If you're a startup building agentic products, your economics live and die on inference. An agent makes many model calls over a single long trajectory. For agents that reason at length or make many tool calls, those calls generate far more tokens than they read, and the cost of generating tokens is the part that scales hardest. Chain enough of those requests together and output token cost becomes the dominant term in your unit economics. Two things bring that cost down. The first is activating fewer parameters on each token. The second is keeping the memory cost of long context low. Nemotron 3 Ultra, released by NVIDIA today, does both. It is a Mixture-of-Experts model that activates 55B of its 550B parameters per token. Its hybrid Mamba-Attention design keeps the KV cache footprint bounded as context grows, where a standard attention model would see it grow with every token. At the 8K-in, 64K-out setting it runs close to six times the throughput of GLM-5.1 and almost five times Kimi K2.6, at on-par accuracy.
The second thing worth noting is how much NVIDIA open-sourced. The base, post-trained, and NVFP4 quantized checkpoints are all released, along with the training data, the recipe, and the RL environments. In practice this means you can self-host the model. You can run inference in the same FP4 precision it was trained in. You can modify the training pipeline rather than treating it as a black box behind an API. The model was also post-trained for agentic work specifically. That training covered terminal use, end-to-end GitHub issue resolution, and search agents that compress their own context to keep operating past the window limit. An efficient open model paired with a fully released training pipeline is rare, and it is what makes owning your own inference stack realistic rather than aspirational.
Today we're announcing that hybrid agentic inference is coming to Perplexity Computer.
Computer can split tasks between a local model running on your machine and frontier models in the cloud. This keeps private data on your device and maximizes token efficiency.
Coming soon.
I guess I'm commenting on your general stance that edge token generators will never be a thing in America, rooted in the opinion that Americans don't care where their data is held. I can tell you objectively that I speak to dozens of American AI workstation consumers every week who care deeply. I also think Americans care more given the "don't tread on me" values, distrust of a central authority holding your data is the same instinct.
@mweinbach@Midnight_Captl@benitoz You’re underestimating how much people care. iCloud and Google photos can’t be used as a generalization for people’s views on personal data governance. I talk to developers everyday who buy workstations for the sake of data governance.
1. This is a low friction way to get hands on with the full NVIDIA stack in a familiar form factor.
2. You can run Hermes Agent on device behind OpenShell and Microsoft’s new security primitives.
Introducing Surface Laptop Ultra.
Built for world makers. Designed for what's next.
The most powerful Surface laptop ever. Coming Fall 2026.
Sign up to learn more: https://t.co/k8aEX2pTAy
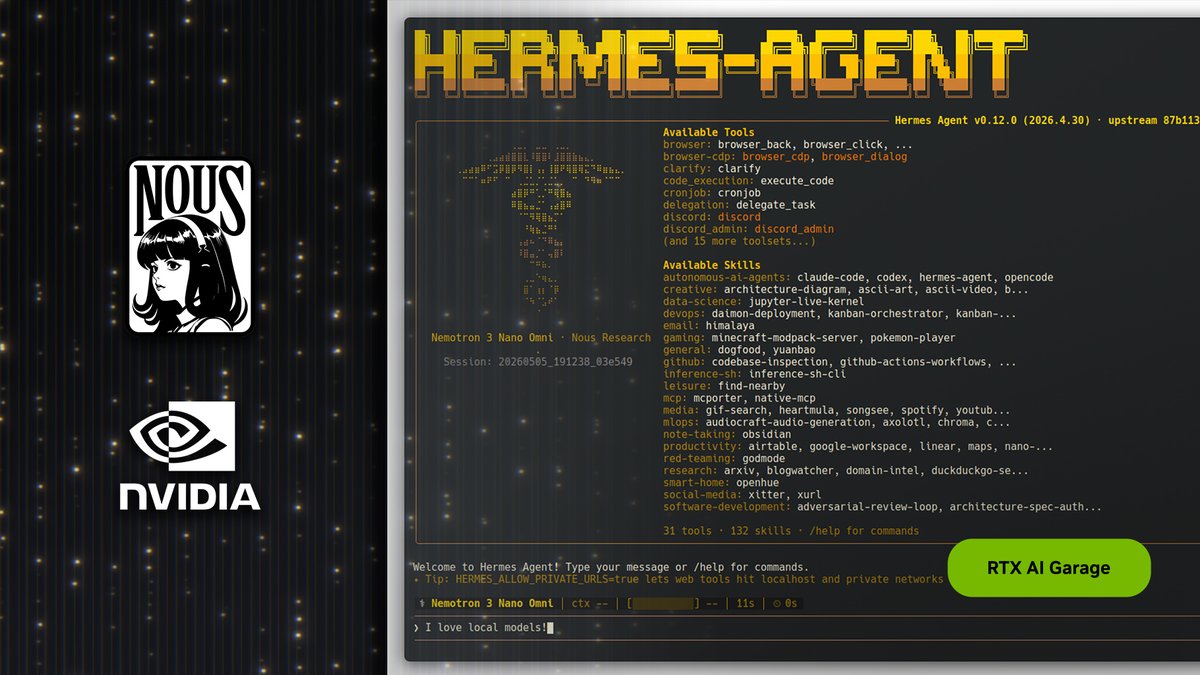
We have been working closely with @nvidia to ensure Hermes Agent works smoothly on their new @NVIDIARTXSpark superchip and integrates with the new OpenShell runtime, which connects Hermes to @Microsoft's security primitives.
Watch our feature in the big announcement at Computex:
AI is unlocking breakthroughs in quantum computing.
🤝 We collaborated with the University of Innsbruck to tackle a core challenge in building useful quantum supercomputers: automatically designing efficient quantum circuits.
Using NVIDIA CUDA-Q, we built a multimodal diffusion model to synthesize quantum circuits from scratch, optimizing circuit structure and gate parameters simultaneously to produce shorter, lower-error circuits.
💡 The standout result: the AI model independently rediscovered the Quantum Fourier Transform — without being told what the solution should look like.
🔗 Learn more: https://t.co/y0nh9i7Tiu
Run powerful, self-improving AI agents from your desk.
@NousResearch's Hermes Agent brings reliable, self-evolving agentic AI to NVIDIA RTX PCs and DGX Spark.
Get started. 👇