The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
Say hi to @OpenJarvisAI 👋
If you have issues, want to make a PR, or simply chat, just @OpenJarvisAI in a tweet!
This account is itself an OpenJarvis instance: running 24/7 on an NVIDIA DGX Spark, triaging issues + PRs on the repo and serving as a personal assistant for the lab!
For personal AI on personal devices, checkout: https://t.co/40LjG2h0AR
https://t.co/Dn2v4g2MbR
📢 Super excited to announce Parcae! We've been thinking about scaling laws and the "right" way to get more FLOPs.
Turns out layer looping - with the right parameterization - gives you a new axis to scale!
Parcae matches Transformers 2x their size (w/ the same data), and outperforms prior formulations of looped models.
But - you need the right parameterization to get these gains against strong Transformer baselines. Looped models are famously unstable to train, with tons of loss spikes and hyperparameter sensitivity.
The main technical challenge with looped models is residual explosion - if you're passing the activations through the same layers over and over, some otherwise benign parameterizations cause huge instability.
Our key idea: we can think of the residual stream of a model as a time-varying dynamical system - the same fundamentals behind SSMs like Mamba and S4. Then a few modest modifications to classic Transformers (stable diagonalization of injection params, LN before embeddings) can stabilize the looped models. The resulting models are more stable to train, but also reach higher quality.
It's strong enough to start to derive new scaling laws. Classically - we know you need to scale parameters with data to be FLOP-optimal. With Parcae, we find a third axis - given fixed parameters, you additionally want to scale FLOPs by looping as you scale data.
Super excited to see how these ideas hold, and what we can do with looped models!
Check out @hayden_prairie's great explainer thread below, and see links for our paper, blog, and models. Joint w/ @zacknovack and @BergKirkpatrick, and a fun collab between @togethercompute and my lab at @ucsd_cse. Enjoy!
I wrote a blogpost about writing machine learning research papers (e.g., NeurIPS, ICML, ICLR, etc.). The core idea is that most papers follow one of a predetermined set of templates. The post talks about each template, describes their rules, and offers examples...
Personal AI should run on your personal devices. So, we built OpenJarvis: a personal AI that lives, learns, and works on-device.
Try it today and top the OpenJarvis Leaderboard for a chance to win a Mac Mini!
Collab w/ @Avanika15, John Hennessy, @HazyResearch, and @Azaliamirh. Details in thread.
(1/7) We're releasing ThunderKittens 2.0! Faster kernels, cleaner code, industry contributions, and new state-of-the-art BF16 / MXFP8 / NVFP4 GEMMs that match or surpass cuBLAS!
Alongside this release, we’re equally excited to share some insights we learned while squeezing every last TFLOP out of Blackwell:
(with @hazyresearch & generously supported by @cursor_ai)
Announcing Flapping Airplanes!
We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet.
Holiday read from @HazyResearch 🎄:
How should you mix and match LLMs in an agentic system? How many bits of information about the context does an agent carry?
