@jainarvind shares several important points in this post. Token spend is driven by architecture choices, and I would argue that it is more than that - it is your company’s policy. If you let your teams create the context they need on their own, you will have waste and sub par outcomes. Implementing a context graph that manages context across all agentic flows and for all teams has many benefits including token efficiency.
@levie is right - if you’re using the same models as your competitors, then your moat is your enterprise data and knowledge. Don’t give that away to the model companies. That’s your moat.
We enable you to do that with your own context layer. https://t.co/u4aa6R3Spr
As we enter the era of AI agents, one of the defining questions is how you develop competitive advantage when your competitor has access to the same AI models and intelligence as you.
The companies that are able to best harness their internal institutional knowledge, existing data assets, and domain-specific workflows -- connected with AI -- will be those that are able to stay ahead in the future.
Whether a company decides to build out the tech stacks themselves, or leverage a variety of best-in-class tools is certainly one core variable. But the key is to find the way that the enterprise can capture and protect the value created by their unique data, processes, and expertise over the long run. Each industry will have their own version of this, and the competitive advantage will vary by vertical.
We’re increasingly seeing this at Box, where customers want to ensure that they can take advantage of their institutional knowledge and have the flexibility of bringing any AI model and intelligence to their data at any time. This is a pattern that will increasingly become a core principle of strategy in the future.
"My body, my choice." Except when a Muslim mayor says cover up. Then it's "my body for votes."
Since yesterday, when I criticized AOC, I have been under attack by her fellow feminists and colleagues calling me Islamophobic. Really? I have no fear of my beautiful mother, who wears her hijab traditionally without being a hypocrite.
I simply asked you, AOC: you represent New York, you said the hijab is fun, and that's why you wore it at an event where men and women are strictly segregated and you gave a speech with a smile saying "this is fun." So I asked: would you also attend a court hearing facing the fifth assassin hired by the Islamic regime, to condemn a terror attack on New York soil? And that makes me Islamophobic? Or does it make you a hypocrite, someone who just takes photos, collects likes, and calls it inspiration, but isn't comfortable condemning terror attacks carried out by Islamic ideology on New York soil?
Iranian women live under the constant fear of lashes, imprisonment, execution, and assassins who follow them even beyond their borders into exile. Phobia is an irrational fear but our fear of being killed is not irrational.
I simply asked you to condemn Islamic terror that creates a sphere of fear on New York soil as well. And now I'm waking up being bombarded by your team, attacking and bullying me.
The invitation still stands: Iranian women who were intentionally blinded by the Islamic Republic, simply for showing their hair and protesting came to New York courtroom last public trial, to condemn Islamic terror, So my question is clear ; will you come with Zohran Mamdani to a courtroom in August to witness yet another assassin sent to New York soil by the Islamic regime to Kew, a woman on US soil?
@AOC
Muscle memory dies. Context lives.
@a16z: "Agents may kill muscle memory as a moat, but they do not kill operational logic and context as a moat."
Most enterprises haven't begun to capture that context in a form agents can use. That's the real gap — not the model, not the framework.
@seema_amble@a16z
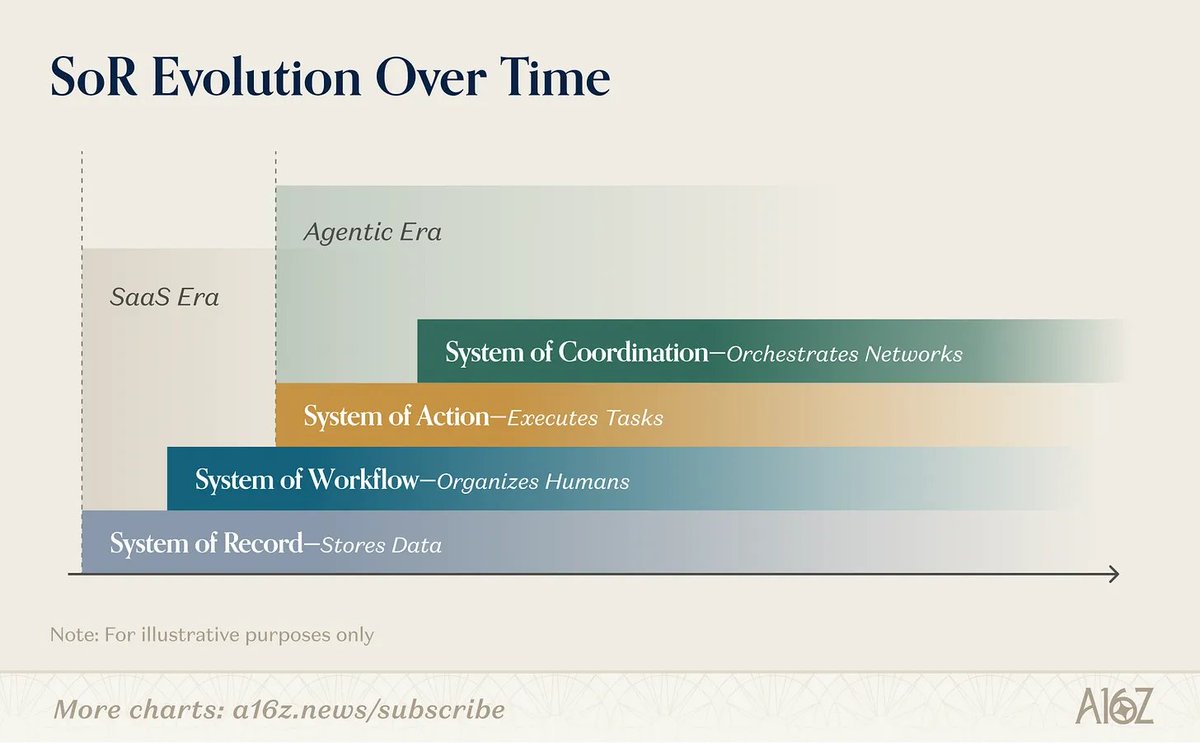
As system of record incumbents shift to headless agents, they are making an implicit bet that the data layer will remain the source of value.
