For most of history, expertise was scarce, constrained by time and reach: one person, one career, one lifetime.
Now, for the first time, we can encode, evaluate, and scale it.
We believe the wisdom that once took a lifetime to build shouldn’t take a lifetime to find.
Today, we’re excited to announce that @AfterQuery has raised a $30M Series A at a $300M valuation and that we’ve since surpassed $100M in annual revenue run rate, to build the data layer of professional AI.
@AfterQuery will be at ICLR next week!
We’ll be at booth 404. Happy to chat about anything related to tool use/agents, RL environments, code gen, or evals.
DM me if you wanna meet up!
AfterQuery post-trained GPT-OSS-20B using Harbor + Tinker and saw a 14% bump on TB2 performance.
Love seeing people pick up Harbor for more than just evals.
YC and @GoogleDeepMind are hosting the Multimodal Frontier Hackathon this Saturday.
Most AI apps still don't utilize the full multimodal stack. So we’re giving you access to Gemini 3.1, Lyria, & NanoBanana 2 to see what you can build!
Sign up at: https://t.co/AyMfFHlSxi
Introducing IDE-Bench!
A multi-language, full-stack benchmark evaluating LLMs acting as autonomous IDE agents
IDE-Bench assesses agents' ability to navigate, reason, and modify complex repositories using the same tools available in modern AI-native IDEs like Cursor
Models tested from @AnthropicAI, @OpenAI, @Alibaba_Qwen, @GoogleDeepMind, @xai, @deepseek_ai, @Meta, and @cohere
Check out the full results at https://t.co/MdqB7SL5JY!
Our findings show that current models lack the ability to perform even the most basic tasks in high-impact, real-world domains like quantitative trading.
We hope Market-Bench can serve as a shared framework to evaluate models’ understanding of trading strategies and code generation for quantitative finance.
Excited to track how these capabilities evolve!
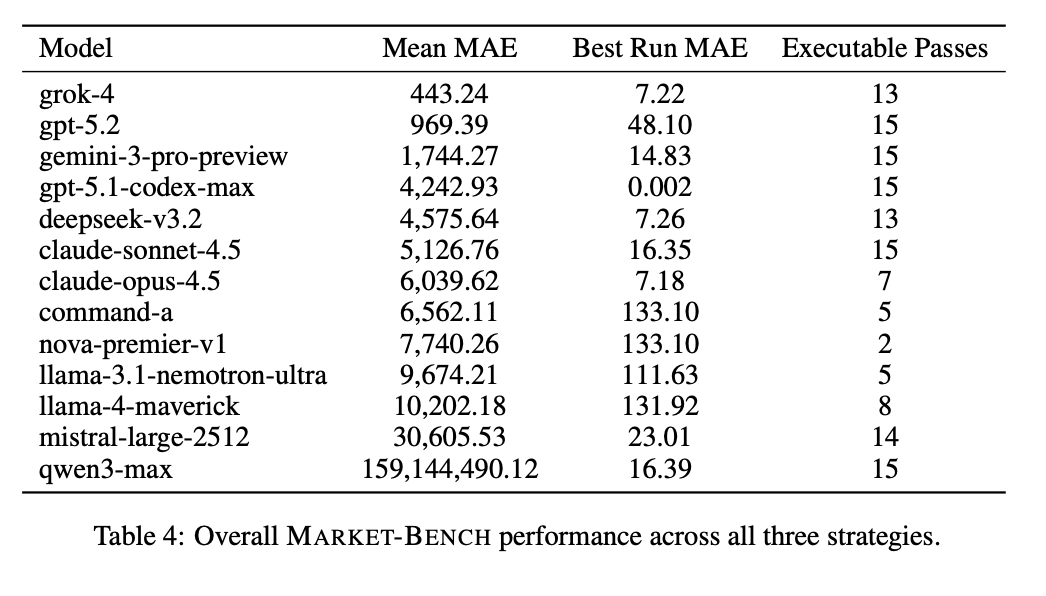
Introducing Market-Bench by @AfterQuery! The first-of-its-kind benchmark on LLMs for quantitative finance.
We challenged models to attempt a frequent introductory quantitative trading task: coding an executable backtester from a natural-language strategy description and market assumptions.
