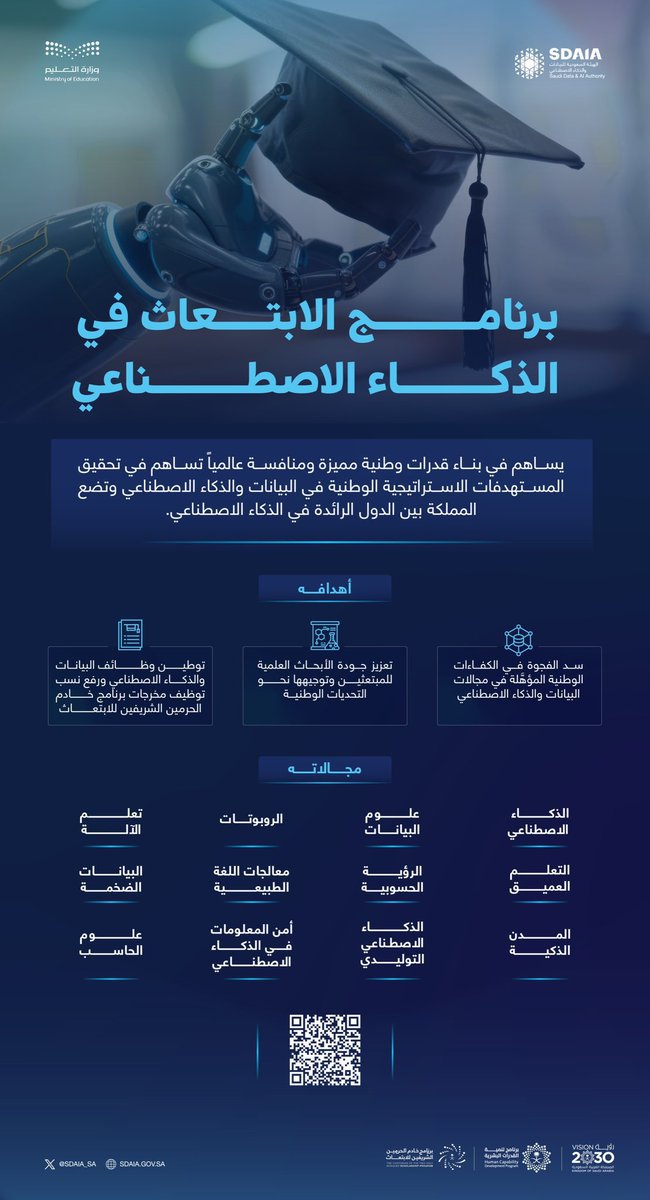
ابنك/ابنتك موهوب تقني؟
نسعد بإطلاق مدارس الموهوبين التقنية الثانوية في 5 مدن جديدة، لتصل إلى 10 مدن حتى الآن!
الأولى من نوعها في بناء قدرات الطلاب والطالبات في التقنيات المتقدمة!
الذكاء الاصطناعي والأمن السيبراني والميكاترونيكس وعلوم الحاسب
فُتح التسجيل الآن للصف الأول ثانوي في المدن التالية:
الرياض - جدة - الدمام - المدينة - القصيم
أبها - جازان - حائل - الأحساء - مكة المكرمة
بالشراكة بين وزارة التعليم وأكاديمية طويق
وبشراكة مع كبرى الشركات التقنية العالمية، في مقدمتها Google, Meta, Amazon, Apple وغيرها
للتسجيل:
https://t.co/XFIpf0dF3v
🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about.
Websites can already detect when an AI agent visits and serve it completely different content than humans see.
> Hidden instructions in HTML.
> Malicious commands in image pixels.
> Jailbreaks embedded in PDFs.
Your AI agent is being manipulated right now and you can't see it happening.
The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries.
23 different attack types. Frontier models including GPT-4o, Claude, and Gemini.
The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents.
Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work.
The results should alarm everyone building agentic systems.
The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels.
Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata.
Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models.
Malicious content in PDFs that appears as normal document text to the agent but contains override instructions.
QR codes that redirect agents to attacker-controlled content.
Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector.
The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings.
This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents.
A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see.
The agent cannot tell the user it was served different content.