We use information theory to understand how to choose and scale these models.
Really enjoyed our conversation with @alex_damian_ , check it out! Lots of interesting thoughts about the role of theory in modern ML and what questions to explore next.
🎙️ First time doing this 🙂 — I filled in for François on a one-off podcast episode with @alex_damian_ and @jerrywliu!
We had a really fun, wide-ranging conversation about AI, theory, and how research actually gets done.
Watch here 👇
https://t.co/vo6zX5nlFN
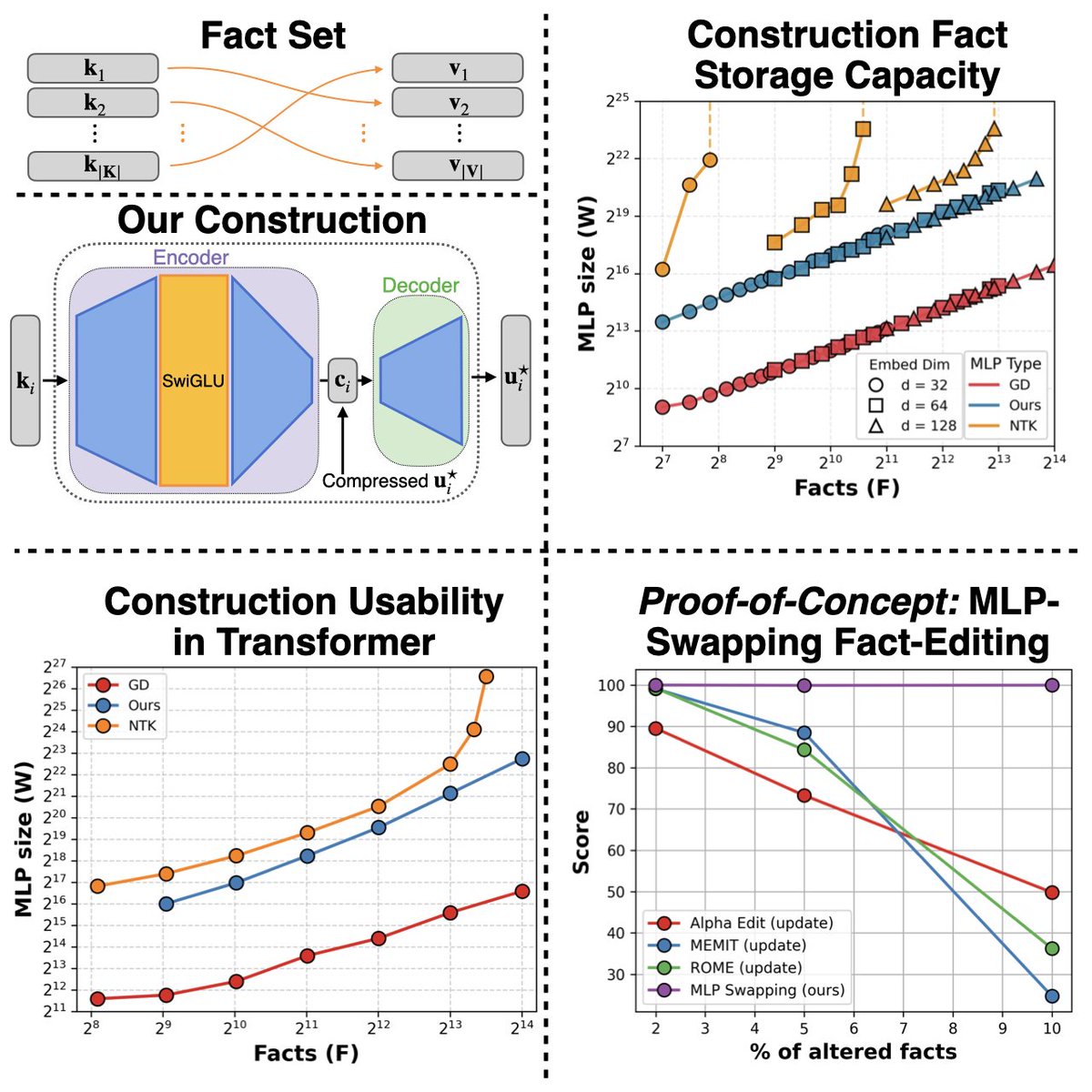
We explicitly construct MLPs that implement key–value fact mappings and, as a proof-of-concept, demonstrate modular fact editing inside a 1-layer transformer. (Joint work with @OwenDugan, @garctrob, @ronnygjunkins and team!)
https://t.co/b8YzumU97H
Curious how to cook up your own fact-storing MLPs? We wrote up a simple recipe… just in time for the holiday season 🎁👨🍳✨🧠 Check it out!
I’ll be at NeurIPS this week — happy to talk about MLPs & more!
Part 2 of our MLPs blog post is out! 👀
This time, we’re here to tell you the story 📖 of our quest for a construction that:
✅ Handles general embeddings 🌐
✅ Asymptotically matches the information-theoretic limit 📊📈
✅ Is usable within transformers 🤖✨
Very excited to introduce our fact-storing MLP construction and the insights we learned from it and from plugging it into a Transformer block! Really fun work with an amazing team 🙌.
Can’t wait to see the new directions this could unlock: can MLP constructions help us pack more knowledge into smaller models or speed up pre-training and inference in LLMs?
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔
Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩
New work with @garctrob@ronnygjunkins@jerrywliu@dylan_zinsley@EyubogluSabri Atri Rudra @HazyResearch!
🧵👇
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔
Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩
New work with @garctrob@ronnygjunkins@jerrywliu@dylan_zinsley@EyubogluSabri Atri Rudra @HazyResearch!
🧵👇
The U.S.–China AI race won’t be decided by who builds the most datacenters, but by who deploys the most intelligence.
We call this Gross Domestic Intelligence (GDI): intelligence per watt × usable power.
If the U.S. activates its dense installed base of local AI accelerators in a hybrid local–cloud system, it could add ~30–40% inference capacity and ≈2-4× GDI for single-turn chat and reasoning queries without building any new datacenters or grid infrastructure.
Winning the GDI race means treating local compute as critical infrastructure and making hybrid inference the default.
(1/N)
Thrilled to have contributed to Olmo 3! The best fully open 32B model (data, training recipes, checkpoints and more!)
As an intern at AI2 these last 8 months, I’ve grown to deeply appreciate the careful science, iteration, and collaboration that go into models like this and have learned so much from the team. I am more optimistic than ever about the future of open-source and data-centric research right now.
My particular contribution was working on the Dolma 3 data mix 👩🍳 I was able to apply ideas from some of my earlier mixing work, explore new problem settings, and see firsthand the data challenges that arise when building datasets intended for real models at scale. More on this coming soon!