Startups will compete on a new set of factors, like proprietary data, owning the action layer, real-world execution, and selling to technical buyers.
The next generation of systems of record is already starting to look agentic such that they capture the context, initiate the work, and record the data exhaust.
Full piece from a16z's Seema Amble: https://t.co/8hOj26bPuf
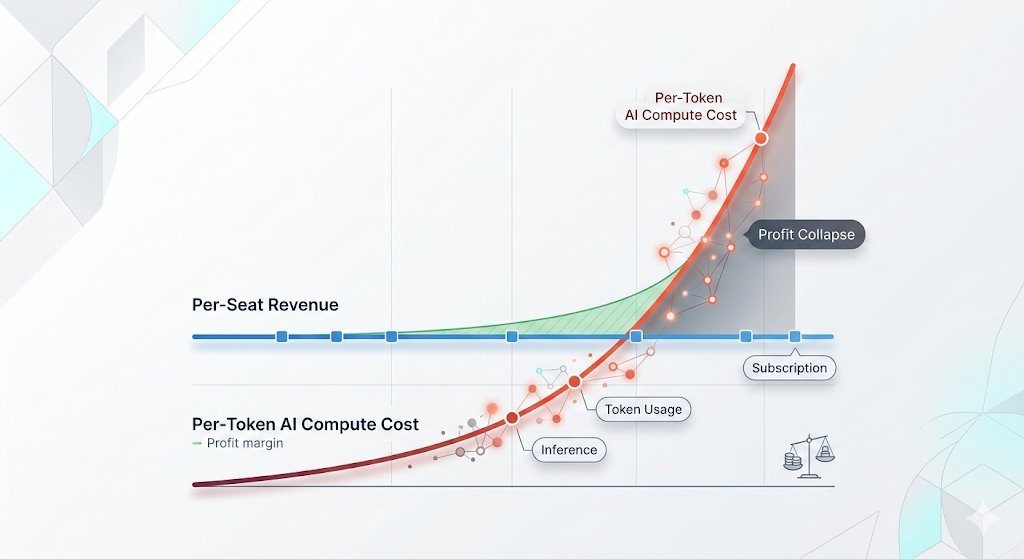
Token-based billing is breaking the bank for even the biggest tech giants. As @HedgieMarkets points out, when per-token AI compute costs skyrocket past per-seat revenue, the model simply isn’t sustainable.
The solution? Context Graph. By structuring and managing context intelligently, we can dramatically reduce token waste, optimize inference, and make AI economics work at scale without sacrificing performance. #contextgraph
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
@a16z just named the next enterprise platform fight: not the system of record, but the system of intelligence, the layer that reads context across every other system and turns it into action. CRM becomes infrastructure. Orchestration is the new gravity well.
https://t.co/aruSc7ChRL
Very true and the majority of companies still don’t get it. Building with Anthropic tools and relying solely on them means that you’re losing an important cost control lever.
This is where context graphs come in. Building AI solutions either context graphs reduces token usage by 70% while improving accuracy by more than 40%.
Token costs will become a dominant topic in enterprises going forward with AI. Just got out of a dinner with many Fortune 500 enterprise CIOs and this was the most heated topic.
A mix of strategies are being employed, but basically no one feels like they have the right solution. A mix of: figuring out how to prioritize workloads to different models, giving out access to better or worse agents by user type, setting different spend caps by team, having teams justify AI by their use-case, and some just having unfettered access.
