As video generative models reshape how we consume visual media, we ask: what controls are essential for them to meaningfully support professional workflows?
Stable Cinemetrics will be presented at NeurIPS 2025. Please visit our (interactive) webpage for detailed findings, insights and more : https://t.co/3oJSBlYQ3z
In this project, we had the unique opportunity to receive feedback from an Academy Award winner. While projects may come and go, that is one experience I will always cherish!
🎬 Introducing Stable Cinemetrics, to be presented at NeurIPS 2025.
We present the first taxonomy of professional controls to systematically study and control video generative models through the lens of filmmaking.
Interactive webpage with paper link: https://t.co/Eh4Hw3hBZl
🧵
Before AI can generate professional videos, it needs to see like a professional.
We spent a year with 100+ content creators teaching AI to describe video like a filmmaker would.
Introducing CHAI: Critique-based Human-AI Oversight for Building a Precise Video Language [CVPR'26 Highlight, Top 3%].
Try prompting a video generator for a dolly zoom, dutch angle, point of view, or camera roll. Most fall back to the same bland defaults: a push-in, a level shot, a third-person view. Why? These techniques require a language of cinema that current models rarely speak.
We built that language:
1️⃣ Precise specification: 5-aspect structured captions co-designed with professional cinematographers covering subject, scene, motion, spatial, and camera dynamics
2️⃣ Scalable oversight: LLMs draft captions, humans critique what's wrong and how to fix it
3️⃣ Post-training recipes: Qwen3-VL-8B surpasses Gemini-3.1 and GPT-5
4️⃣ Video generation: fine-tuned Wan follows 400-word cinematic prompts with precise control
Here's how each works 🧵
Work led by CMU and Harvard with @chancharikm, @du_yilun, and @RamananDeva.
📄 Paper: https://t.co/wCwEtvrntM
🌐 Site: https://t.co/oAAQklGrfF
Amidst today's tsunami of papers, it's quietly validating as an early career researcher to see your past work cited by multiple reviewers in their @iclr_conf reviews!
Looking forward to ICCV’25! 3 workshop talks, 1 panel and 7 papers.
Keynote talk on “Crafting Video Diffusion: Precise Inputs and Rich Outputs” in 3 workshops:
https://t.co/LekqWM8Xil
https://t.co/jdNDbjVSxY
https://t.co/vMJqiph7M3
Panel discussion at https://t.co/WYyrnUMCR0
@RisingSayak Not an expert in preference datasets: But is there also merit in scoring images? Chosen/Rejected is a form of hard scoring whereas a soft score (e.g. between 1-10) might also be beneficial to the community (and for models) ?
Looking forward to our SPRIGHT poster session at #ECCV2024 today with @agneet42.
It's #213 and we will be there from 4:30 PM to 6:30 PM (CEST).
But I am here at ECCV today almost for the day. Looking forward to chats 🇮🇹
https://t.co/DY4DPnEkVZ
Dear friends, from Sun Sep 29th, @ApgAsu ers will present 👇papers, DC poster, organize tutorial and workshop paper @eccvconf with a focus on semantically precise #T2I, secure #GenAI and a survey of Recent Event Camera Innovations.
Please chat with our talented members! 🙏🤠
Joint work with @FPSLuozi @trgokhale @prof_yz@cbaral
Both REVISION and SPRIGHT (https://t.co/yIiP6grOth) will be presented at @eccvconf and are efforts towards improving the 3D understanding of current vision-language models.
While we conduct most of our experiments on Stable Diffusion 1.4 and 1.5, our pipeline can be extended to incorporate larger models, for increased control over backgrounds, colors or style.
We also develop the RevQA benchmark, to evaluate spatial reasoning abilities of multimodal LLMs. RevQA is a question-answering benchmarking which has 16 diverse question types and their adversarial variations consisting of negations, conjunctions, and disjunctions.
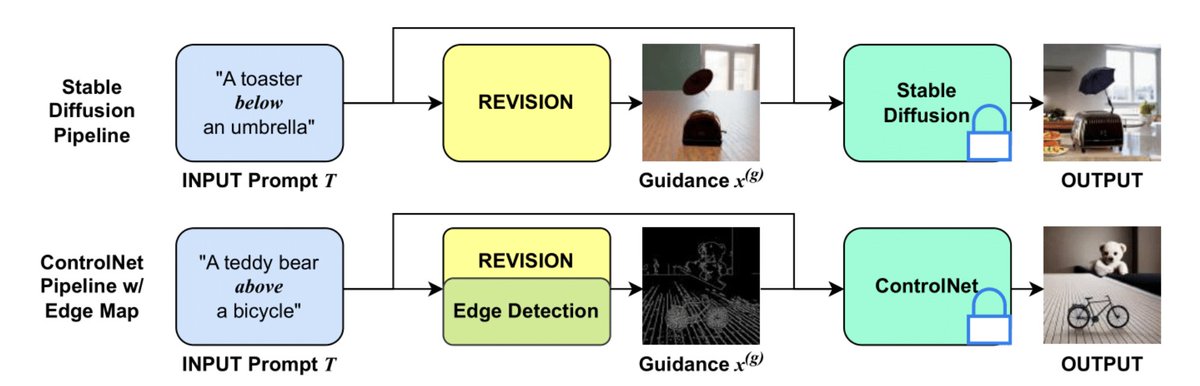
REVISION elevates the ability of existing T2I models to generate spatially accurate images. Given an input prompt, we generate a synthetic image using REVISION, which is used as additional guidance during image generation.
REVISION parses a prompt into assets (objects) along with the spatial relationship between them and synthesizes a symbolic image in Blender, placing the respective object assets at coordinates corresponding to the parsed spatial relationship.
Happy to share our latest work, REVISION, which will be presented at #ECCV2024.
Project Page : https://t.co/tI9My1aBP9
With REVISION, we combine the controllability of graphics rendering engines and the photorealism of T2I models to improve spatial fidelity.
🧵
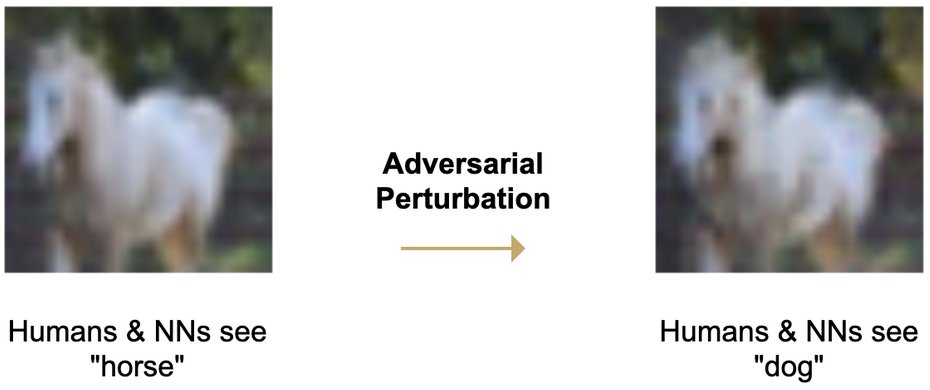
Adversarial attacks jailbreak models. Existing defenses don’t even safeguard simple models. In our ICML 2024 paper on "Adversarial Robustness Limits”, we show how scaling helps defense, up to the point where attacks start to fool humans (take quiz: https://t.co/mmLDnvTErY). 🧵1/n
Very pleased to see this accepted at #ECCV2024. See you in Milan to talk about diffusion models and other adjacent areas of work. 🇮🇹
Kudos to our truly global team 😉
Getting it Right
Improving Spatial Consistency in Text-to-Image Models
One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In