experimental ROCm support in ThunderKittens. NVIDIA will need to contribute more compute to Stanford research if it wants Stanford to remain an NVIDIA stronghold.