@DamiDina@LunjunZhang He’s implying that alleged Chinese distillation of U.S. frontier models doesn’t just hurt American labs; it also subsidizes American startups that rely on strong Chinese open models. Stop that, and the moat around the U.S. giants gets much bigger.
something about RL companies I've always wondered:
isn't it the case that American RL companies are all structurally dependent on Chinese open-source models?
if "distillation attacks" were actually stopped, what would happen to American VC money that went into RL companies?
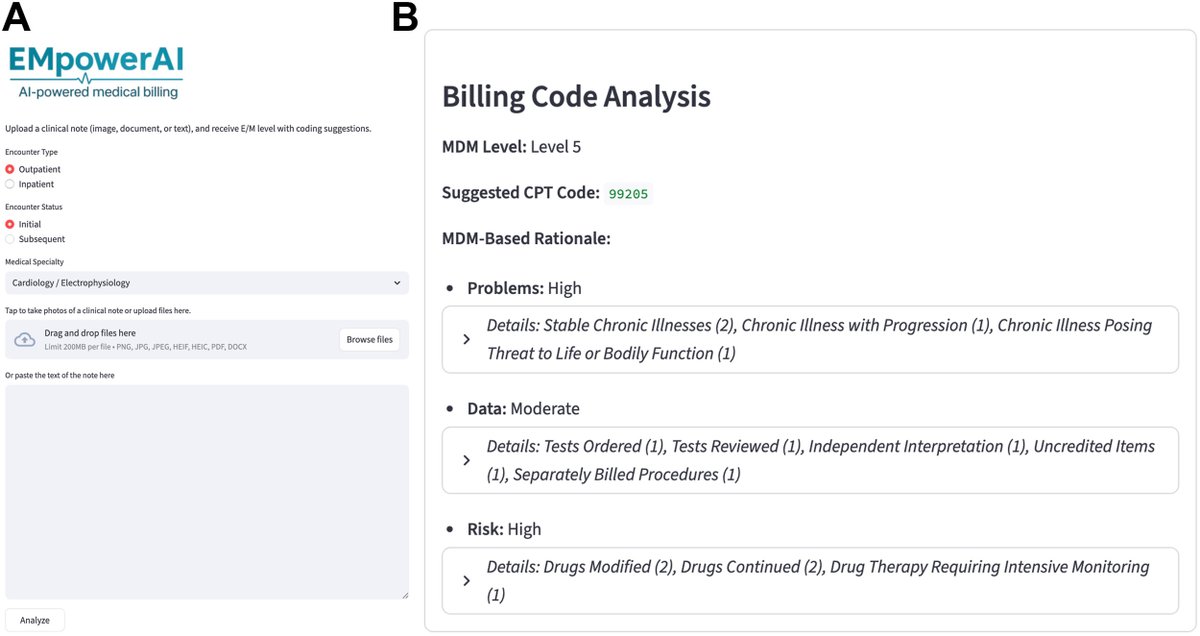
Identifying hidden medical complexity in cardiovascular care: A large language model approach to evaluation and management coding and documentation, by @VAbrich85 and Richard Abrich, MASc
@MercyOne_Iowa#EPeeps
https://t.co/om2i33Nic2
@AlchemyAmerican Very interesting claim. The next step is reproducibility.
Publish the processing pipeline, parameters, and benchmark results on known underground structures and null controls.
Let independent groups try to reproduce it.
OpenAI just revolutionized image generation, but that's just the beginning. The real game-changer? Visual reasoning is coming - where AI won't just manipulate images, but will actually think through problems using visual simulation.
This is even funnier. Codex will truncate any Bash/MCP tool output to 256 lines or 10kb. If the tool call outputs more than that, then the model only gets to see the first 128 lines, and the last 128 lines, but nothing in the middle.
Been like that since August. No wonder poor GPT is slow going in circles trying to understand WTF it's actually seeing.
@thinkymachines just got access to Tinker, thank you! I noticed that you expect to support image input in the future. Any idea on a rough timeline for image support?
@JasonNocco@aidanshandle@thinkymachines Hi @JasonNocco I'm also interested in fine tuning VLMs. I'm not able to DM you because I'm not verified. I believe you should be able to DM me, happy to share details about our use case.
This is a great example of a benchmark which fails the "what if you succeed?" test.
You can spend years creating new paradigms and academic subcultures to solve it, but at the end of the day, all you made is an algorithm that can do some symbol manipulation on some synthetic tasks.
Many papers will get written. Some symbol manipulator markov logic network contraption will probably solve this benchmark.
But no real progress will be made because this is some academic's conception of what general intelligence is, and is completely detached from real-world applications.
This is the same mistake the RL community made and suffered greatly by focussing on RL-from-scratch on simulations and video games. Do not make the same mistake again.
Got a 7,000% traffic spike yesterday. Turns out it was a bot network 'advertising' itself by spamming my analytics. You can even set your own bounce rate 😂 Growth hacking has gone full parody.