It does not know. It processes whatever it receives and acts accordingly.
The attack categories and what they enable:
→ Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions
→ Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents
→ Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata
→ Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector
→ Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges
→ Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content
→ Memory poisoning: injecting false information into agent memory systems that persists across sessions
→ Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters
→ Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls
→ Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines
The defense landscape is the most sobering part of the report.
Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied.
You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time.
Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate.
Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate.
A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions.
The multi-agent cascade risk is where this becomes a systemic problem.
In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system.
Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B.
The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model.
It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions.
The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.
The US just updated their National Defense Authorization Act with new AI assessment frameworks for the Defense Department, including testing procedures and security requirements. Interesting read for the intersection of engineering and policy:
https://t.co/osyWMIQNv1
OpenAI, Google, and Anthropic just published guides on:
• Prompt engineering
• Building agents
• AI in business
• 601 AI use cases
9 of the best guides you can't miss:
أبشركم فتح الابتعاث في مجال الذكاء الاصطناعي بكالوريوس وماجستير ودكتوراه مقدم من (سدايا) والدول المتاحة للدراسة أمريكا وبريطانيا وأستراليا وكندا وفرنسا وسنغافورة واليابان والصين وغيرها
12 تخصص
29 جامعة
9 دول ..
للتسجيل والتفاصيل
https://t.co/EbHVd3uUXt
We invite you to join us shortly for the virtual session on Deepfake Technology, featuring distinguished guests of researchers and AI experts, aimed at enhancing knowledge of modern technologies and ethics.
https://t.co/Sh8qVe7wH3
The International Center for AI Research and Ethics (ICAIRE), in collaboration with @SDAIA_SA, is hosting a virtual session titled “Deepfake” during UNESCO’s Global Media and Information Literacy Week.
https://t.co/Sh8qVe7wH3
يمكنك متابعة كل جديد حول برنامج Google AI Pro ومستجدات أبحاث وأخلاقيات الذكاء الاصطناعي عبر متابعة حسابات المركز الدولي لأبحاث وأخلاقيات الذكاء الاصطناعي (ICAIRE)يمكنك متابعة كل جديد حول برنامج Google AI Pro ومستجدات أبحاث وأخلاقيات الذكاء الاصطناعي عبر متابعة حسابات المركز الدولي لأبحاث وأخلاقيات الذكاء الاصطناعي (ICAIRE)يمكنك متابعة كل جديد حول برنامج Google AI Pro ومستجدات أبحاث وأخلاقيات الذكاء الاصطناعي عبر متابعة حسابات المركز الدولي لأبحاث وأخلاقيات الذكاء الاصطناعي (ICAIRE).
(تغريدة طويلة جداً)
قبل شوي انتهيت من سماع هذا البودكاست الطويل، مدته ساعتين تقريباً، ورغم أني عانيت في فهم بعض أجزائه لكن بحاول قدر المستطاع هنا ألخص وأشرح أهم الأشياء اللي انذكرت فيه.
البودكاست مع واحد من أذكى الناس في مجال الذكاء الاصطناعي اليوم وهو أندريه كارباثي. المقابلة كانت عميقة ومليانة أفكار، ابتداءً من عنوان الحلقة الغريب "نحن نستحضر الأشباح، لا نبني الحيوانات". راح نرجع لمعنى هذا العنوان لاحقاً
بداية الحلقة كان يرد على الحماس الزائد اللي نشوفه في تويتر وغيره من المنصات على الناس اللي يقولون أن هذا عام وكلاء الذكاء الاصطناعي، وهنا يقول أن هذي الجملة استفزته لأن فيها مبالغة كبيرة في التوقعات.
برأيه، نحن نعيش في عقد وليس سنة وكلاء الذكاء الاصطناعي. وكلاء الذكاء الاصطناعي، عشان نفهم مقصده هنا، هي برامج ذكية تقدر تتصرف بالنيابة عنك، كأنها موظف أو متدرب شخصي. الفكرة صحيح موجودة حالياً والتطبيقات الأولية مبهرة، لكن الطريق لا يزال طويل جداً.