> 13 models build backtesting systems for directional, pair trading, and delta hedging strategies
> evaluated on reliability (executable passes) and accuracy (MAE) across 5 attempts per strategy
> real order book data with exchange delays and liquidity constraints
> @xAI’s Grok 4 achieved the overall lowest mean MAE (deviation from the golden backtest), followed closely by @OpenAI’s GPT 5.2
> @AnthropicAI's Sonnet 4.5 and @AlibabaGroup's Qwen 3 Max at perfect executability but high MAE
> Models from @Meta, @Amazon, @NVIDIA, and @Cohere continued to fail to produce executable backtesters
Leaderboard & full paper below!
Today, humanity is shackled by scarcity of expertise. When expertise becomes infinitely scalable, humans will be freed to tackle problems we can't even conceive of today.
Introducing @AfterQuery. We’re building a world where expertise is abundant.
Domain by domain, profession by profession, AfterQuery is crafting datasets that encode excellence into forms that machines can learn.
Data is the final frontier.
The frontier begets the frontier.
I highly recommend reading @jaminball's latest Clouded Judgement article which spells out the AfterQuery thesis
(thread)
while leaderboards are fun and motivating, this is just the start for figma make. can't wait to share all the improvements we are making over coming days / weeks / months!
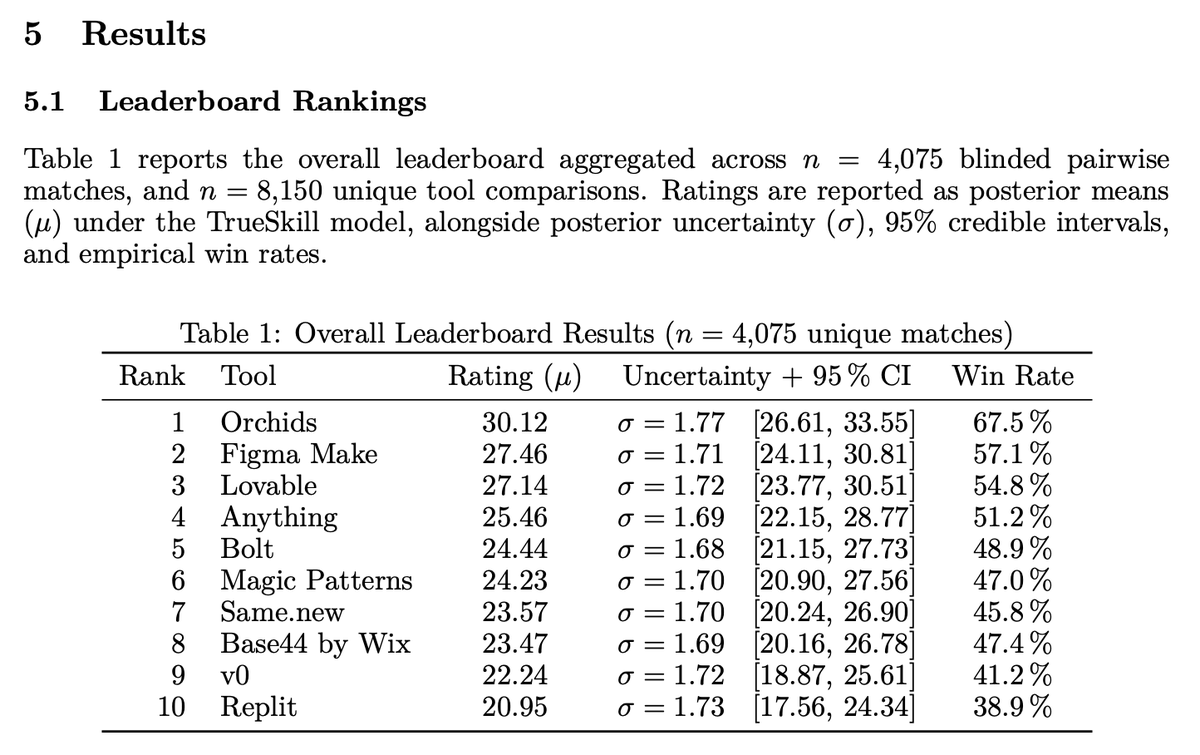
Introducing UI-Bench by @afterquery. The first and only rigorous eval of vibe coding tools.
> 4,000+ blinded pairwise judgments
> @budapp, @figma make, and @lovable take the lead
> @v0 and @replit ranked dead last
> performance gaps = differences in LLM orchestration, prompting, design templates, and post-processing
> link to our paper in the comments!