Day 83/365 of GPU Programming
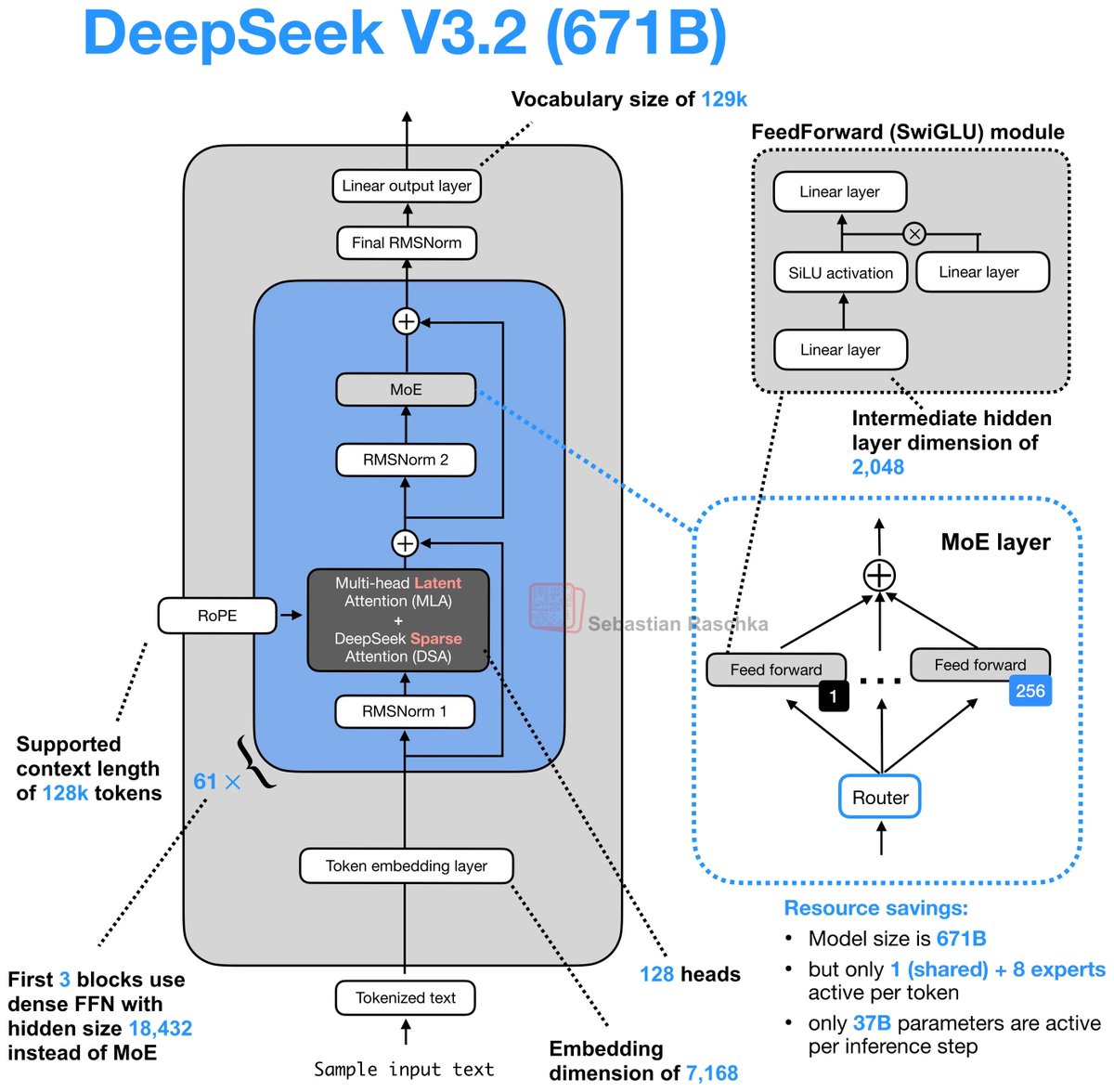
Looking at DeepSeek's Multi-Head Latent Attention today. The last part of the AMD challenge series is to optimize an MLA decode kernel for MI355X where the absorbed Q and compressed KV cache are given and your task is to do the attention computation.
A resource that really helped internalize what MLA does was @rasbt's incredible visual guide to attention variants in LLMs (luckily he posted that last week!), which covers everything from MHA to GQA to MLA to SWA, et cetera. If there's one place to get a visual intuition for recent attention mechanisms, it's this blog post.