السبب كما ذكر "لأنها ببساطة ما تشتغل بشكل ممتاز حتى الآن". يقول تخيل إنك مدير شركة، هل تقدر اليوم توظف واحد من هذه الوكلاء وتعتمد عليه؟ أكيد لا. المشكلة إنهم يفتقرون للذكاء الكافي، وما يتعلمون باستمرار، يعني لو علمته شيء اليوم بينساه بكرا، وما عندهم قدرة يفهمون السياقات المعقدة. هذي المشاكل ما راح تنحل في سنة، راح تاخذ مننا عقد كامل من التطوير والبحث.
وهذا يأخذنا لفلسفته العميقة اللي لخصها عنوان الحلقة. كارباثي يشوف إن الطريقة اللي نبني فيها وكلاء الذكاء الاصطناعي أو نماذج الذكاء الاصطناعي عموماً اليوم مختلفة تماماً عن الطريقة اللي تطورت فيها الكائنات الحية. بعض الباحثين الكبار يؤمنون إن الطريق للذكاء الاصطناعي العام هو محاكاة الحيوانات، يعني نبني نظام يتعلم من الصفر بالتجربة والخطأ. لكن كارباثي يقول اللي قاعدين نسويه ما له أي علاقة بهذا الشيء. نحن ما نبني حيوانات، تحن "نستحضر أشباحاً".
اللي يقصده هو إن النماذج اللغوية الكبيرة اليوم هي تجميع وضغط هائل لكل المعرفة البشرية المكتوبة على الإنترنت. هي كأنها "شبح" أو "روح" جماعية للعقل البشري، تعلمت عن طريق تقليدنا ومحاكاة النصوص اللي كتبناها. هي كيانات رقمية بحتة.
بالمقابل، الحيوانات تطورت بطريقة مختلفة تماماً - ما راح أعلق على موضوع نظرية التطور لأنها خارج نطاق الأفكار اللي ألخصها هنا و أعرف أن كثير منا لا يؤمن بها أصلاً -. ضرب مثال جميل صراحةً، قال فكر في الحمار الوحشي. أول ما ينولد، خلال دقايق معدودة يقدر يوقف على رجليه ويركض ويتبع أمه. هذا سلوك معقد جداً ومستحيل يكون تعلمه في هذي الدقايق القليلة، بل هو مبرمج في "هاردوير" مخه، متوارث جينياً عبر ملايين السنين من التطور - أنا فقط أنقل كلامه عشان لا يجي أحد يؤول كلامي بشكل خاطئ -.
ويعترف إنه كان جزء من المحاولات الأولى اللي ما كانت دقيقة أو ناجحة. يقول في بدايات OpenAI، كان فيه توجه قوي لتجربة التعلم المعزز، لتعليم وكلاء أذكياء داخل بيئات مغلقة مثل ألعاب أتاري. كانت الفكرة إنك لو خليت النموذج يتعلم بنفسه من خلال اللعب، ممكن يوصل لذكاء حقيقي. لكن هذي كانت خطوة متسرعة. المشكلة إنهم حاولوا يبنون "العميل الذكي" من الصفر، بدون ما يكون عنده أي أساس معرفي. اللي اكتشفوه بعدين إنك لازم تبني أول شيء "القوة التمثيلية"، يعني نموذج لغوي ضخم يفهم العالم من خلال النصوص والبيانات، وبعدها تبني فوقه قدرات التفاعل واتخاذ القرار.
من هنا تجي مشكلة أعمق في النماذج الحالية، وهي الذاكرة المفرطة. كارباثي يقول إن هذي النماذج عندها قدرة مرعبة على الحفظ. لو أعطيتها نص عشوائي ودربتها عليه مرة وحدة بس، تقدر تسترجعه حرفياً. البشر ما يقدرون يسوون كذا، وهذي ميزة عندنا وليست عيب. ضعف ذاكرتنا يجبرنا نبحث عن الأنماط ونربط الأفكار ونفهم المبادئ العامة بدل ما نحفظ كل التفاصيل. النماذج الحالية، بسبب ذاكرتها الحديدية، تعتمد على الحفظ أكثر من الفهم، وهذا يوقعها في فخ خطير سماه "الانهيار".
