Data mixing - determining ratios across your training datasets - matters a lot for model quality. While building Olmo 3, we learned it’s hard to set up a method that finds a strong mix, and hard to maintain that mix as datasets change throughout development.
Introducing Olmix👇
happy to share another quality tech report w/ the wider research community 🫶
great read for ppl who want to see all the details for methods + infra for scaling up pretraining & RL, esp detailed discussion about data which is often kept vague by other labs
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
https://t.co/u09u2f7mmK
Using LoRAs for determining dataset mixture. For a continual training setup, when new datasets are introduced, it is possible to train LoRAs for them and combine them with a LoRA on previous datasets.
What is the right data mix, and how do we find it as the data keeps changing?
This is a core, unsolved problem in continual learning. To tackle it, we built a data mixing algo that works everywhere — pretraining, midtraining, instruction tuning
Introducing: On-Policy Mix
🧵1/6
Five years ago, I left a comfortable software engineering job in Big Tech to start a PhD. Last year, I left the PhD to join Datology. Both decisions confused the people around me, and honestly both decisions were about the same thing: I wanted to do research. Not research as in chasing paper deadlines and applying for fellowships / grants, but research in the truest sense of the word - sitting with unsolved, sometimes previously unheard-of problems, contextualizing them, formulating them, exploring solutions to them.
I'd had a taste of research in college, flitting between disciplines, but never found something I felt truly passionate about until I came across deep learning. A field mixing empiricism, mathematics, and real-world impact all seamlessly - it made research the most exciting thing I'd ever done in my life. So in 2022 I started my PhD hoping for the chance to explore uncharted frontiers. Three years and several papers at the standard prestigious ML conferences later, I had technically done research. But I still didn't feel like I'd ever had the freedom, support, and resources to explore new and exciting ideas.
This is what brought me to Datology as an intern last summer. A hope to do research in the true sense - explore new ideas, supported by my peers and leaders, unconstrained by resources. And of course, about the data. At the end of the summer, I took a risk and stayed, putting my PhD on hold.
Since then, I've been lucky enough to grow into leading multimodal data curation at DatologyAI, and with our team we've tackled every challenge possible: the engineering and optimizing of a VLM training stack we built from scratch; the at-times frustrating but ultimately rewarding deep refining of VLM evals in our work DatBench (link); and of course a lot of exhilarating new research on DATA CURATION. But more than anything, I felt like I finally got to do research!!
I'd like to specifically thank @arimorcos and @leavittron who entrusted me with this opportunity, empowered me to do the best work of my life (so far), and mentored me to grow not only as a researcher but also as a leader. And a huge thanks to the @datologyai team that made research feel FUN again.
Today, we're releasing 20/20 Vision Language Models: A Prescription for Better VLMs through Data Curation Alone. This is the culmination of the multimodal team at Datology's work over the past year.
At fixed architecture, recipe, and compute, varying only the pretraining data, we get +11.7pp at 2B across 20 public VLM benchmarks, beat InternVL3.5-2B by ~10pp at ~17x less training compute (without post-training), and hit near-frontier accuracy at 4B with 3.3x lower response FLOPs than Qwen3-VL-4B.
