The industry has gone completely nuts.
Use tokens to generate AI code and documentation slop. Then use even more tokens to understand and review that slop.
Then judge engineers by token usage instead of how empathetic and clear their docs and code actually are, and completely neglect human comprehension.
Utter nonsense.
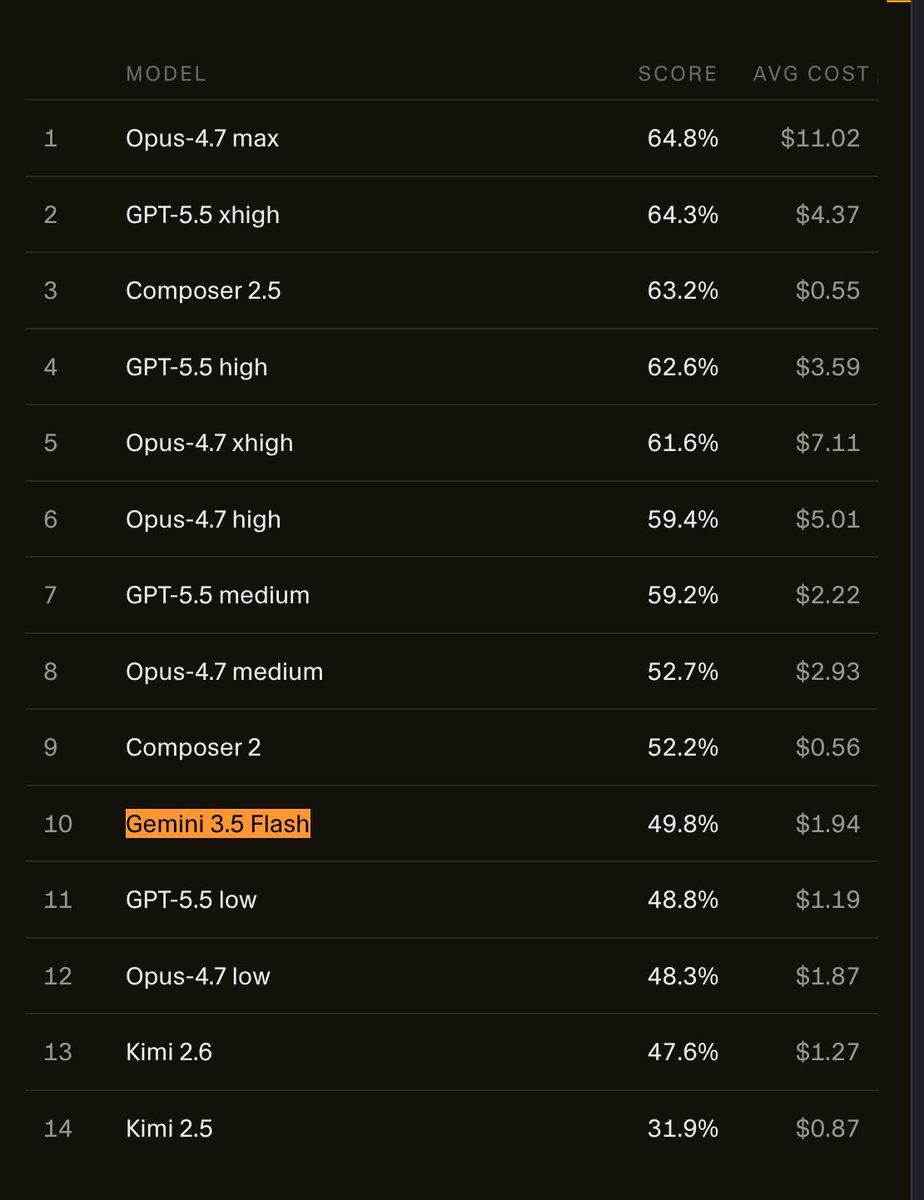
Oh my god it scored worse than Composer 2! Not even 2.5! And it cost 4x more to run!!!
This might be the worst major lab model drop of all time. Llama 4 tier. Insane.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Meet Gemini 3.5 Flash — our strongest agentic and coding model yet.
It delivers frontier-level performance at 4x the speed of comparable frontier models — often at less than half the cost.
Generally available, starting today. 🧵
#GoogleIO
After a very thorough 3 day full security sweep and hardening process, we'd like to issue an official all clear ✅ on TanStack repo and package security. Full details have been updated in our post-mortem and security followup blog (linked below).
TL;DR:
- Only the Router/Start repo was affected. 42 monorepo packages, 2 versions per package. These were promptly deprecated within the hour and removed by NPM shortly after
- All other repos and packages were unaffected and remain secure including: Query, DB, Store, AI, Table, Form, HotKeys, Virtual, Pacer, Config, Devtools, CLI, Intent, etc.