فكرة الانهيار هذي، خلوني أبسطها، إنك لما تخلي النموذج يبدأ يولد بيانات بنفسه ويدرب نفسه عليها، مع الوقت يفقد تنوعه وإبداعه. كأنه يدور في حلقة مفرغة ويكرر نفس الأفكار. ضرب مثال بسيط، روح لـ ChatGPT واطلب منه يقول نكتة. راح تلاحظ إنه يعرف ثلاث أو أربع نكت ويعيدها عليك. ليش؟ لأن توزيع البيانات اللي يقدر يولدها صار "منهار" ومحدود. هذا عكس البشر تمامًا، خصوصاً الأطفال. الأطفال عندهم قدرة إبداعية هائلة لأنهم ما بعد تلوثوا بأنماط التفكير المحددة.
هذي النواقص المعرفية ظهرت له بوضوح لما كان يبني مشروعه البرمجي الأخير nanochat. حاول يستخدم وكلاء البرمجة عشان يساعدوه، بس يقول إن التجربة كانت سيئة جداً. المشكلة إن مشروعه كان فريد من نوعه، وطريقة كتابة الكود فيه ما كانت نمطية.
هذي النماذج، لأنها تدربت على ملايين الأكواد النمطية من الإنترنت، كانت تحاول تفرض عليه الأنماط الشائعة. كانت تصر إنه يستخدم مكتبة معينة هو ما يبيها، وتضيف أسطر كود دفاعية ما يحتاجها. في النهاية اكتشف إنها ما هي مفيدة أبداً للمهام الإبداعية، وأن أفضل استخدام لها اليوم هو الإكمال التلقائي الذكي، حيث أنت تكون المهندس اللي يقود العملية.
طيب، كيف تتعلم هذي النماذج وتصير أذكى؟ هنا كارباثي عنده نقد لطريقة "التعلم المعزز" الحالية. وصفها بتشبيه بليغ جداً، قال إنها مثل "محاولة سحب كل المعلومات المفيدة من خلال مصاصة عصير صغيرة".
خلوني أشرح لكم ايش يقصد. تخيل إنك تعطي النموذج مسألة رياضيات، وتخليه يكتب حل طويل من عشرين خطوة. بعد ما يخلص، كل اللي تسويه هو إنك تقوله "جوابك صح" أو "جوابك غلط". يعني معلومة وحدة بس، يا إيه يا لا.
المشكلة إن التعلم المعزز ياخذ هذي المعلومة الصغيرة جداً (صح/غلط) ويعممها على كل الخطوات العشرين اللي سواها النموذج. لو كان الجواب صح، راح "يكافئ" كل خطوة، حتى لو كان فيه خطوات في النص ما لها داعي أو حتى غلط بس بالصدفة وصلته للحل الصحيح. ولو كان الجواب غلط، راح "يعاقب" كل الخطوات.
هذي طريقة سطحية وغبية جدًا للتعلم، كأنك قاعد تهدر كل التفاصيل المهمة اللي صارت في عملية الحل نفسها. الإنسان ما يتعلم كذا أبداً. لما نحل مسألة، إحنا نراجع خطواتنا ونعرف وين بالضبط كانت المشكلة، أي خطوة كانت صح وأي خطوة كانت غلط، ونتعلم من التفاصيل هذي. لكن النماذج الحالية ما تسوي كذا، هي بس تاخذ النتيجة النهائية وتعممها بشكل أعمى، وهذا اللي يخلي تعلمها بطيء جدًا وغير فعال.
طيب، بعد كل هذي التحديات، هل كارباثي متشائم؟ بالعكس تماماً. هو يقول أنا متفائل، بس تفاؤله واقعي ومبني على خبرة. هو ما يشوف إن الذكاء الاصطناعي راح يجي فجأة ويغير كل شيء في يوم وليلة، مثل ما يتخيل البعض. يقول إن تطوره راح يكون بطيء وتدريجي، تمامًا مثل ما صار مع الكمبيوتر والإنترنت. كلها تقنيات عظيمة، بس ما شفناها تسبب "طفرة" مفاجئة في الاقتصاد العالمي، لكن تسللت لحياتنا شوي شوي.