@jbhuang0604's video on MQA, GQA,MLA and DSA was the best conceptual intro I found on the topic and progressively builds up the ideas from first principles.
The Welch Labs analysis of MLA is a great watch as well. Beautiful visualization of the changes DeepSeek made for MLA.
Tried out a few kernels once I had a basic understanding of MLA and I think I'm slowly getting more comfortable with at least analyzing kernels.
Day 82/365 of GPU Programming
Taking a closer look at Mixture of Experts today, so I can write better MoE kernels. Specifically, to optimize an MXFP4 MoE fused kernel for the GPU Mode challenge.
I haven't had much prior exposure to MoEs, so lots of new concepts I learned today. Luckily I found the best intro to MoEs thanks to @MaartenGr visual overview of the topic.
I then watched @tatsu_hashimoto's amazing Stanford CS336 lecture on MoEs, which added deeper context around why MoEs are gaining popularity, FLOPs, OLMoE, infra complexity, routing functions (mindblown this works so well...), expert sizes, training objectives, top k routing and DeepSeek variations.
Once I had a basic understanding I started playing around with the some AITER kernels but progress there is tbd.
Also had a nice chat with @juscallmevyom (who was kind enough to reach out!) about the AMD kernels and the challenge of materialization overhead.
151/365 of GPU Programming
Finishing up edits and running a few followup experiments the next few days to see if I can extend the workshop idea to a more general setting that would be practically useful + viable for a full conference paper.
Been also playing around with switching back and forth between smaller local experiments and scaling to larger GPUs via services like @modal and @runpod (also want to try @fal). Super convenient I have to say but can also get quite expensive quickly, so always need to double check whether a job I'm sending off is really worth it.
150/365 of GPU Programming
Doing a review of my workshop paper today and going through a few edits for the camera ready version, so it's in good shape by the deadline.
On that note, I really enjoyed @srush_nlp's talk on How to Write an okay Research Paper . A nice, pragmatic intro to ok paper writing that makes the most of the space you have available inside the page limit.
Really recommend giving it a watch if you're new to research like me.
150/365 of GPU Programming
Doing a review of my workshop paper today and going through a few edits for the camera ready version, so it's in good shape by the deadline.
On that note, I really enjoyed @srush_nlp's talk on How to Write an okay Research Paper . A nice, pragmatic intro to ok paper writing that makes the most of the space you have available inside the page limit.
Really recommend giving it a watch if you're new to research like me.
149/365 of GPU Programming
