The HF science team just made async RL weight sync ~100x cheaper on bandwidth, and you don't need a shared cluster anymore.
The problem: every RL step, the trainer typically has to sync fresh weights to the inference engine. for a 7B in bf16 that's ~14GB. for a frontier 1T fp8 checkpoint, that's ~1TB; in bf16 it would be ~2TB. per sync.
The insight: between two RL steps, ~99% of bf16 weights are bit-identical. at RL learning rates, the optimizer is whispering and bf16 literally cannot hear most of it. the stored bf16 bits don't change.
What they shipped in TRL: only the changed elements get encoded as a sparse safetensors file, dropped into a Hugging Face Bucket, and fetched by vLLM. on Qwen3-0.6B, per-step payload goes from 1.2 GB to 20 to 35 MB. This is exactly what we built Buckets for: S3-like object storage on the Hub, Xet-backed (so even full snapshots only transfer the changed chunks).
The cherry on top: we ran a FULL disaggregated training where:
- the trainer lived on one box
- vLLM ran inside a Hugging Face Space
- the Wordle environment ran in another Space
- weights flowed through one Hub bucket
no shared cluster. no RDMA. no VPN. no NCCL across clouds. just HTTPS and a bucket.
one GPU + a Hugging Face account is now enough to do real disaggregated RL. multi-replica inference fleets across regions become a small devops exercise, not a research project.
Full write-up: https://t.co/CG115IjT0q
Open source RL keeps eating the moat!
Introducing Repo2RLEnv
Turn any repository into runnable, verifiable coding environments built from real PRs and commits for coding-agent evaluation or RL training
> uv pip install repo2rlenv
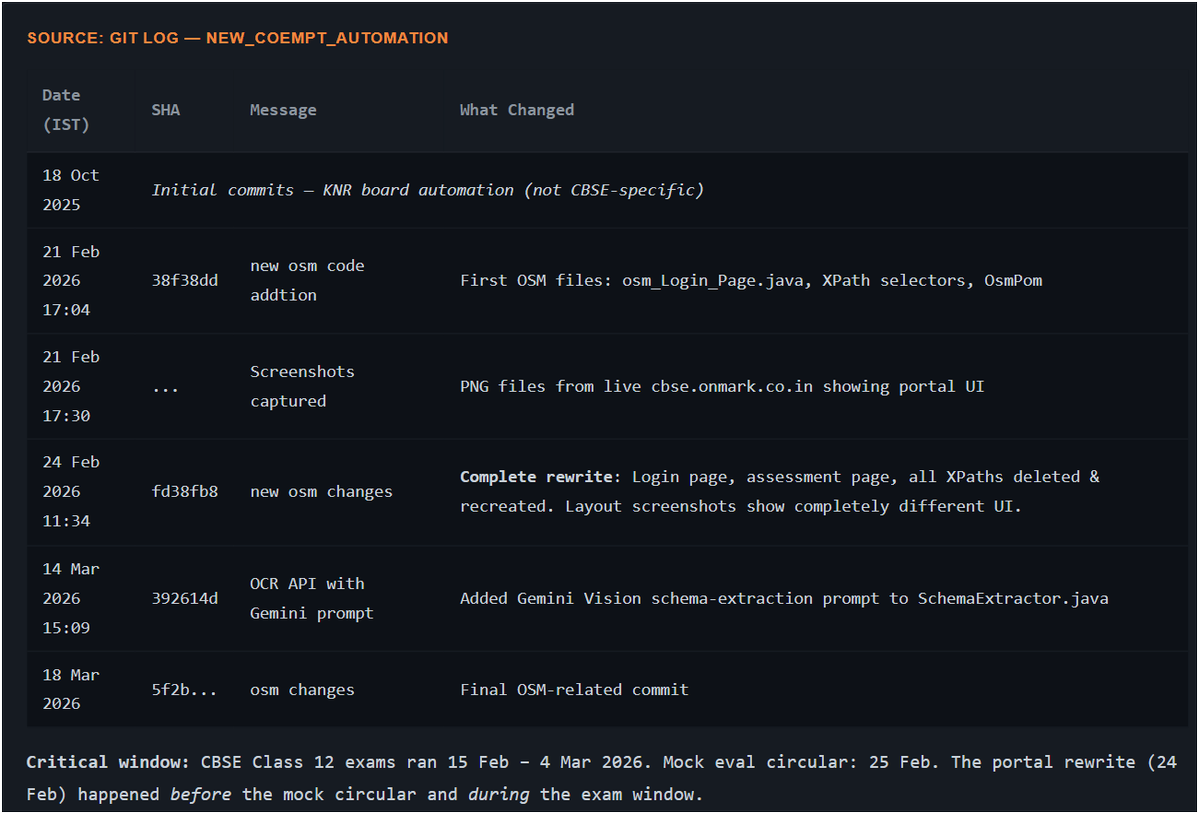
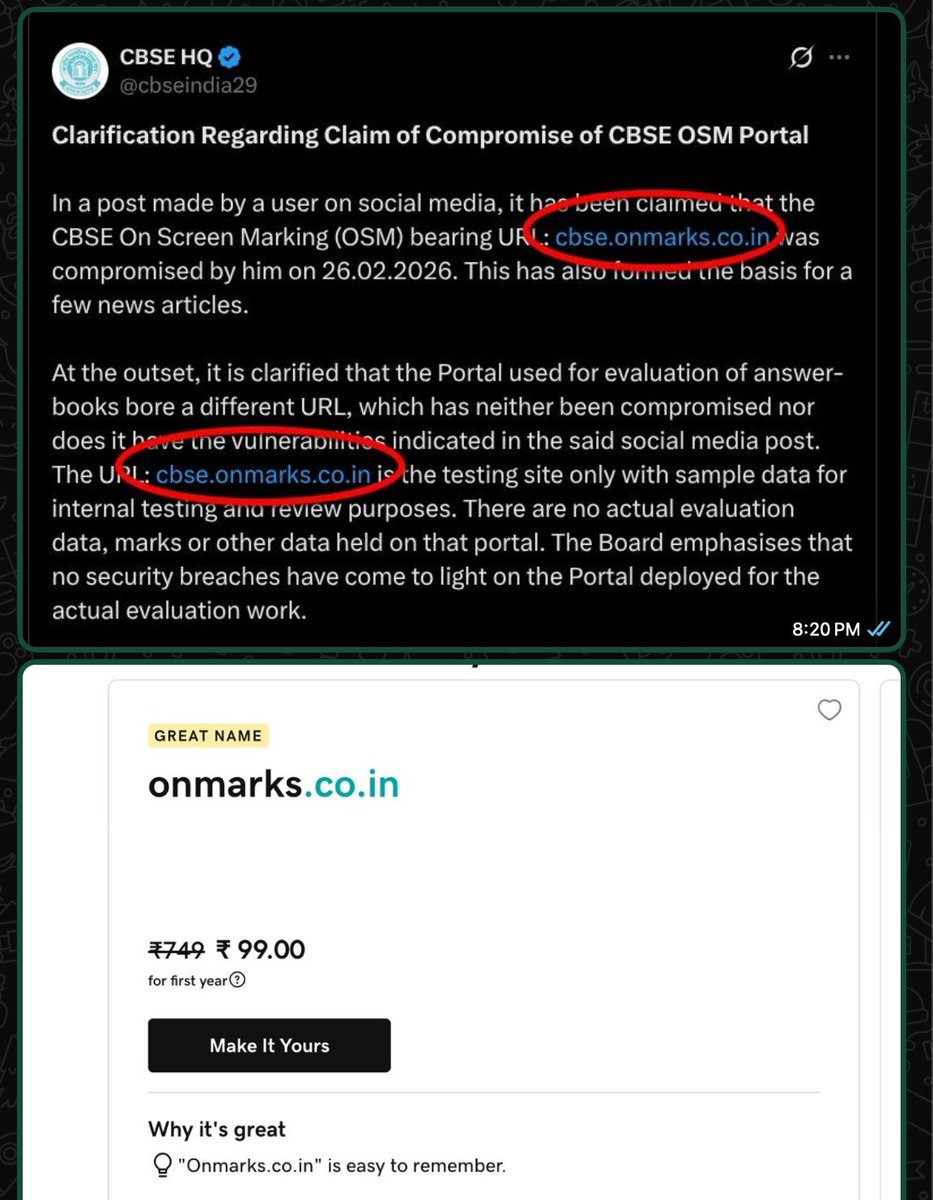
I had hacked CBSE's OSM (On-Screen Marking Portal) in February and had reported the vulnerabilities to CERT-In, but they were unable to patch most of them.