خوف كارباثي الحقيقي ما هو من أن الذكاء الاصطناعي يصير شرير، لا. خوفه هو إن البشرية تصير كسولة وتفقد قيمتها، ونتحول لمجرد مستهلكين سلبيين، مثل الناس في فيلم WALL-E اللي جالسين على كراسيهم الطائرة والآلات تسوي لهم كل شيء. وهذا الخوف هو اللي خلاه يترك وظيفته في أكبر الشركات ويبدأ مشروعه الخاص في التعليم. هو ما يبغى يوقف التقنية، يبغى "يرفع مستوى" البشر عشان يواكبونها.
هدفه بسيط وواضح بدل ما نكون مجرد مستخدمين، لازم نكون إحنا الجيل اللي يفهم هذي التقنية ويبنيها ويوجهها. وبصراحة، هذي النظرة اللي تجمع بين الواقعية الهندسية العميقة والأمل في مستقبل البشر هي أكثر شيء نحتاجه اليوم. لا حماس أعمى، ولا تشاؤم محبط، بل عمل جاد ومسؤولية.
قرأت قبل قليل سؤال على منصة ريدت لشخص يسأل عن مجالات تعلم الآلة والذكاء الاصطناعي اللي الشركات تركز عليها في أبحاثها حالياً.
السائل باحث دكتوراه خلص قبل سنتين، ويشتغل حالياً كعالم بيانات، بس يبي ينتقل لدور بحثي أكثر. مشكلته إنه متخصص في تعلم الآلة الكلاسيكي والإحصاء، وما عنده خبرة قوية في مجالات مثل معالجة اللغات الطبيعية أو الرؤية الحاسوبية، ويحس إن خلفيته هذي صارت قديمة شوي في سوق اليوم.
سؤاله هذا حسيت إنه يعبر عن قلق موجود عند ناس كثير في مجال التقنية. المشهد يتغير بسرعة لدرجة إن الخبرات اللي كانت مطلوبة بقوة قبل سنوات قليلة، ممكن اليوم ما تكون هي الأهم. الذكاء الاصطناعي ما عاد مجرد مجال واحد، صار عبارة عن عوالم متفرعة، وكل عالم له متطلباته ومهاراته الخاصة، والانتقال من واحد للثاني يحتاج مجهود وفهم للاتجاه اللي السوق رايح له.
من خلال إجابات الناس على سؤاله، اللي كانوا باحثين وموظفين في شركات تقنية كبيرة، نقدر نرسم خريطة للمجالات البحثية اللي عليها طلب كبير في القطاع الخاص اليوم. الردود انقسمت لعدة اتجاهات رئيسية، كل واحد يمثل زاوية مختلفة من صناعة الذكاء الاصطناعي.
أول وأهم اتجاه، وهو اللي الكل متفق عليه، هو عالم النماذج اللغوية الكبيرة (LLMs) وكل ما يدور حولها. بس النقطة المهمة هنا إن البحث ما هو فقط في بناء نماذج جديدة من الصفر، لأن هذا مكلف جداً ومحصور في عدد قليل جداً من الشركات العملاقة.
البحث الحقيقي اللي عليه طلب في أغلب الشركات هو في مرحلة ما بعد التدريب. هنا يدخل بقوة مجال التعلم المعزز (Reinforcement Learning)، وبالتحديد تقنية التعلم المعزز من خلال الملاحظات البشرية (RLHF)، اللي هي باختصار طريقة لتعليم النموذج السلوك الصحيح وتصحيح أخطائه بناءً على تقييمات بشرية، زي لما تعلم طفل صغير الصواب من الخطأ.
وهذا يودينا لنقطة ثانية انذكرت، واحد من المعلقين قال إن أغلب "الأبحاث" في الشركات الصغيرة والمتوسطة ما هي إلا محاولة لعمل غلاف جذاب لنماذج موجودة أصلاً مثل نماذج OpenAI أو Claude.
الشغل هنا يكون أغلبه هندسي، يركز على كيفية كتابة الأوامر (Prompts) الصحيحة، أو عمل ضبط دقيق (Fine-tuning) للنماذج على بيانات خاصة بالشركة. مع إنها ما تعتبر أبحاث أساسية، إلا إن الطلب عليها عالي جدًا لأنها الطريقة الأسرع لتحويل الذكاء الاصطناعي لمنتج تجاري.