- All available and published versions of every TanStack package are safe to download, including TanStack Router/Start.
https://t.co/KQSXhUM4XM
https://t.co/mtN9hF5Ioy
One idea that’s helped me simplify code maintenance with AI is to spend more time in the Ask mode than in any other ones. Most people tend to tag errors and ask the agent to “fix it” and this is where your hold starts deteriorating.
I like to have a full chat about the issue and proposed fixes before the agent ever touches the code. Helps me understand the problem, evaluate approaches and plan out follow up tests.
Patience is key
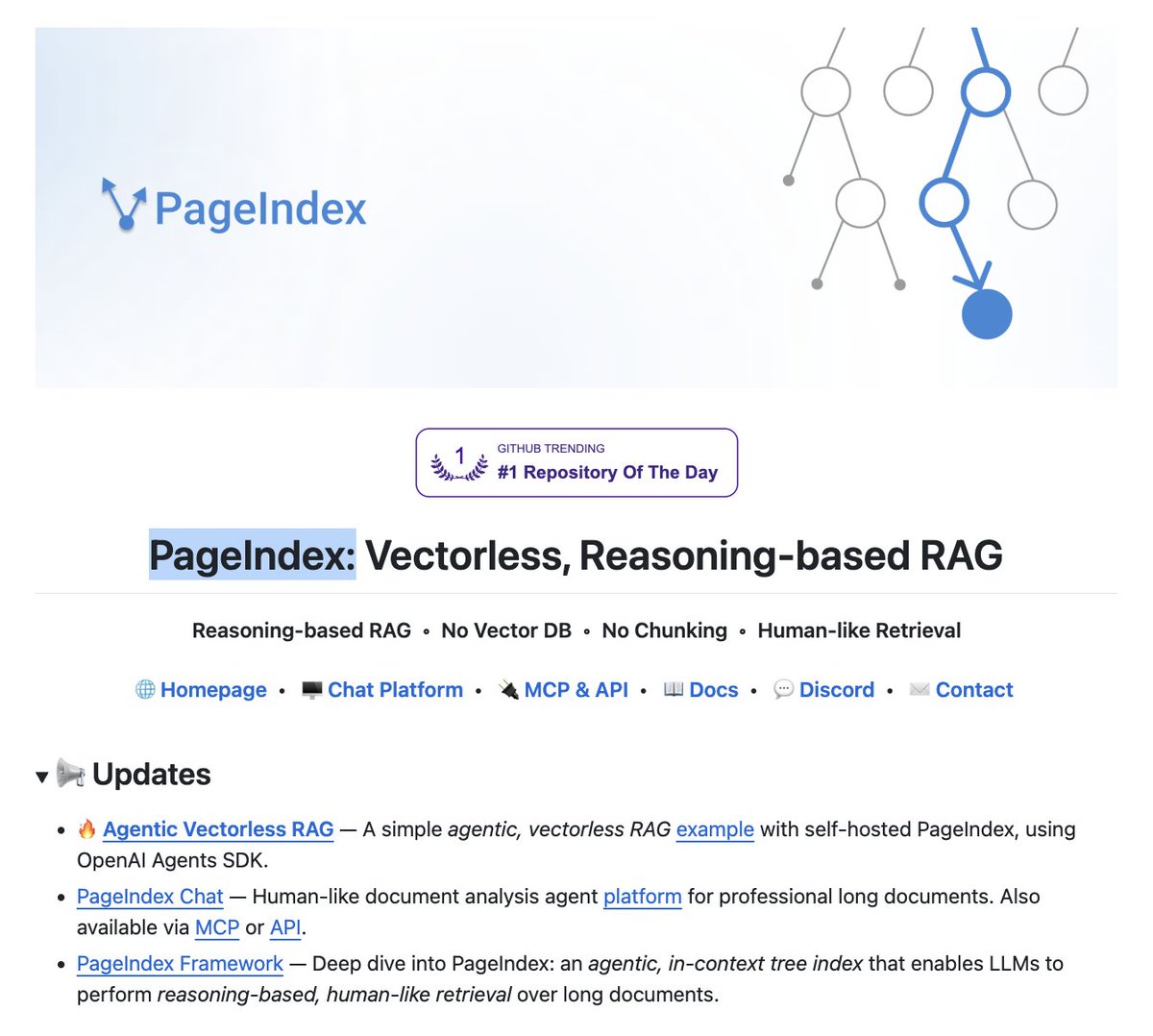
The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
Effective today, we are:
1) Doubling Claude Code’s 5-hour rate limits for Pro, Max, and Team plans;
2) Removing the peak hours limit reduction on Claude Code for Pro and Max plans; and
3) Substantially raising our API rate limits for Opus models.