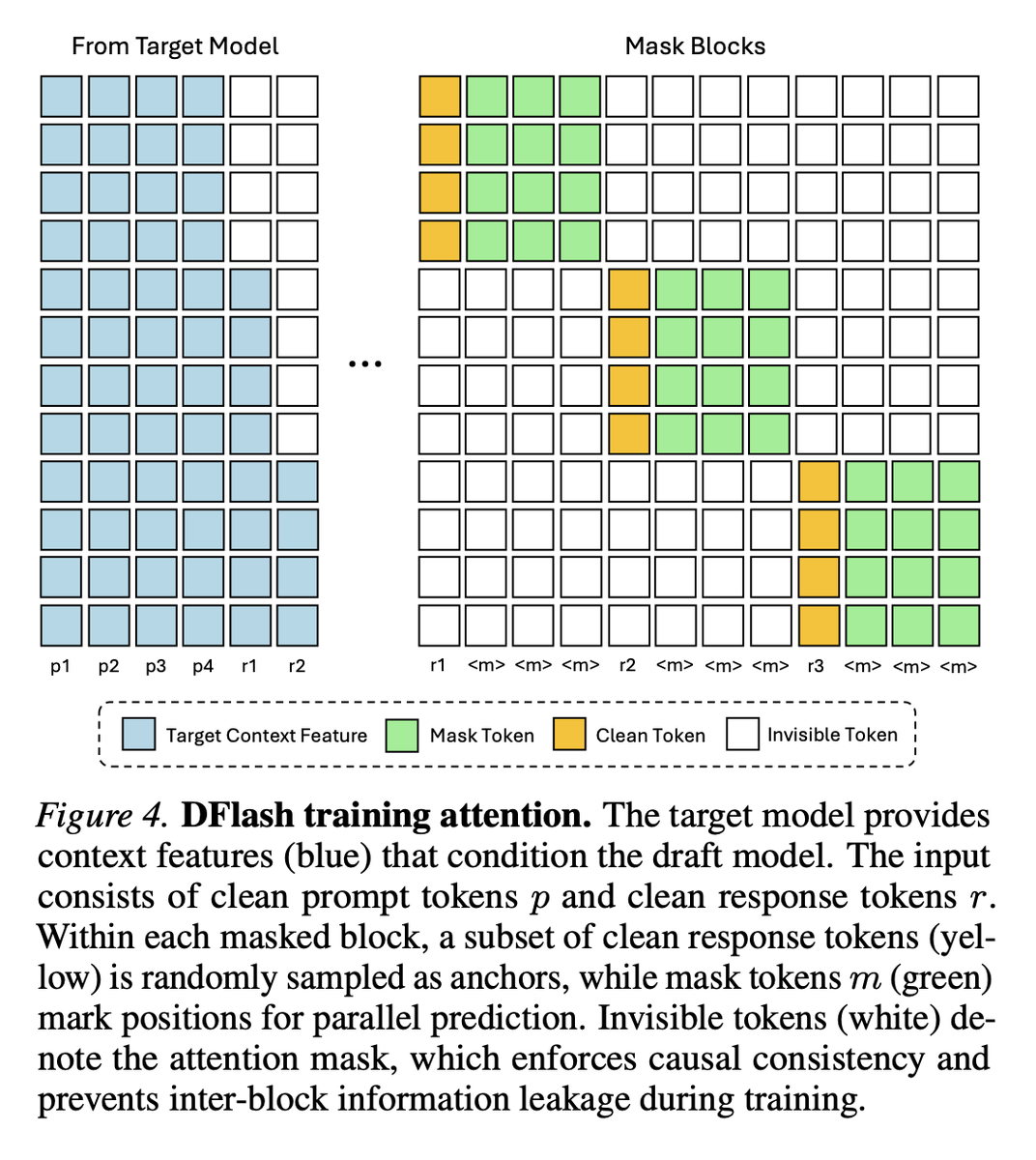
Been seeing a lot of people talking DFlash recently, so wanted to spend time today learning more about what it is.
Luckily stumbled across Eleuther's ML Performance Reading group (organized by @vega_myhre), which had a nice introduction to the topic.
While reading the paper, I'm also trying to see how I can pair DFlash with the local inference optimizations I'm experimenting with recently.
149/365 of GPU Programming
Been seeing a lot of people talking DFlash recently, so wanted to spend time today learning more about what it is.
Luckily stumbled across Eleuther's ML Performance Reading group (organized by @vega_myhre), which had a nice introduction to the topic.
While reading the paper, I'm also trying to see how I can pair DFlash with the local inference optimizations I'm experimenting with recently.
148/365 of GPU Programming
Going through the scaling law lecture of CS336 today and I find it more dense than previous materials. Will need to spend some additional time over the next few days reviewing the resources from the slides and attached papers to get more comfortable with the topic.
I'm starting to understand what scaling laws are and why they're useful w.r.t compute/data but still trying to get how critical batch sizes, muP, model-data joint errors, etc are derived, the primary differences between Kaplan vs Chinchilla and train-optimal vs inference-optimal.
One nice thing about this particular lecture is that it doesn't just cover the recent scaling law papers but also goes back to the early history of scaling laws like Cortes et al 1991, Branko and Brill '01, and so on.
New devlog post from yours truly: When does fragmentation occur in the CUDA caching allocator? https://t.co/ocAdv4mjy2 -- this post is LLM authored but I heavily prompted/edited, and Natalia also helped fact check.
@vega_myhre - Link to ML performance reading group recoding: https://t.co/Mazl2ssoKw
- Link to paper: https://t.co/fy2BqXHajw
- Link to repo: https://t.co/rW5ndUtlmT
- Link to blog: https://t.co/sIVvDHn9Cy
148/365 of GPU Programming
Going through the scaling law lecture of CS336 today and I find it more dense than previous materials. Will need to spend some additional time over the next few days reviewing the resources from the slides and attached papers to get more comfortable with the topic.
I'm starting to understand what scaling laws are and why they're useful w.r.t compute/data but still trying to get how critical batch sizes, muP, model-data joint errors, etc are derived, the primary differences between Kaplan vs Chinchilla and train-optimal vs inference-optimal.
One nice thing about this particular lecture is that it doesn't just cover the recent scaling law papers but also goes back to the early history of scaling laws like Cortes et al 1991, Branko and Brill '01, and so on.