بعدين يجي اتجاه ثاني مختلف تماماً، وهو الذكاء الاصطناعي على الأجهزة الطرفية (On-device AI). الفكرة هنا ما هي بس إنك تاخذ نموذج وتحطه في الجوال. التحدي كبير لأن موارد الجوال أو اللابتوب محدودة جدًا.
بالتالي، فيه أبحاث كثيرة في كيفية ضغط النماذج الكبيرة وتحويلها لنماذج أصغر حجم بدون ما تفقد دقتها، وهذي العملية تسمى التكميم (Quantization). بجانب هذا، فيه أبحاث عن البنية العصبية (Neural Architecture Search) لاكتشاف أفضل تصميم للنموذج يناسب الأجهزة المحدودة.
شركات مثل آبل بنظامها MLX، وقوقل بـ LiteRT، وكوالكوم، تستثمر بكثافة في هذا المجال. وضمن هذا الاتجاه يجي التعلم الاتحادي (Federated Learning)، اللي يسمح بتحسين النماذج من خلال بيانات المستخدمين بدون ما تطلع هذه البيانات من أجهزتهم، وبالتالي يحافظ على الخصوصية، وقوقل تستخدمه في الكيبورد حقها GBoard .
وفيه اتجاه ثالث متخصص جداً، يركز على العلوم الطبيعية. هنا نشوف استثمارات كبيرة في مجال اكتشاف الأدوية وعلوم المواد. شركة مثل Isomorphic Labs (التابعة لألفابت، شركة قوقل الأم) تعتبر لاعب ثقيل في هذا المجال. بس المشكلة، زي ما ذكر أحد المعلقين، إنك ما راح توصل لمرحلة المقابلة أصلًا لو ما كانت شهادة الدكتوراه حقتك في نفس هذا التخصص تحديدًا وعندك أبحاث منشورة فيه. هو مجال واعد، بس محصور على أصحاب الخلفيات العلمية العميقة فيه.
أخيراً، فيه مجالات تعتبر كلاسيكية لكنها ما زالت حية ومطلوبة، لأنها أساس كل شيء. الأول هو أنظمة التوصية (Recommendation Systems). مثل ما قال واحد في الردود، هذا المجال راح يبقى مطلوب طالما الرأسمالية موجودة. السوشيال ميديا عموماً، إعلانات يوتيوب، توصيات أمازون، كلها تعتمد على هذه الأنظمة.
المجال الثاني هو أنظمة تعلم الآلة (ML Systems)، وهذا يشمل كل شيء تقني ومنخفض المستوى، مثل تحسين أداء النواة (Kernels) وأنظمة التشغيل والتخزين المؤقت (Caching) لتشغيل النماذج بأسرع وأكفأ طريقة ممكنة. هذا المجال فيه نقص كبير في المواهب لأن أغلب الباحثين يفضلون الشغل على المواضيع الأكثر شهرة مثل تصميم النماذج الجديدة.
برأيي، اللي يميز المشهد الحالي هو إنه تفرع بشكل كبير. ما عاد فيه مسار واحد واضح. فيه المسار السريع والمباشر اللي هو الشغل على النماذج اللغوية الكبيرة، وفيه المسارات العميقة اللي تتطلب صبر وخلفية تقنية قوية مثل أنظمة تعلم الآلة أو الذكاء الاصطناعي على الأجهزة، وفيه المسارات شديدة التخصص مثل اكتشاف الأدوية.
نصيحتي لنفسي أولاً ولكل اللي يحسون نفس شعوره، هي إن أساسيات الإحصاء وتعلم الآلة الكلاسيكي ما زالت حجر الأساس، وهي اللي تفتح لك أبواب فهم المجالات الأخرى ، دائما قوي نفسك بالأساسيات والباقي كلها راح يكون سهل.
المطوّر السابق في OpenAI أندريه كارباثي نشر مشروعًا مفتوح المصدر (حصل على 9 آلاف نجمة خلال يوم واحد) يتيح لك تجميع وتدريب نموذج LLM لبوت محادثة من الصفر خلال ساعات على GPU سحابي. داخل المشروع فقط 8,000 سطر من الكود بلا تبعيات زائدة.
