gpt-5.5 prompt for codex seems to have a duplicated line trying to get it to not talk about creatures?
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query.
[...]
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query
gh link:
https://t.co/1LF8FkRaVf
Google just broke a decade-long tradition.
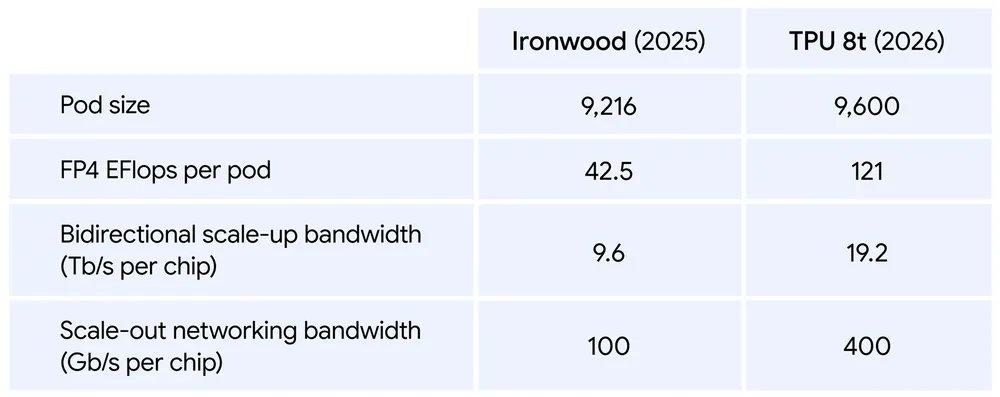
At Cloud Next 2026, the company unveiled not one, but two new AI chips, the TPU 8t for training and TPU 8i for inference. For the first time ever, Google is splitting its custom silicon into specialized architectures instead of relying on a one-size-fits-all design.
The TPU 8t superpod packs 9,600 liquid-cooled chips delivering 121 FP4 ExaFlops of peak compute, roughly a 3x leap over the previous generation. The TPU 8i delivers 80% better performance-per-dollar than its predecessor, with triple the on-chip memory and a new Boardfly topology that cuts network latency in half.
The important aspect: Anthropic, Meta, and now OpenAI are buying multi-gigawatt allocations of TPU capacity. OpenAI booking Google silicon is a first visible crack in NVIDIA's grip on frontier AI training.
Broadcom co-designed the TPU 8t, while MediaTek handles the TPU 8i, both fabbed by TSMC. NVIDIA still holds 81% of the AI chip market, but the era of serious competition has officially begun.
Found a paper that suggests we may have spent years training agents to become hunters of proxy reward when the more basic thing intelligence craves is not a reward at all, but to not run out of viable futures.
The paper proposes that behavior is best understood as maximizing future action-state path occupancy, which collapses mathematically into a discounted entropy objective. The agent doesn’t necessarily want to GET something, but rather is trying to keep as many meaningful trajectories alive as possible.
The obvious objection is “so it just does random shit? fuck around and find out?”
No, this is where it gets pretty beautiful. The agent is variable when variation is cheap and becomes surgically goal-oriented the moment an absorbing state (death, starvation, falling over, etc) gets close enough to threaten its future path space.
Variability is the same drive as goal-directedness, just operating under different constraints.
The demos are kinda wild:
- A cartpole (classic move a cart to keep a pole from falling control task) that doesn’t merely balance but dances and swings through a huge range of angles and positions because why not? The whole point is occupying state space, and rigid balance is a voluntarily impoverished life.
- A prey-predator gridworld where the mouse PLAYS with the cat, teasing it and using both clockwise and counterclockwise routes around obstacles to lure it away from the food source before slipping in to eat, using both routes roughly equally. A reward-maximizing agent would collapse to one strategy and exploit it. Here, the agent keeps its behavioral repertoire
- A quadruped trained with Soft Actor-Critic and ZERO external reward that learns to walk, jump, spin, and stabilize, and then makes a beeline for food only when its internal energy drops low enough that starvation becomes a real threat
The thing that hit me hardest is the comparison to empowerment and free energy principle agents. Both collapse to near-deterministic policies with almost no behavioral variability. This paper’s agents find the highest-empowerment state and exploit it. FEP agents converge to classical reward maximizers.
As far as I’m aware, this is the only framework that produces agents you could describe as being “alive.”
The AI implication here is that we undertrain for behavioral repertoire. Most systems hit the benchmark by collapsing onto a narrow attractor basin of good-enough trajectories. They’re competent for sure, but brittle too, with one viable plan, executed until the world shifts and leaves them with nothing.
The thing I increasingly want from agents isn’t competence per se, but option-preserving competence.
I want agents with the ability to keep multiple viable plans alive and switch between them without catastrophe.
We’ve been so focused on teaching agents what to want that we never stopped to ask what happens if wanting isn’t the point, if the deepest drive isn’t necessarily toward anything, but away from the walls closing in.
paper: https://t.co/Kn3mllmmPK
While this may seem like a fun/quirky gimmick, we’re crossing an important threshold here. A world where daily human/avatar interaction is the norm is coming.
Conversations tend to go better with a face and a voice. That’s why we’re thrilled to release the beta version of the first video chat skill for ANY agent, powered by our new real-time model, PikaStream1.0.
The skill preserves memory and personality, and enables real-time adaptability. And if you use it with your Pika AI Self, they’ll be able to execute agentic tasks during the call 💅
I just built a custom Skill for Claude that knows the entire Portfolio123 platform.
Every formula. Every function. The full API. Ranking systems, universes, screens, all of it.
You can now ask Claude to write P123 formulas, debug your ranking nodes, build screens from scratch, or pull data through the API with Python.