147/365 of GPU Programming
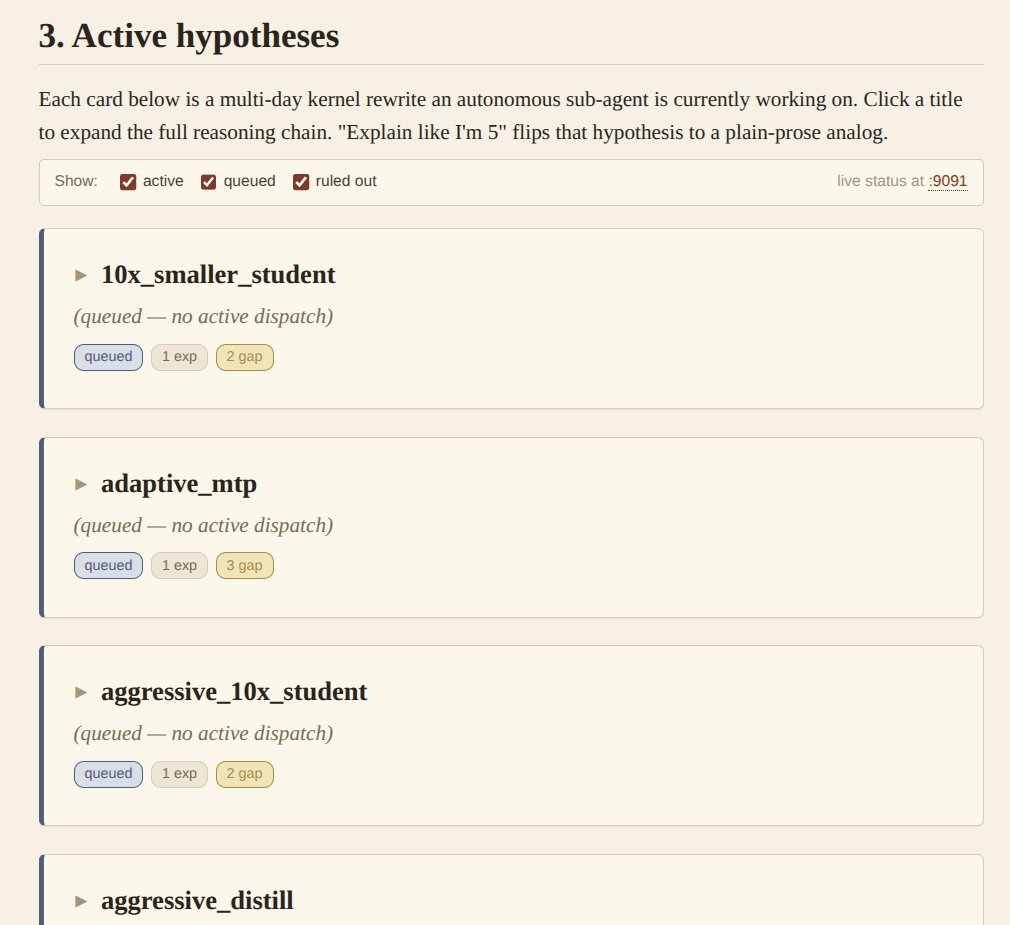
Iterating on my auto inference dashboard and adding a few functionalities that have helped me get a better intuition for what is being tested and why.
Added a knowledge graph that connects experiments with learnings, a live queue that reorders based on incoming data and provides context around future experiments and active hypotheses with summaries on what is currently being validated vs ruled out.
From there, I find it much easier to dive deeper into specific hypotheses/experiments and helps not getting lost w.r.t where the system is and what it's converging on.
147/365 of GPU Programming
Iterating on my auto inference dashboard and adding a few functionalities that have helped me get a better intuition for what is being tested and why.
Added a knowledge graph that connects experiments with learnings, a live queue that reorders based on incoming data and provides context around future experiments and active hypotheses with summaries on what is currently being validated vs ruled out.
From there, I find it much easier to dive deeper into specific hypotheses/experiments and helps not getting lost w.r.t where the system is and what it's converging on.
146/365 of GPU Programming
Happy Friday! Excited to run some experiments today and catch up on CS336 over the weekend.
Speaking of, lecture 8 is so so good. Such a nice continuation of lecture 7. Those two are probably my favorite lectures I've watched this year.