تدريب النموذج يستغرق قرابة 4 ساعات ويكلّف حوالي 100 دولار عند استئجار القدرة الحاسوبية من مزوّد سحابي.
https://t.co/BMtPYxNZ35
فرصتك لتكوني جزءاً من مستقبل الذكاء الاصطناعي..
يدعو مركز @ICAIRE_AI الدولي برعاية منظمة اليونسكو @UNESCOarabic ، النساء حول العالم للتسجيل في برنامج Elevate لتمكين المرأة في مجال الذكاء الاصطناعي.
Elevate: your opportunity to be part of the future of AI
The International Center for AI Research and Ethics @ICAIRE_AI
, under the auspices of @UNESCO, invites women to register for Elevate, a global program dedicated to empowering women worldwide in the field of AI.
شدني تقرير أصدرته شركة EY، إحدى أكبر شركات الاستشارات في العالم، حيث ذكر التقرير أن:
70٪ من الشركات التي تبنّت الذكاء الاصطناعي تكبّدت خسائر مالية وصلت إلى 4.4 مليار دولار!!
وذلك بسبب ضعف الحوكمة وضعف الدمج بين الإنسان والآلة.
بدأت ابحث أكثر لمعرفة شيء من هذه الأمثلة، فوقعت على قصص كثيرة وغريبة وبعضها مضحك قام فيها الذكاء الاصطناعي بارتكاب "أخطاء غبية" ومكلفة جداً، وهذه بعض الأمثلة:
أولاً: شركة الاستشارات الشهيرة Deloitte فرع أستراليا 🇦🇺
قبل شهرين سلّمت شركة Deloitte تقريرًا حكوميًا أعدّه الذكاء الاصطناعي واحتوى على اقتباسات ومراجع من نسج الخيال، بسبب استخدام الشركة ChatGPT ، عندها اضطرت لإعادة جزء من قيمة العقد بعد أن تم اكتشاف هذا الخطأ الكبير الذي يصل إلى فضيحة في حق شركة استشارية بهذا الحجم.
ثانياً: أمازون والتوظيف بالذكاء الاصطناعي 🇺🇸
حين اكتُشف أن أداة التوظيف بالذكاء الاصطناعي تعلّمت من بيانات تاريخية منحازة لصالح الرجال، فكانت تستبعد السير الذاتية التي تتضمن كلمات عن المرأة مثل “women’s” أو “female”.، فاضطرت أمازون ايقاف الأداة قبل إطلاقها رسميًا بعد إنفاق ملايين الدولارات في التطوير، و إعادة تصميم الخوارزميات.
ثالثاً: الخطوط الكندية 🇨🇦
تسبب روبوت خدمة العملاء لدى Air Canada في تقديم معلومات خاطئة للمسافرين حول استرداد التذاكر، لتجد الشركة نفسها مطالبة بتعويضات مالية تقدر بنحو 2,000 دولار لكل حالة، إلى جانب خسارة ثقة عملاءها.
رابعاً: شركة IBM 🇺🇸
خسرت IBM أكثر من 62 مليون دولار في مشروعها الطبي الشهير Watson for Oncology بعدما تبيّن أن توصياته الطبية غير دقيقة وغير آمنة في مشروع لتشخيص السرطان.
ختاماً..
هذه القصص تؤكد لنا أن الذكاء الاصطناعي مهما بلغ فهو لا يملك الحسّ الإنساني ولا يعي السياق ولا يتحمّل المسؤولية.
الذكاء في التقنية لا يُغني عن ذكاء البشر الذين يوجّهونها.
ففي النهاية، ليست المشكلة أن الذكاء الاصطناعي أخطأ، بل أن الإنسان صدّق أن الذكاء الاصطناعي لن يخطئ.
Proud that @ICAIRE_AI co-organized today’s UN AI event with #SDAIA during #UNGA80 — and even more special to celebrate it on Saudi Arabia’s 95th National Day 🇸🇦
Scenes from the High-Level Side Event on AI capacity building organized by Saudi Arabia, represented by #SDAIA, as part of the High-Level Week of the 80th United Nations General Assembly #UNGA80 in New York.