Everyone is trying to figure out a semi/predictable model right now in a world where the underlying tech and cost models are constantly evolving.
So true @JayaGup10 the avg engineer or even a very good engineer is typically nit the right fit and the typical business consultant is not technical enough. Palantir mastered the combo and that’s a huge payoff their success. For other companies to be successful with FDEs they’ll need to find a similar path.
The FDE model is about TALENT not just deployment. McKinsey made “client service” prestigious for business generalists. Palantir made “embedded deployment” prestigious for technical generalists.
The open question of the AI era is who makes AI implementation feel like cutting edge work.
The question right now that you see so many undergrads senior year asking is “which of these places is going to be sexy to do this forward deployed work at”…..
Model selection and switching is easy. The real model issue, that most companies haven’t realized yet, is token usage and cost.
If your AI app layer is bounded by your model’s context window, then your architecture is likely sub par.
The center of gravity is shifting from the model layer to the operating layer around the model.
But inside real companies, the primary bottleneck is rarely raw model capability. It’s getting AI to operate reliably across fragmented data environments, inconsistent processes, permission structures, legacy systems, and workflows shaped as much by tacit knowledge as formal policy.
The competitive advantage is the context and operating layer that lets companies orchestrate, govern, and swap models without losing value.
The center of gravity is shifting from the model layer to the operating layer around the model.
But inside real companies, the primary bottleneck is rarely raw model capability. It’s getting AI to operate reliably across fragmented data environments, inconsistent processes, permission structures, legacy systems, and workflows shaped as much by tacit knowledge as formal policy.
The competitive advantage is the context and operating layer that lets companies orchestrate, govern, and swap models without losing value.
The Wild West phase of AI agents is ending. As @jainarvind points out, agent sprawl is a real challenge. The next big frontier in enterprise AI isn’t just about building smarter agents, it’s about orchestration, shared context, and measurable ROI.
Agent sprawl has become a real concern for many leaders I talk with. Agents are popping up across the company without shared context, clear ownership, consistent guardrails, or a reliable way to know which ones are actually creating value.
The next phase of enterprise AI will be defined less by agent creation and more by agent operations, where testing, versioning, monitoring, and governance are built into the system from the start.
At @Glean, we think about that through the Agent Development Lifecycle (ADLC). It is a practical model for how enterprises move from promising demos to agents that are grounded in the right context, launched with the right controls, and improved over time.
Alongside the ADLC, we’re announcing new product capabilities designed to support that lifecycle end-to-end: from auto-mode agents and sub-agents to agent sandbox, agent library, agent access policies, and agent insights.
In the enterprise, success won’t come from building the most agents. It will come from building agents you can trust, govern, and improve over time.
everyone talks about context quality.
Not enough people talk about the token bill.
A strong context graph means agents need fewer tokens to understand, decide, and act. That’s real margin.
https://t.co/ie9bVNcJyS’s context graph was built for exactly this: compressing enterprise context into usable intelligence.
A common trend emerging in larger enterprises is token budgeting as a major topic. As agents can do more and more long running tasks, and thus take vastly more compute, allocation of tokens across teams becomes a very real thing in the enterprise.
Companies spend a meaningful amount of time deciding how much to spend on talent, marketing campaigns, events, laptop setups, and even the cost of lunches. Tokens will be no different.
Tokens will similarly need to be excruciatingly well-managed because you’ll need to ensure you don’t blow up your budget, and you’ll need to ensure that the tokens are flowing to the highest and most useful parts of work. You don’t want to find out you burned your monthly budget on something relatively low value and then be blocked on the much higher value task later.
Doing this at large company scale is extremely hard as you have layers of abstraction on data and visibility into the digital work being done by agents in any central way. This is going to mean that agentic spend will increasingly will expand beyond the confines of the IT budget, and end up in organizational budgets like other expenses.
Ultimately team and org leaders will have to be given budgets for this, but even they don’t have adequate visibility and controls in most cases. We’ll need all new software just to solve this problem, and it’s probably an opportunity for startups in its own right.
Going to be an all new era of enterprise resource allocation, especially while we compute constrained.
great conversation indeed @jainarvind@JayaGup10 - could not agree more - context and deep associative knowledge of the specific company internal processes are a must have ingredient if you want your agentic workflows to be both autonomous and trusted.
Great conversation with @JayaGup10 on context graphs, decision traces, and where enterprise AI is headed.
The gap isn’t just about model intelligence, it’s about context.
- Enterprise work is deeply contextual, and the hardest decisions rarely follow a fixed playbook.
- Human judgment still matters, even as AI automates more of the process.
- Decision-relevant memory is becoming strategic infrastructure.
- Enterprise data, learnings, and derived memory are part of the company’s operating system and competitive advantage