Take risks. Bet on yourself. I’m going to keep doing this. At least until my luck runs out :)
a 🧵
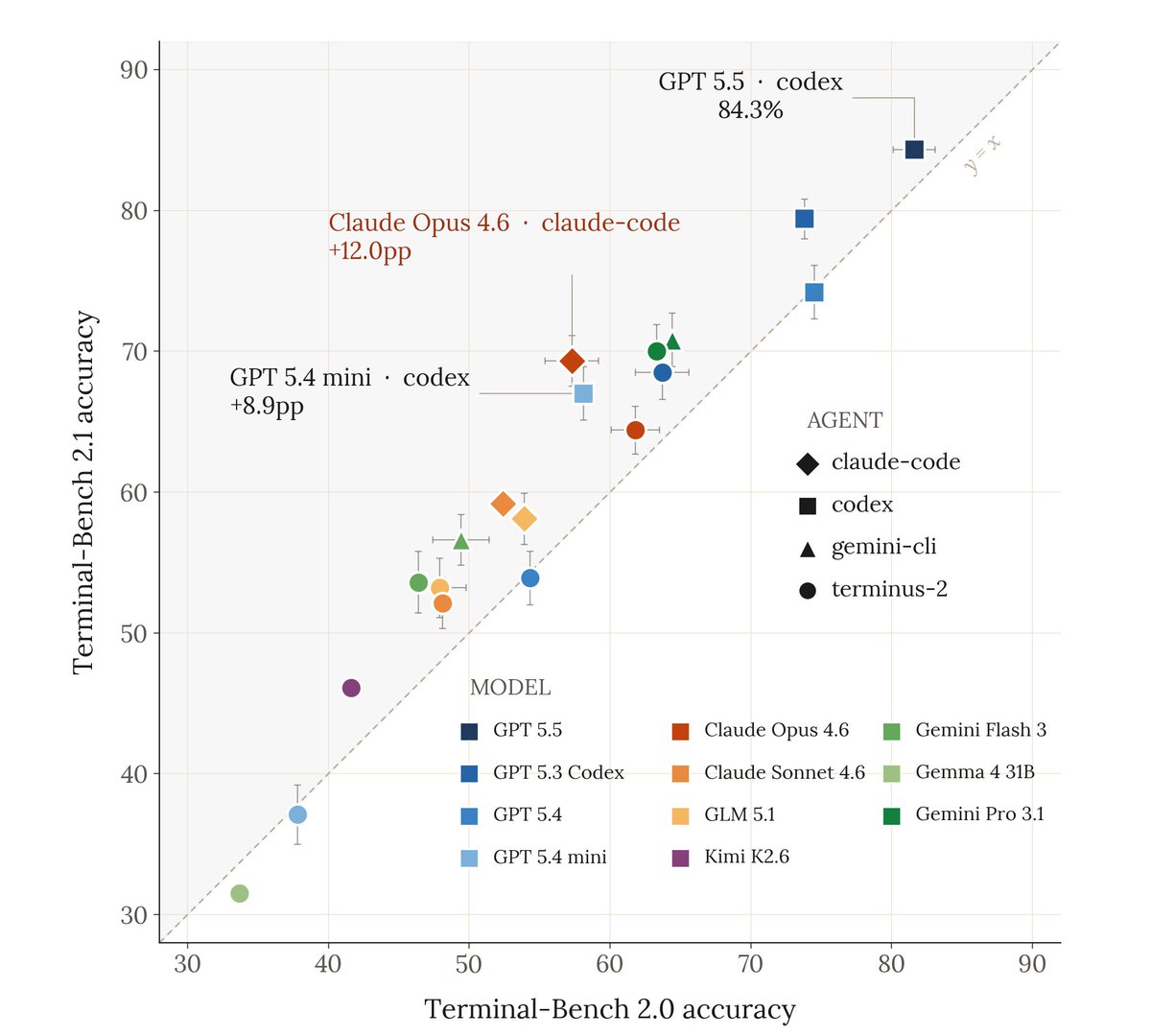
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
(1/5) Great to be at @sequoia to give a sneak peek of one of our research directions!
TL;DR one path to data-efficiency may be to “abuse GPUs like they’ve never been abused before”
Our thanks to everyone who came out to hear @MayeeChen dive into her paper "Olmix: A Framework for Data Mixing Throughout LM Development." ▶️ Replay ICYMI live: https://t.co/ycdzr0ghhm
We're presenting our paper at ICLR! 🇧🇷
Stop by if you want to chat about agentic systems, multi-model scaling, or want to grab acai with me! 🫐
🗓️ Sat, Apr 25, 3:15 PM – 5:45 PM
📷 Poster Session 3, Pavilion 3 P3-#903
I'm at ICLR presenting Olmix (oral) at the Data-FM workshop this Sunday, April 26 @ 10:30AM! DM me to chat about anything related to data and the model development process / try to find the best açaí + pão de queijo with me 😋
Data mixing - determining ratios across your training datasets - matters a lot for model quality. While building Olmo 3, we learned it’s hard to set up a method that finds a strong mix, and hard to maintain that mix as datasets change throughout development.