By far the best resource on parallelism I've come across so far. Lecture 7 setting the foundations from first principles and lecture 8 diving into the details of ZeRO stages 1/2/3, zero bubble pipelining, tensor parallelism, expert parallelism, context parallelism and how they're applied in Nemotron 3, DeepSeek V3, Llama 3, Gemma 2, Mixtra 8x22b, Qwen 3, etc
I have such a deep admiration for Percy's and Tatsu's teaching style, I really hope they continue to share their course materially publicly.
146/365 of GPU Programming
Happy Friday! Excited to run some experiments today and catch up on CS336 over the weekend.
Speaking of, lecture 8 is so so good. Such a nice continuation of lecture 7. Those two are probably my favorite lectures I've watched this year.
By far the best resource on parallelism I've come across so far. Lecture 7 setting the foundations from first principles and lecture 8 diving into the details of ZeRO stages 1/2/3, zero bubble pipelining, tensor parallelism, expert parallelism, context parallelism and how they're applied in Nemotron 3, DeepSeek V3, Llama 3, Gemma 2, Mixtra 8x22b, Qwen 3, etc
I have such a deep admiration for Percy's and Tatsu's teaching style, I really hope they continue to share their course materially publicly.
145/365 of GPU Programming
A few additional resources that are helping me get a better sense of ML research as a process and what "taste" might mean when people talk about problem selection:
-https://t.co/hV19P3dEtX by Bill Freeman
- https://t.co/s6rRrJLcTd by @tomssilver
- https://t.co/dmvozUfqgg by @johnschulman2
- https://t.co/FONXA8Gq1f by @MarekRei
- https://t.co/sGFfKcg3Sl by @seb_ruder
- https://t.co/hzzGBiGkF4 by @LouisKirschAI
- https://t.co/Gc9GC3R8yd by @ericjang11
- https://t.co/X3FT1gs5Sw by @ch402
Some of these go back over a decade but I think are just as relevant today. I can't say I have any research taste yet or know what good ML research is yet but these blog posts have been really helpful in understanding the perspective of how great researchers select what to work on a bit better.
145/365 of GPU Programming
A few additional resources that are helping me get a better sense of ML research as a process and what "taste" might mean when people talk about problem selection:
-https://t.co/hV19P3dEtX by Bill Freeman
- https://t.co/s6rRrJLcTd by @tomssilver
- https://t.co/dmvozUfqgg by @johnschulman2
- https://t.co/FONXA8Gq1f by @MarekRei
- https://t.co/sGFfKcg3Sl by @seb_ruder
- https://t.co/hzzGBiGkF4 by @LouisKirschAI
- https://t.co/Gc9GC3R8yd by @ericjang11
- https://t.co/X3FT1gs5Sw by @ch402
Some of these go back over a decade but I think are just as relevant today. I can't say I have any research taste yet or know what good ML research is yet but these blog posts have been really helpful in understanding the perspective of how great researchers select what to work on a bit better.
144/365 of GPU Programming
Trying to learn more about what good ML research looks like and how it's conducted.
One of the most helpful things so far has been online "shadowing" actual researchers.
Highly recommend watching @NeelNanda5 vibe research for a couple hours with Cursor or tuning into one of @jsuarez 5h livestreams. Even though neither RL nor MechInterp are areas I'm studying, it's been super helpful seeing what their process is like and how they think about problems.
I wish more researchers did livestreams like that. Especially in times where more and more of the process seems to be automated and it becomes a question of problem selection, steering and verification.
144/365 of GPU Programming
Trying to learn more about what good ML research looks like and how it's conducted.
One of the most helpful things so far has been online "shadowing" actual researchers.
Highly recommend watching @NeelNanda5 vibe research for a couple hours with Cursor or tuning into one of @jsuarez 5h livestreams. Even though neither RL nor MechInterp are areas I'm studying, it's been super helpful seeing what their process is like and how they think about problems.
I wish more researchers did livestreams like that. Especially in times where more and more of the process seems to be automated and it becomes a question of problem selection, steering and verification.
143/365 of GPU Programming
Working on my GPU agent dashboard setup today.
A few features that have been really helpful so far are a live view of GPUs and their states/utilizations, a quick overview section of current/future/past experiments with easy access to summary stats + descriptions of what was run alongside hypotheses and rationale for these experiments, a running log of things happening (whether queueing experiments or coding work).
Definitely still quite bare bones but already been quite helpful in the way I approach this whole workflow and what I learn from it along the way rather than just being a passive observant without insight into what's actually being tested and run.
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: https://t.co/P31SGl0cyT
Code: https://t.co/9nkO2hmeOl