I've written a detailed blog post about it here: https://t.co/qyT23GkTEJ
Launching NayanaOCR Corpus
👉🏼 1M+ Document images across 22 languages
Largest open source synthetic
> multilingual
> multimodal
> multitask
document corpus
We are releasing Carbon: a crazy fast DNA model
Carbon is 275x faster than the next best model. So fast you can process the whole human genome on a single GPU in <2 days.
Here are the tricks we used:
When modelling DNA sequences a lot of the performance comes down to tokenizing the sequences in a smart way. BPE tokenizer struggle because there are no whitespaces and character (called base in DNA) level tokenizers waste a lot of compute on too many tokens.
Carbon is built with a unique tokenizer: we split sequences in chunks of 6 bases, but during both training and inference we can work with single base resolution. That's similar to having word tokens but resolving them at the character level. All possible thanks to the DNA tokens unique structure.
The architecture combined with the tokenizer makes the model 275x faster than the previous SoTA (Evo2) at this size.
We built an interactive demo so you can explore how the model can generate DNA sequences, investigate the structure of genes, predict the effect of mutations, generate and fold proteins and even reconstruct parts of the tree of life.
https://t.co/OWEUoxAFjG
This is coming from a place of frustration. I am getting to know about the Open Source India Summit today, where I cannot apply anymore as a speaker.
I work at Hugging Face, which has done a lot for Open Source. Are the board members oblivious to the presence of HF in India? If yes, we are definitely doing something worng.
Tagging the Indian workforce here @RisingSayak, @adarshxs, @adithya_s_k, @_DhruvNair_, @yvrjsharma
PS: I dare you to pick GitHub profiles of any one of them.
The kernels project at Hugging Face has been growing!
We want it to be the go-to place for kernel devs and kernel users.
We're looking to work w/ folks who're interested in doing agentic kernel dev, providing real optim value to real models.
Reach out if interested :)
Anyone interested in a CUDA deep dive that makes your workload 25% faster? 🧐
Just published a new blog post on asynchronous CPU / GPU inference: 100% insight, zero slop 😊
To learn how to remove all CPU overhead and use your GPU to the max, just read it 🔥
Got featured in a physical magazine !!
thank you @Analyticsindiam and @MohitingAround for the feature
ps: I don’t think India has an AI talent problem. I meet and work with so many amazing people, and I’ve come across some incredibly talented researchers in india.
The article mainly talks about how I got started in my AI journey after the launch of ChatGPT and how being public about it, applying to opportunities, doing open source projects has helped
We've heard the community's feedback. Our intent was to make sure the credits reached the people who supported SGLang along the way, and we couldn't be here without you. We're updating the offer to better reflect that.
RadixArk's platform is open for beta, and we're offering $200 in compute credits to get you started
→ Sign up at https://t.co/MVDvcvkFGX and repost this so we can get you set up.
→ Limited spots, first come first serve. Open through May 13, 2026 (AoE).
→ Credits will be granted after we verify the repost.
(If you already reposted our earlier announcement, that counts too; no need to do it again.)
And if SGLang has been useful in your work, consider giving it a star on GitHub. It's a small gesture that means a lot to the people maintaining it. We're in this together, and we're grateful to be building it with you 🧡
Real-time World Models are the next AI frontier.
Today, we @reactorworld are taking the first step towards this reality: our early preview lets you experience worlds generated in real-time, running on our global low-latency infrastructure.
Try it now: https://t.co/YojJ5qVDrG