Introducing Olmix👇
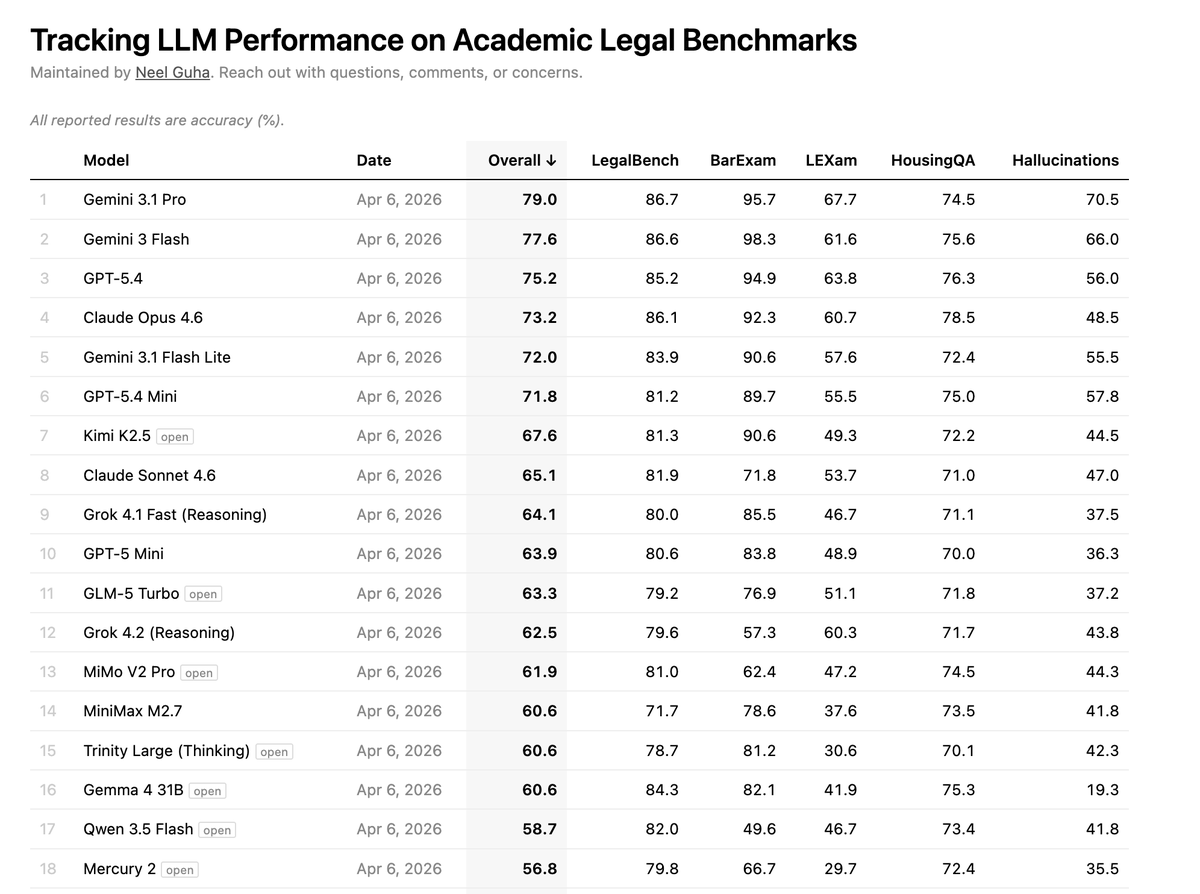
I built a leaderboard tracking LLM performance on a suite of academic legal benchmarks. This includes LegalBench, LEXAm, Housing QA, BarExam, and some Hallucination benchmarks.
Some fun findings:
That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n]
A few facts, while the dust is settling.
Ai2 still is...
- releasing open models, folks want to, and it's actually required in the NSF grant
- using substantial compute to do so from said grant
- funded additionally by FFST (new funding body) on top of NSF, for work in open models
Overall I'm confident in Ai2 doing great work this year.






























![nick11roberts's tweet photo. That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n] https://t.co/vj2CZ2GNoE](https://pbs.twimg.com/media/HFOWCzBW8AAr8bY.jpg)






