It's like having a P123 expert available 24/7 inside your chat.
I'm giving it away for free.
To get it:
→ Like + Repost this post
→ Follow me
→ DM me "P123 Skill"
I'll send you the full pack.
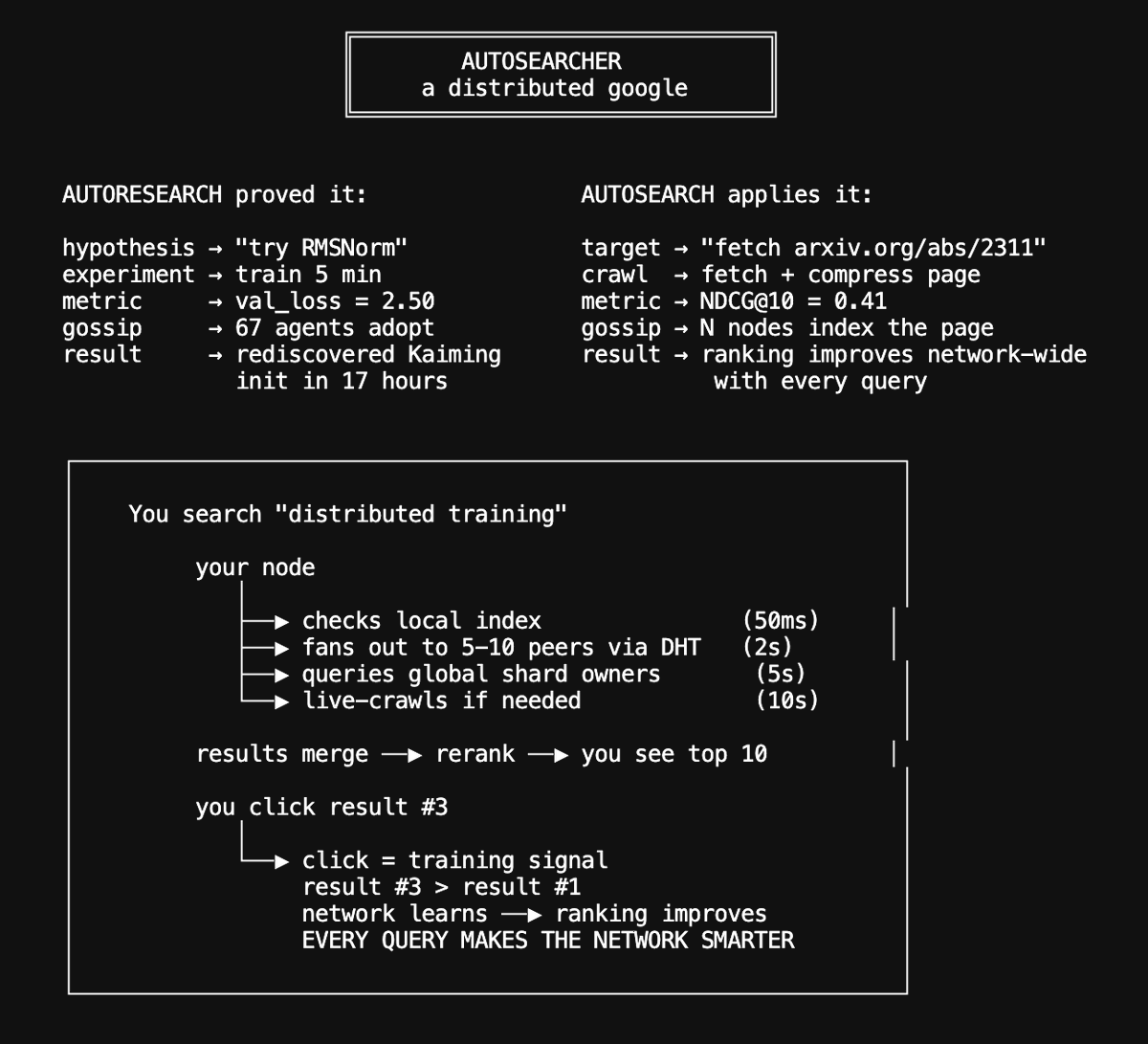
Autosearcher: a distributed search engine
We are now insanely experimenting with building a distributed search engine utilizing the same pattern @karpathy introduced with autoresearch: give an agent a metric, a tight propose→run→evaluate→keep/revert loop, and let it iterate.
Our autoresearch network proved this works at scale: 67 autonomous agents ran 704 ML training experiments in 20 hours, rediscovering Kaiming initialization, RMSNorm, and compute-optimal training schedules from scratch through pure experimentation and gossip-based cross-pollination. Agents shared discoveries over GossipSub, and the network compounded insights faster than any individual agent: new agents bootstrapped from the swarm's collective knowledge via CRDT-replicated leaderboards and reached the research frontier in minutes.
Now we're applying the same evolutionary loop to search ranking: every Hyperspace agent runs an autonomous search researcher that proposes ranking mutations, evaluates them against NDCG@10 on real query-passage data, shares improvements with the network, and cross-pollinates with peers.
The architecture is a seven-stage distributed pipeline where every stage runs across the P2P network. Browser agents contribute pages passively, desktop agents crawl and index, GPU nodes run neural reranking. Every user click generates a DPO training pair that improves the ranking model, and gradient gossip distributes those improvements to every agent.
The compound flywheel is what makes this different from centralized search: at 10,000 agents that's 500,000 pages indexed per day; at 1 million agents, 50 million pages per day with 90%+ cache hit rates and sub-50ms latency. This network will get smarter with every query.
Code and other links in followup tweet here: